线性表是一种线性结构,它是由零个或多个数据元素构成的有限序列。线性表的特征是在一个序列中,除了头尾元素,每个元素都有且只有一个直接前驱,有且只有一个直接后继,而序列头元素没有直接前驱,序列尾元素没有直接后继。
数据结构中常见的线性结构有数组、单链表、双链表、循环链表等。线性表中的元素为某种相同的抽象数据类型。可以是C语言的内置类型或结构体,也可以是C++自定义类型。
数组在实际的物理内存上也是连续存储的,数组有上界和下界。C语言中定义一个数组:
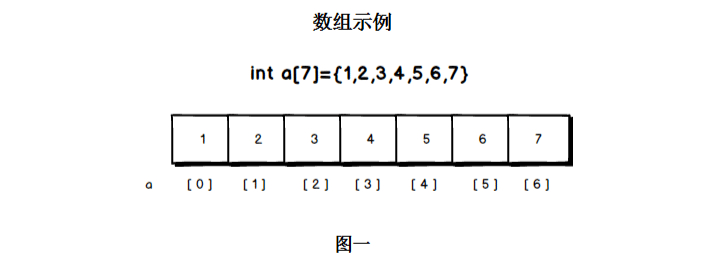
数组下标是从0开始的,a[0]对应第一个元素。其中,a[0]称为数组a的下界,a[6]称为数组a的上届。超过这个范围的下标使用数组,将造成数组越界错误。
数组的特点是:数据连续,支持快速随机访问。
数组分为固定数组与动态数组。其中固定数组的大小必须在编译时就能够确认,动态数组允许在运行时申请数组内存。复杂点的数组是多维数组,多维数组实际上也是通过一维数组来实现的。在C语言中,可以通过malloc来分配动态数组,C++使用new。另外,C++的标准模板库提供了动态数组类型vector以及内置有固定数组类型array。
Python中list可以被认为是封装好的数组。
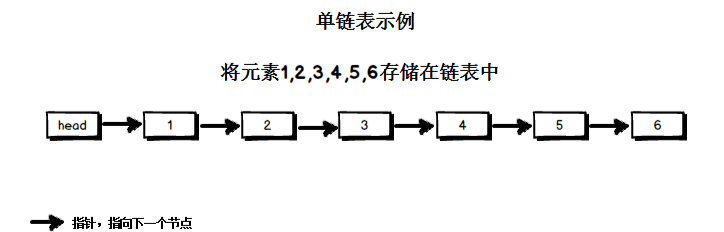
单向链表是链表的一种。链表由节点所构成,节点内含一个指向下一个节点的指针,节点依次链接成为链表。因此,链表这种数据结构通常在物理内存上是不连续的。链表的通常含有一个头节点,头节点不存放实际的值,它含有一个指针,指向存放元素的第一个节点。
class Node(): """ 单链表中的节点应该具有两个属性:val 和 next。 val 是当前节点的值, next 是指向下一个节点的指针/引用。 """ def __init__(self, value): # 存放元素数据 self.val = value # next是下一个节点的标识 self.next = None
您可以选择使用单链表或双链表。单链表中的节点应该具有两个属性:val 和 next。val 是当前节点的值,next 是指向下一个节点的指针/引用。如果要使用双向链表,则还需要一个属性 prev 以指示链表中的上一个节点。假设链表中的所有节点都是 0-index 的。
在链表类中实现这些功能:
index 个节点的值。如果索引无效,则返回-1。val 的节点。插入后,新节点将成为链表的第一个节点。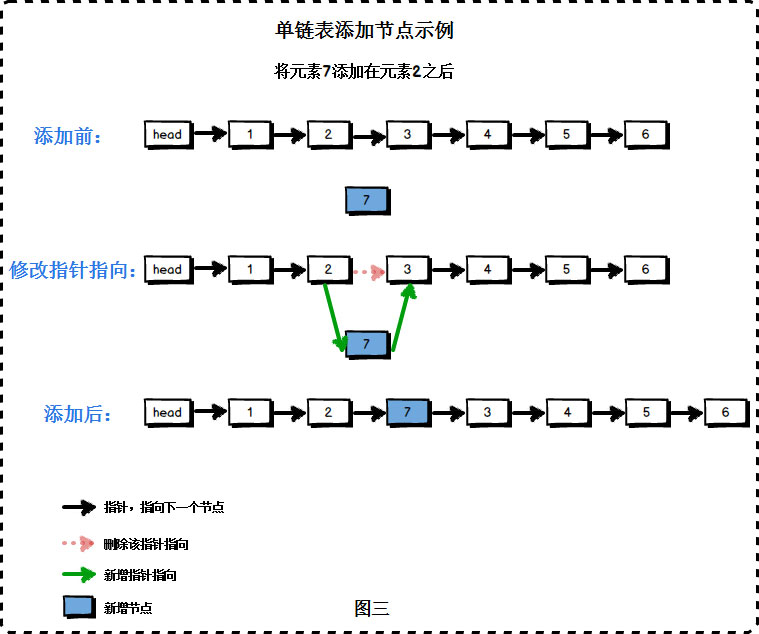
val 的节点追加到链表的最后一个元素。index 个节点之前添加值为 val 的节点。如果 index 等于链表的长度,则该节点将附加到链表的末尾。如果 index 大于链表长度,则不会插入节点。index 有效,则删除链表中的第 index 个节点。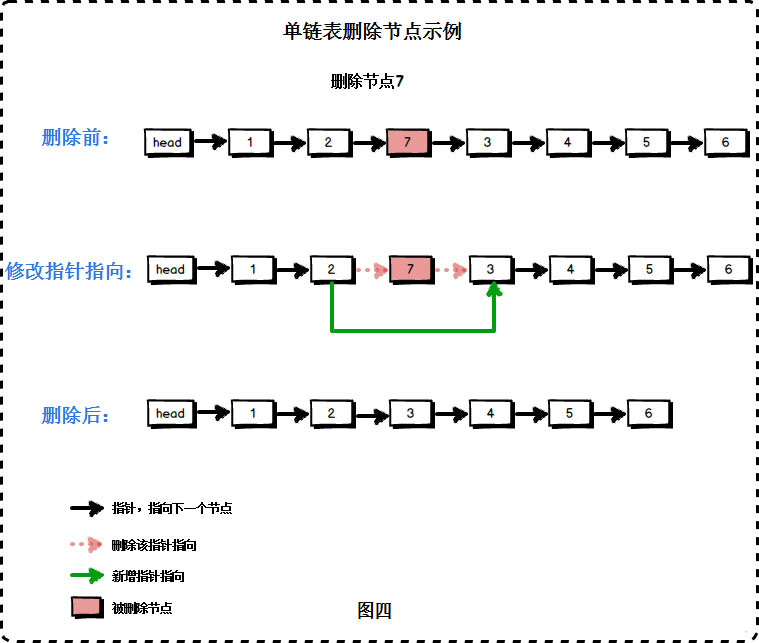
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@Author : Young
@File : linked_list2.py
@version : 1.0
@Time : 2019/4/5 11:06
Description about this file:
"""
class Node():
"""
单链表中的节点应该具有两个属性:val 和 next。
val 是当前节点的值,
next 是指向下一个节点的指针/引用。
"""
def __init__(self, value):
# 存放元素数据
self.val = value
# next是下一个节点的标识
self.next = None
class SingleLinkList():
def __init__(self, node=None):
# 头节点定义为私有变量
self._head = node
def is_empty(self):
# 判断链表是否为空
if self._head is None:
return True
else:
return False
def get(self, index: int) -> int:
"""
获取链表中第 index 个节点的值。如果索引无效,则返回-1
:param index: 索引值
:return:
"""
if self._head is None:
return -1
cur = self._head
for i in range(index):
if cur.next is None:
return -1
cur = cur.next
return cur.val
def length(self):
"""
cur游标,用来移动遍历节点
count用来计数
:return: 返回链表的长度
"""
cur = self._head
count = 0
while cur is not None:
count += 1
cur = cur.next
return count
def travel(self):
"""
遍历整个链表
:return:
"""
cur = self._head
while cur is not None:
print(cur.elem, end=' ')
cur = cur.next
def add_at_head(self, val: int) -> None:
"""
在头部添加一个节点
:param val:
:return: None
"""
# 先创建一个保存item值的节点
node = Node(val)
# 判断链表是否为空
if self._head is None:
self._head = node
else:
# 将新节点的链接域next指向头节点,即_head指向的位置
node.next = self._head
# 将链表的头_head指向新节点
self._head = node
def add_at_tail(self, val: int) -> None or int:
"""
在尾部添加一个节点
:param item:
:return:
"""
node = Node(val)
# 若链表为空,直接将该节点作为链表的第一个元素
if self._head is None:
self._head = node
else:
cur = self._head
while cur.next is not None:
cur = cur.next
cur.next = node
def add_at_index(self, index: int, val: int) -> None:
"""
在指定位置pos添加节点
pos从0开始
:param index:
:param val:
:return:
"""
# 若指定位置pos为第一个元素之前,则执行头部插入
if index <= 0:
self.add_at_head(val)
# 若指定位置超过链表尾部,则执行尾部插入
elif index >= self.length():
self.add_at_tail(val)
# 找到指定位置
else:
# pre用来指向指定位置pos的前一个位置pos-1,初始从头节点开始移动到指定位置
pre = self._head
count = 0
node = Node(val)
# 在目标节点的前一位停下
while count < (index - 1):
count += 1
pre = pre.next
# 先将新节点node的next指向插入位置的节点
node.next = pre.next
# 将插入位置的前一个节点的next指向新节点
pre.next = node
def delete_at_index(self, index: int) -> None or int:
"""
如果索引 index 有效,则删除链表中的第 index 个节点。
:param index: 对应的索引值
:return: -1表示为异常
"""
pre = None
cur = self._head
if index is 0:
self._head = None
for i in range(index):
if cur.next is None:
# raise IndexError("越界")
return -1
pre = cur
cur = pre.next
else:
pre.next = cur.next
def search(self, val: int) -> True or False:
"""
查找节点是否存在
:param val: 节点的val值
:return:
"""
cur = self._head
while cur is not None:
if cur.val == val:
return True
else:
cur = cur.next
return False
if __name__ == '__main__':
obj = SingleLinkList()
obj.add_at_head(1)
obj.add_at_tail(3)
obj.add_at_index(1, 2)
obj.travel()
obj.delete_at_index(1)
obj.travel()链表失去了顺序表随机读取的优点,同时链表由于增加了结点的指针域,空间开销比较大,但对存储空间的使用要相对灵活。
链表与顺序表的各种操作复杂度如下所示:
操作 | 链表 | 顺序表 |
访问元素 | O(n) | O(1) |
在头部插入/删除 | O(1) | O(n) |
在尾部插入/删除 | O(n) | O(1) |
在中间插入/删除 | O(n) | O(n) |

