Redis在项目中进行广泛使用,那么在日常的开发过程中,我们在使用Redis的过程中需要注意那些呢?本文将从三个维度来讲解如何进行Redis的优化。
key的一般都是采用字符串,而字符串的底层数据结构为SDS,SDS 结构中会包含字符串长度、分配空间大小等元数据信息,当key字符串的长度增加时,SDS中的元数据也会占用更多内存空间,为了减少key的占用空间,我们可用根据业务名来使用相应的英文缩写来表示。例如user用u表示,message 用m来表示。
我们既要注意key的长度,同时也需要关注value的大小,Redis是使用单线程读写数据,bigkey 的读写操作会阻塞线程,降低Redis的处理效率。
我们可以通过--bigkey的命令来查看Redis中所占用的bigkey的信息,具体的命令如下:
redis-cli -h 127.0.0.1 -p 6379 -a 'xxx' --bigkeys
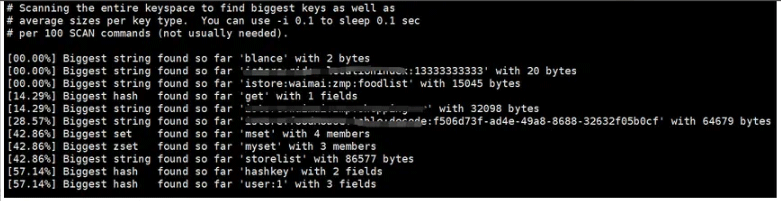
从上述图所示,我们可以查看到Redis中的key占用了32098个bytes,需要进行相关优化的。
建议:
Redis提供了丰富的数据类型,对于存放的内存也做了相关优化。关乎数据结果的相关知识,可以参考之前的文章。
例如:String和set在存储int数据时,会采用整数编码存储。Hash、ZSet在元素数量比较少时,会采用压缩列表(ziplist)存储,在存储比较多的数据时,才会转换为哈希表和跳表。
Redis中的字符串都是使用二进制安全的字节数组来保存的,所以我们可以把业务的序列化成二进制写入Redis,但是采用不同的序列化,所占用的空间大少不一样。比如使用protostuff的序列化比java内置的序列化效率更高,占用空间更少。针对json和xml数据格式的,可以采用gzip或者snappy算法对数据进行压缩存储,从而节省空间。
我们根据业务的数据量提前预估内存大小,从而避免Redis的内存持续膨胀,导致占用过多资源。
关于如何设置淘汰策略,需要集合实际的业务特性来选择:
Redis单实例的内存大小建议设置在2~6GB之间。因为无论是RDB快照,还是主从集群进行数据同步,都能很快完成,不会阻塞正常请求的处理。
频繁的新增修改会导致内存碎片的增多,因此需要及时清理内存碎片。
Redis提供了Info memory命令可以查看内存使用信息,具体如下:
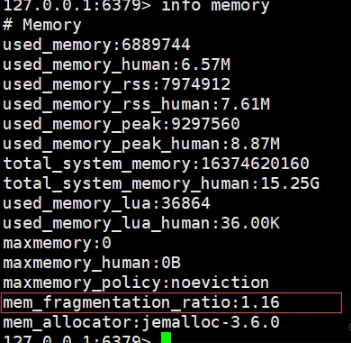
说明:
我们需要在线上要禁用这些命令。具体的做法是,管理员采用rename-command命令在配置文件中对这些命令进行重命名,让客户端无法使用这些命令。
对于集合类型的来说,在未清楚集合数据大小的情况下,慎用查询集合中的全量数据,例如Hash的HetALL、Set的SMEMBERS命令、LRANGE key 0 -1 或者ZRANGE key 0 -1等命令,因为这些命令会对Hash或者Set类型的底层数据进行全量扫描,当集合数据量比较大时,会阻塞Redis的主线程。
优化建议:
当元素数据量较多时,可以用SSCAN、HSCAN 命令分批返回集合中的数据,减少对主线程的阻塞。
Redis执行复杂度过高的命令,会消耗更多的 CPU 资源,导致主线程中的其它请求只能等待。常见的复杂命令如下:SORT、SINTER、SINTERSTORE、ZUNIONSTORE、ZINTERSTORE 等聚合类命令。
优化建议:
当需要执行排序、交集、并集操作时,可以在客户端完成,避免让Redis进行过多计算,从而影响Redis性能。
Redis通常用于保存热数据。热数据一般都有使用的时效性。所以,在数据保存时,根据业务使用数据的时长,合理的设置数据的过期时间。否则写入Redis的数据会一直占用内存,如果数据持续增增长,会达到机器的内存上限,造成内存溢出,导致服务崩溃。
当我们需要一次性操作多个key时,可以使用批量命令来处理,批量命令可以减少客户端与服务端的来回网络IO次数。
redisTemplate.executePipelined(new RedisCallback<String>() {
@Override
public String doInRedis(RedisConnection connection) throws DataAccessException {
for (int i = 0; i < 5; i++)
{
connection.set(("test:" + i).getBytes(), "test".getBytes());
}
return null;
}
});不同的业务线来部署 Redis 实例,这样当其中一个实例发生故障时,不会影响到其它业务。
业务上根据实际情况采用主从、哨兵、集群方案,避免单点故障,影响业务的正常使用。
针对主从环境,我们需要合理设置相关参数,具体内容如下:
本文对于Redis的如何优化从内存、性能、高可用等三个维度进行了详细的讲解,如有大家还有什么优化建议欢迎提出,大家共同学习,共同进步。

