双向RNN(Bidirectional RNN)的结构如下图所示。
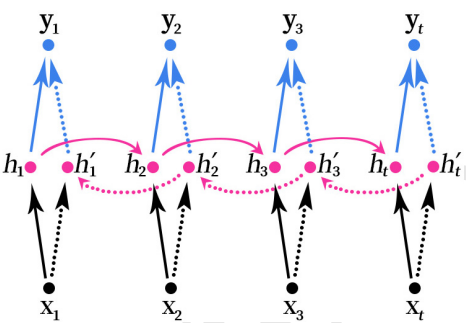
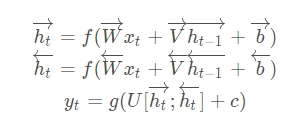

双向的 RNN 是同时考虑“过去”和“未来”的信息。上图是一个序列长度为 4 的双向RNN 结构。

双向RNN就像是我们做阅读理解的时候从头向后读一遍文章,然后又从后往前读一遍文章,然后再做题。有可能从后往前再读一遍文章的时候会有新的不一样的理解,最后模型可能会得到更好的结果。
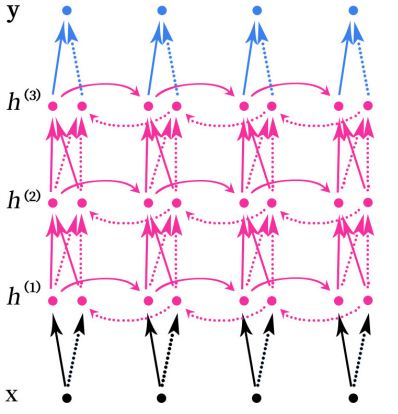
堆叠的双向RNN(Stacked Bidirectional RNN)的结构如上图所示。上图是一个堆叠了3个隐藏层的RNN网络。
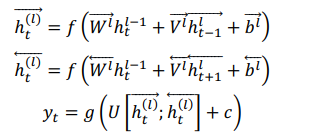
注意,这里的堆叠的双向RNN并不是只有双向的RNN才可以堆叠,其实任意的RNN都可以堆叠,如SimpleRNN、LSTM和GRU这些循环神经网络也可以进行堆叠。
堆叠指的是在RNN的结构中叠加多层,类似于BP神经网络中可以叠加多层,增加网络的非线性。
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import LSTM,Dropout,Bidirectional
from tensorflow.keras.optimizers import Adam
import matplotlib.pyplot as plt
# 载入数据集
mnist = tf.keras.datasets.mnist
# 载入数据,数据载入的时候就已经划分好训练集和测试集
# 训练集数据x_train的数据形状为(60000,28,28)
# 训练集标签y_train的数据形状为(60000)
# 测试集数据x_test的数据形状为(10000,28,28)
# 测试集标签y_test的数据形状为(10000)
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 对训练集和测试集的数据进行归一化处理,有助于提升模型训练速度
x_train, x_test = x_train / 255.0, x_test / 255.0
# 把训练集和测试集的标签转为独热编码
y_train = tf.keras.utils.to_categorical(y_train,num_classes=10)
y_test = tf.keras.utils.to_categorical(y_test,num_classes=10)
# 数据大小-一行有28个像素
input_size = 28
# 序列长度-一共有28行
time_steps = 28
# 隐藏层memory block个数
cell_size = 50
# 创建模型
# 循环神经网络的数据输入必须是3维数据
# 数据格式为(数据数量,序列长度,数据大小)
# 载入的mnist数据的格式刚好符合要求
# 注意这里的input_shape设置模型数据输入时不需要设置数据的数量
model = Sequential([
Bidirectional(LSTM(units=cell_size,input_shape=(time_steps,input_size),return_sequences=True)),
Dropout(0.2),
Bidirectional(LSTM(cell_size)),
Dropout(0.2),
# 50个memory block输出的50个值跟输出层10个神经元全连接
Dense(10,activation=tf.keras.activations.softmax)
])
# 循环神经网络的数据输入必须是3维数据
# 数据格式为(数据数量,序列长度,数据大小)
# 载入的mnist数据的格式刚好符合要求
# 注意这里的input_shape设置模型数据输入时不需要设置数据的数量
# model.add(LSTM(
# units = cell_size,
# input_shape = (time_steps,input_size),
# ))
# 50个memory block输出的50个值跟输出层10个神经元全连接
# model.add(Dense(10,activation='softmax'))
# 定义优化器
adam = Adam(lr=1e-3)
# 定义优化器,loss function,训练过程中计算准确率 使用交叉熵损失函数
model.compile(optimizer=adam,loss='categorical_crossentropy',metrics=['accuracy'])
# 训练模型
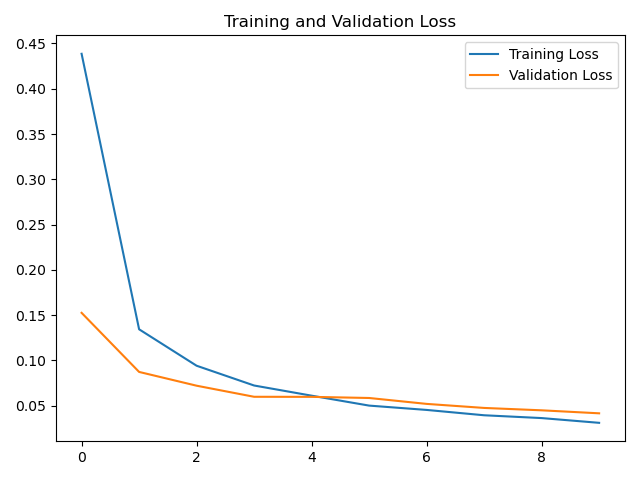
history=model.fit(x_train,y_train,batch_size=64,epochs=10,validation_data=(x_test,y_test))
#打印模型摘要
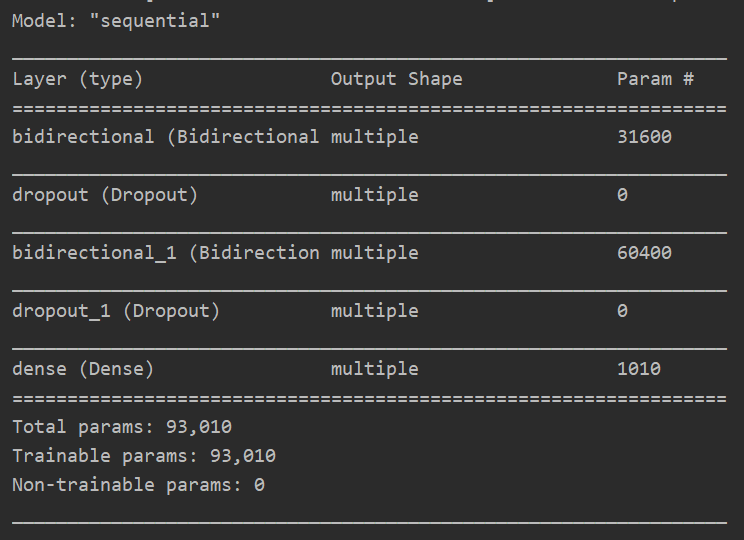
model.summary()
loss=history.history['loss']
val_loss=history.history['val_loss']
accuracy=history.history['accuracy']
val_accuracy=history.history['val_accuracy']
# 绘制loss曲线
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
# 绘制acc曲线
plt.plot(accuracy, label='Training accuracy')
plt.plot(val_accuracy, label='Validation accuracy')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
这个可能对文本数据比较容易处理,这里用这个模型有点勉强,只是简单测试下。
模型摘要:
acc曲线:

loss曲线: