为什么要考虑隔离级别?
因为事务要并发执行,而并发执行可能会出现一些问题:脏读、不可重复读和虚读,有的是允许出现的,有的不允许出现,对于这种不同程度上的出现或不出现的并发控制才有了不同的隔离级别。
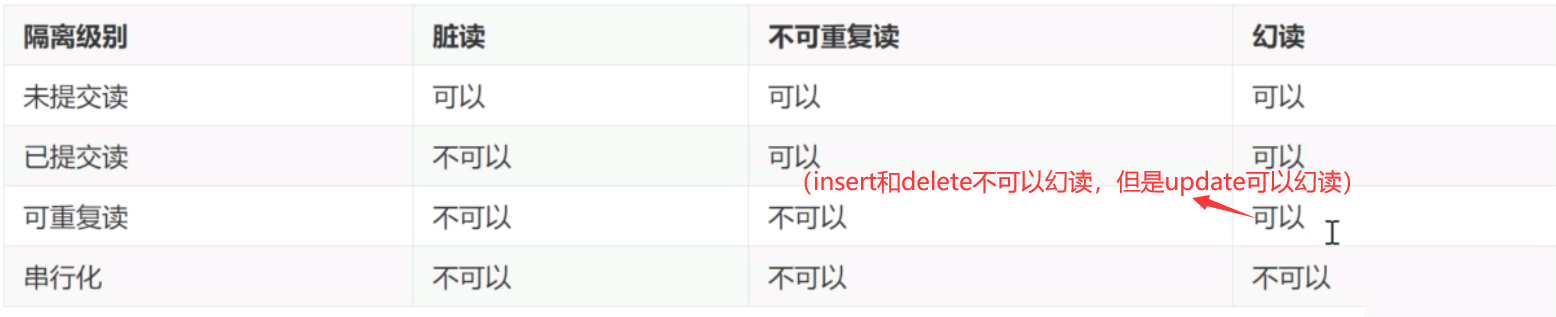
MySQL支持的四种隔离级别是:
注意:
事务隔离级别越高,为避免冲突所花费的性能也就越多,即效率低。在“可重复读”级别,实际上可以解决部分的虚读问题,但是不能防止update更新产生的虚读问题,要禁止虚读产生,还是需要设置串行化隔离级别。
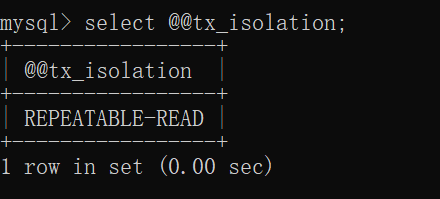
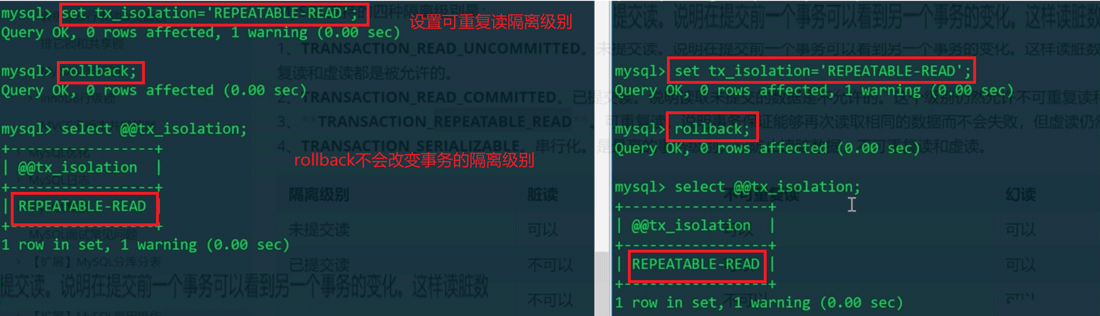
MySQL客户端默认工作在可重复读级别:

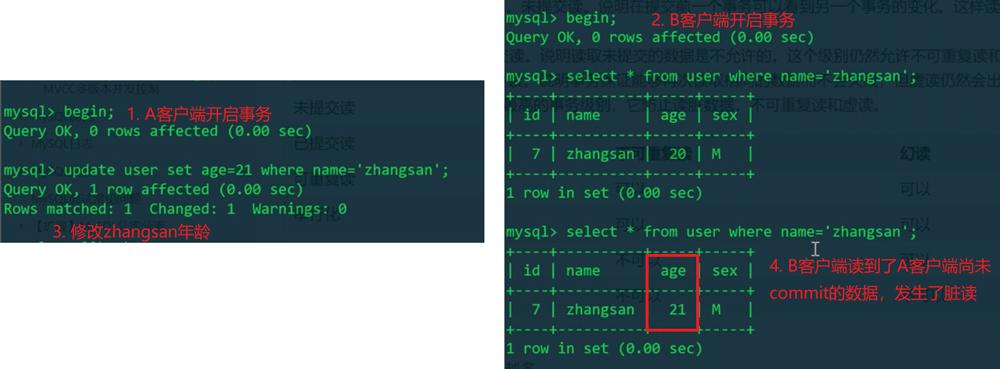
若此时A客户端rollback,数据库中zhangsan的年龄恢复到了20,这时候已经来不及了,因为B客户端已经拿着21去做业务了。

两个客户端都rollback放弃对当前事务对数据做的修改,zhangsan年龄恢复为20
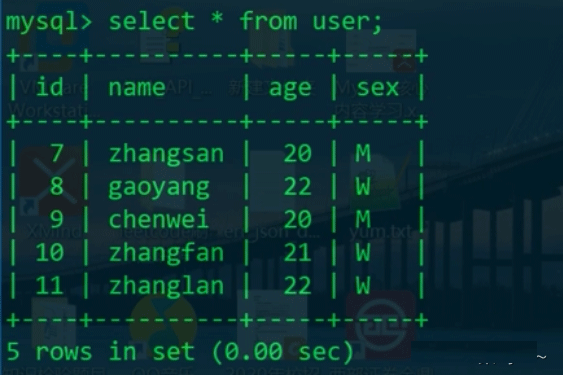

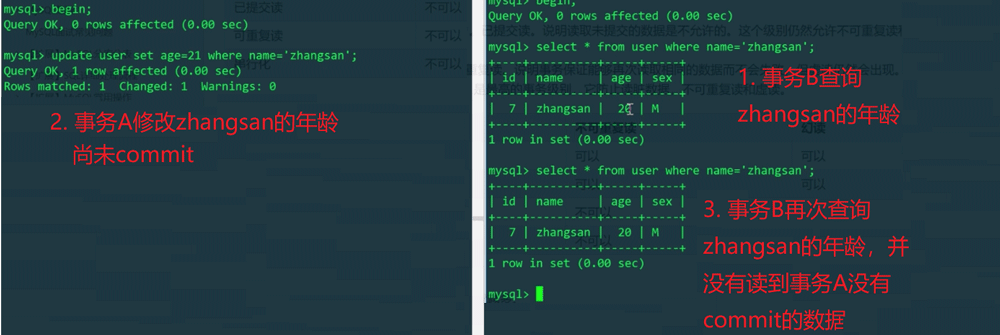
因为设置了已提交读隔离级别,所以事务B并没有发生脏读,这是由各种锁机制以及事务并发的MVCC版本控制实现的。

查询到了已经commit的数据,发生了不可重复读,这在已提交读隔离级别是允许发生的。既然发生了不可重复读,幻读就肯定可以发生了。
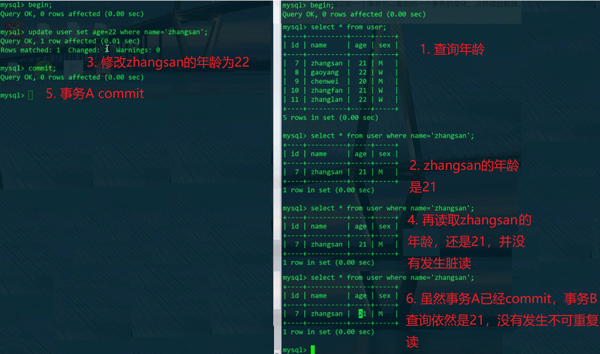
可重复读在一定意义上可以防止幻读的出现,可以看到,当前的可重复读隔离级别,防止了insert。其实可重复读隔离级别可以防止insert和delete,不能防止update。
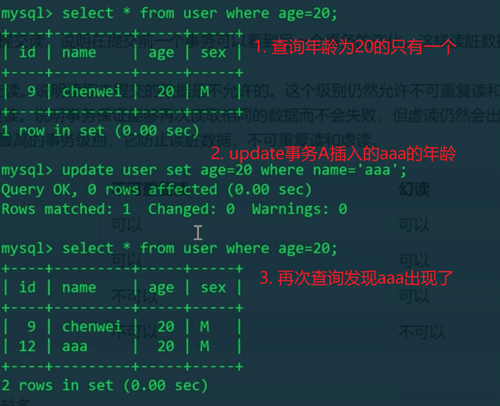
实际上,事务A已经插入并且提交了,aaa已经存在,因为事务B update aaa的年龄成功了
前后两次同样的查询,后一次查询与前一次查询的数据量不同,就发生了幻读。也就是可重复读隔离级别下,并没有解决幻读的问题,要彻底解决幻读,就需要设置串行化隔离级别

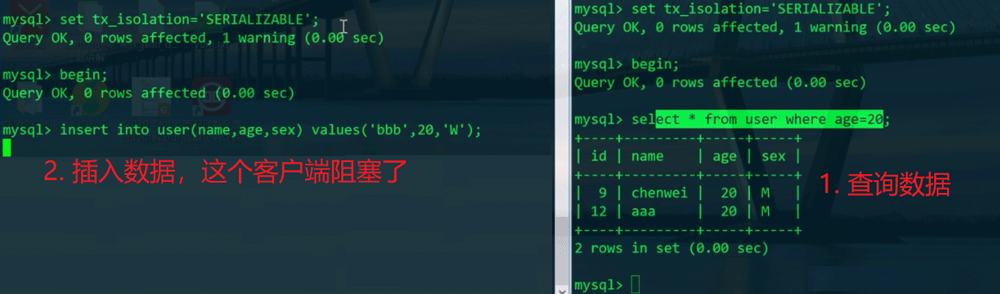
从现象看,串行化可以解决幻读,同样的条件进行查询,在另一个表里面插入数据时就被阻塞,由于事务B正在读数据,此时事务A再写数据就被阻塞了(用读写锁实现,允许读读,不允许读写或者写写)
MySQL server不会让自己执行事务的线程永远阻塞,导致当前线程占用的锁无法释放,而使得其他执行事务的线程也无法获得锁而永远阻塞。所以执行事务的线程都是带有时间的,当线程等待时间过长时,会让超时线程释放锁,并会返回一个错误:


