现在我们的计算机都是多个核的,通俗来说就是多个处理或者计算单元。为了加快运算和处理速度,我们可以将不同的任务交给多个核心进行同时处理,从而提高了运算速度和效率,多个核心同时运作就是多个进程同时进行,这就是多进程。
创建进程和创建线程的方法基本一致,请看下面代码:
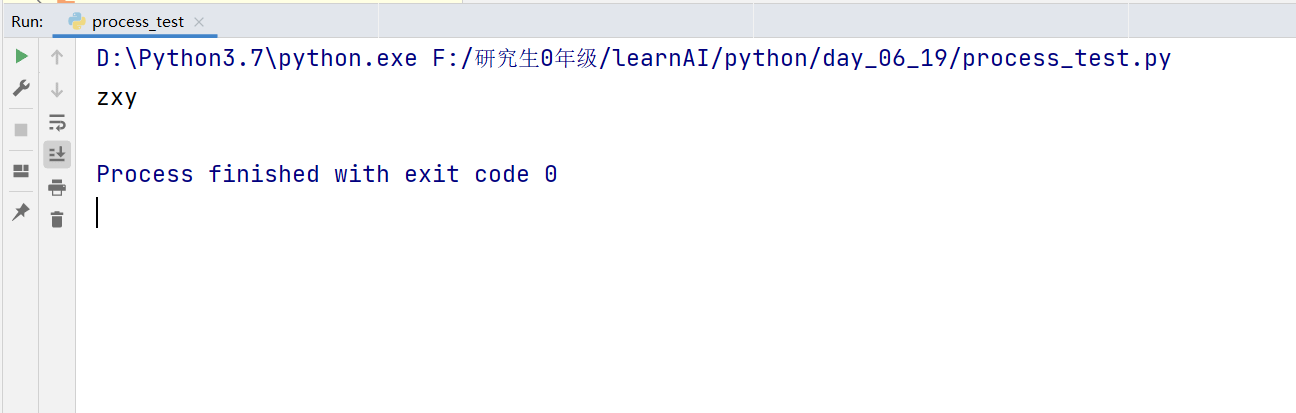
# coding:utf-8
# 导入多进程的包,并重命名为mp
import multiprocessing as mp
# 主要工作
def p1():
print("zxy")
if __name__ == "__main__":
# 创建新进程
new_process = mp.Process(target=p1, name="p1")
# 启动这个进程
new_process.start()
# 阻塞该进程
new_process.join()控制台效果图:
为什么要在多进程中使用queue呢?
因为多进程和多线程一样,在工作函数中,无法通过return返回进程函数中的结果,所以使用queue进行存储结果,要用的时候再进行取出。
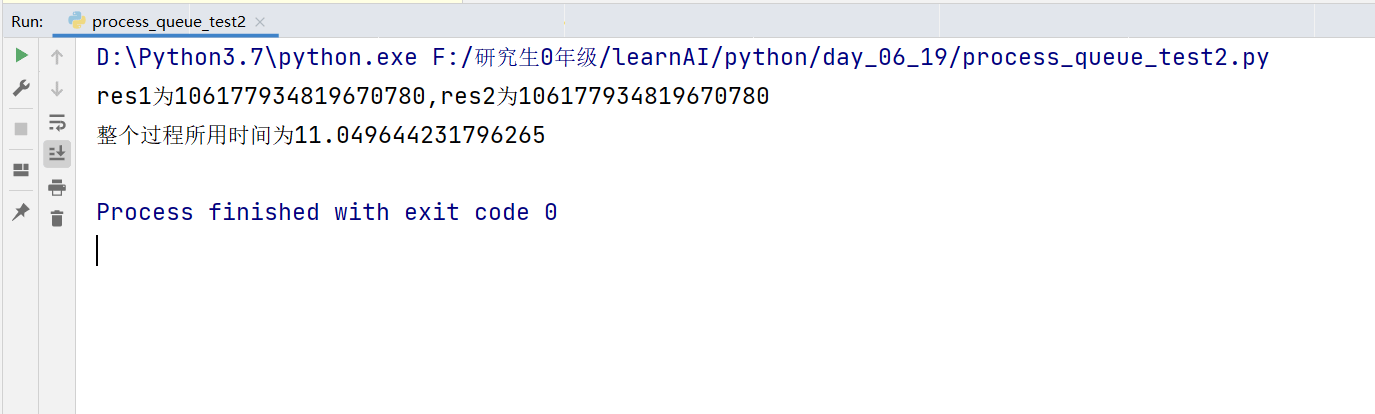
# coding:utf-8
import time
import multiprocessing as mp
"""
使用多进程时,运行程序所用的时间
"""
def job1(q):
res = 0
for i in range(100):
res += i + i**5 +i**8
time.sleep(0.1)
# 将结果放入队列中
q.put(res)
def job2(q):
res = 0
for i in range(100):
res += i + i**5 +i**8
time.sleep(0.1)
q.put(res)
if __name__ == "__main__":
start_time = time.time()
# 创建队列
q = mp.Queue()
# 创建进程1
process1 = mp.Process(target=job1, args=(q,))
# 创建进程2
process2 = mp.Process(target=job2, args=(q,))
process1.start()
process2.start()
# 通过队列获取值
res1 = q.get()
res2 = q.get()
print("res1为%d,res2为%d" % (res1, res2))
end_time = time.time()
print("整个过程所用时间为%s" %(end_time-start_time))效果图:
接下来使用多进程、多线程、以及什么都不用的普通方法进行处理,看看他们三种方法的效率如何?
# coding:utf-8
import multiprocessing as mp
import time
import threading as th
"""
多进程、多线程、普通方法的性能比较
"""
# 多进程工作
def mp_job(res):
for i in range(10000000):
res += i**5 + i**6
print(res)
# 多线程工作
def mt_job(res):
for i in range(10000000):
res += i**5 + i**6
print(res)
# 普通方法工作
def normal_job(res):
for i in range(10000000):
res += i ** 5 + i ** 6
print(res)
if __name__ == "__main__":
mp_sum = 0
mp_start = time.time()
process1 =mp.Process(target=mp_job, args=(mp_sum, ))
process2 = mp.Process(target=mp_job, args=(mp_sum,))
process1.start()
process2.start()
process1.join()
process2.join()
mp_end = time.time()
print("多进程使用时间为", (mp_end-mp_start))
mt_start = time.time()
mt_sum = 0
thread1 = th.Thread(target=mt_job, args=(mt_sum, ))
thread2 = th.Thread(target=mt_job, args=(mt_sum, ))
thread1.start()
thread2.start()
thread1.join()
thread2.join()
mt_end = time.time()
print("多线程使用的时间是", (mt_end-mt_start))
normal_start = time.time()
normal_sum = 0
# 进行两次
normal_job(normal_sum)
normal_job(normal_sum)
normal_end = time.time()
print("普通方法使用的时间是", (normal_end-normal_start))效果图:
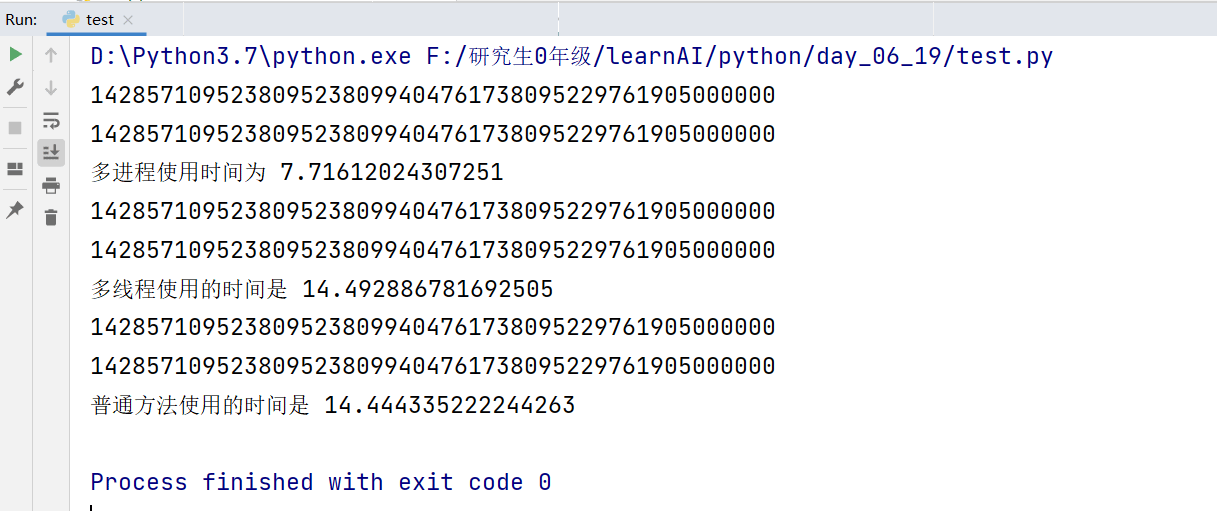
实验结果表明:多进程的效率确实高!!!
进程池是干什么用的呢?
进程池就是python的多进程提供的一个池子,将所有的进程都放在这个池子里面,让计算机自己去使用进程池中的资源,从而多进程处理一些程序,进而提高工作效率。
(1)默认使用进程池中全部进程时
# coding:utf-8
import time
import multiprocessing as mp
"""
进程池pool的使用
"""
def job(num):
time.sleep(1)
return num * num
if __name__ == "__main__":
start_time = time.time()
# 括号里面不加参数时,默认使用进程池中所有进程
pool = mp.Pool()
res = pool.map(job, range(10))
print(res)
end_time = time.time()
print("运行时间为", (end_time-start_time))效果图:

(2)指定进程池中进程数时
# coding:utf-8
import time
import multiprocessing as mp
"""
进程池pool的使用
"""
def job(num):
time.sleep(1)
return num * num
if __name__ == "__main__":
start_time = time.time()
# 括号里面加参数时,指定两个进程进行处理
pool = mp.Pool(processes=2)
res = pool.map(job, range(10))
print(res)
end_time = time.time()
print("运行时间为", (end_time-start_time))效果图:
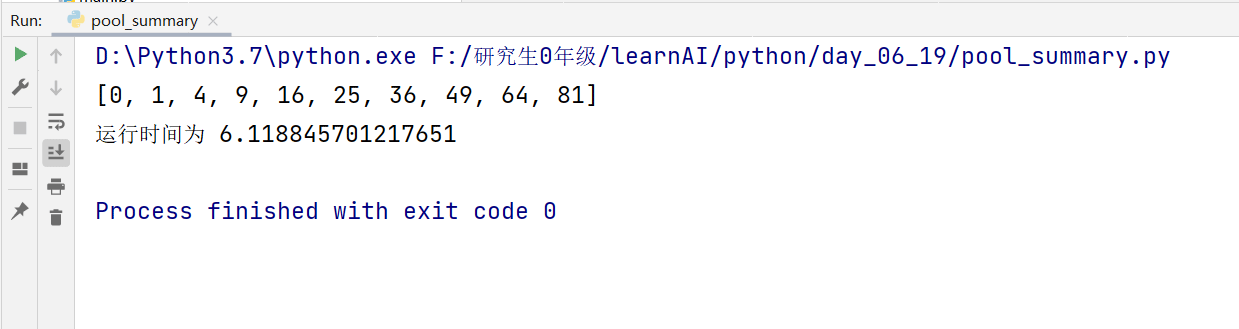
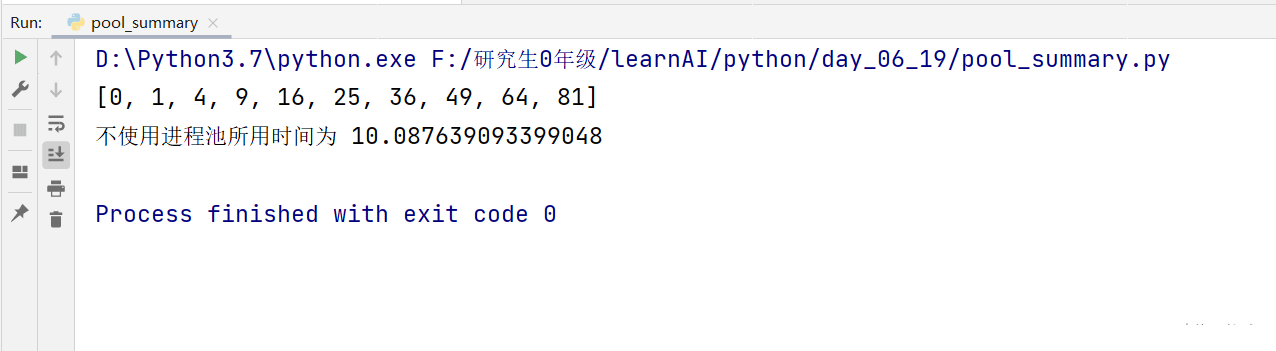
(3)不使用多进程时
# coding:utf-8
import time
def job(res):
for i in range(10):
res.append(i*i)
time.sleep(1)
if __name__ == "__main__":
start_time = time.time()
res = []
job(res)
print(res)
end_time =time.time()
print("不使用进程池所用时间为", (end_time-start_time))效果图:

实验结论:多进程处理事情,效率很高!!!核心越多,处理越快!
一个核心,我们多线程处理时,可以使用全局变量来共享数据。但是多进程之间是不行的,那我们多进程之间应该如何共享数据呢?
那就得用到共享内存了!
# coding:utf-8
import multiprocessing as mp
"""
共享内存
"""
if __name__ == "__main__":
# 第一个参数是数据类型的代码,i代表整数类型
# 第二个参数是共享数据的值
v = mp.Value("i", 0)进程锁和线程锁的用法基本一致。进程锁的诞生是为了避免多进程之间抢占共享数据,进而造成多进程之间混乱修改共享内存的局面。
(1)不加锁之前
# coding:utf-8
import multiprocessing as mp
import time
"""
进程中的锁lock
"""
def job(v, num):
for i in range(10):
v.value += num
print(v.value)
time.sleep(0.2)
if __name__ == "__main__":
# 多进程中的共享内存
v = mp.Value("i", 0)
# 进程1让共享变量每次加1
process1 = mp.Process(target=job, args=(v, 1))
# 进程2让共享变量每次加3
process2 = mp.Process(target=job, args=(v, 3))
process1.start()
process2.start()效果图:

(2)加锁之后
# coding:utf-8
import multiprocessing as mp
import time
"""
进程中的锁lock
"""
def job(v, num, l):
# 加锁
l.acquire()
for i in range(10):
v.value += num
print(v.value)
time.sleep(0.2)
# 解锁
l.release()
if __name__ == "__main__":
# 创建进程锁
l = mp.Lock()
# 多进程中的共享内存
v = mp.Value("i", 0)
process1 = mp.Process(target=job, args=(v, 1, l))
process2 = mp.Process(target=job, args=(v, 3, l))
process1.start()
process2.start()效果图: