嗨嗨,大家好呀 ~ 今天给你们分享一个有趣的东西 ~
是一个语音识别跟语音转文字的小工具
感兴趣的朋友可以继续往下滑咯

在1.2官网注册后拿到APISecret和APIKey,
直接复制文章2.4demo代码,
保存为online_tts.py,
在命令行执行
python online_tts.py -client_secret=你的client_secret -client_id=你的client_id -file_save_path=test.wav --text=今天天气不错
Python调用标贝科技语音合成接口,实现文字转语音
Python 3
标贝科技 https://ai.data-baker.com/#/?source=qwer12
1.2.1 登录
点击产品地址进行登录,支持短信、密码、微信三种方式登录。
1.2.2 创建新应用
登录后进入【首页概览】,
各位开发者可以进行创建多个应用。
包括一句话识别、长语音识别、录音文件识别;
在线合成、离线合成、长文本合成。

1.2.3 选择服务
进入【已创建的应用】,左侧选择您需调用的AI技术服务,右侧展示对应服务页面概览(您可查询用量、管理套餐、购买服务量、自主获取授权、预警管理)。

1.2.4 获取Key&Secret
通过服务 / 授权管理,获取对应参数,
进行开发配置
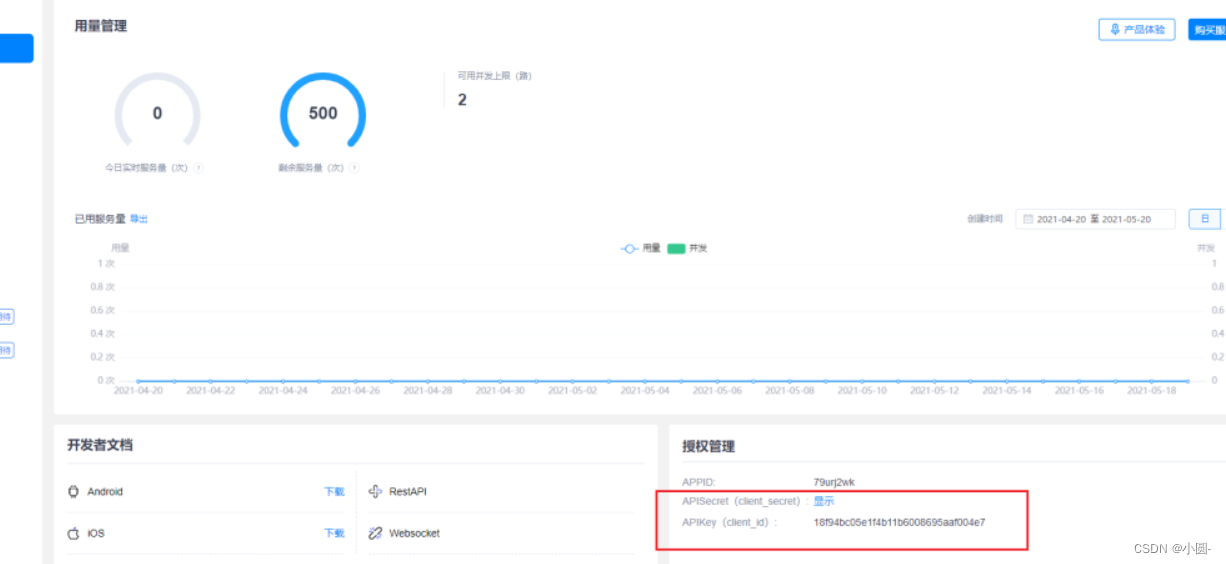
拿到Key和Secret就可以正式使用啦!
在拿到Key和Secret后,
我们还需要调用授权接口获取access_token,
这个access_token有效时长是24小时。
需要源码、教程,或者是自己有关python不懂的问题,都可以来这里哦 https://jq.qq.com/?_wv=1027&k=xJU8WKpY 这里还有学习资料与免费课程领取
# 获取access_token用于鉴权
def get_access_token(client_secret, client_id):
grant_type = "client_credentials"
url = "https://openapi.data-baker.com/oauth/2.0/token?grant_type={}&client_secret={}&client_id={}".format(grant_type, client_secret, client_id)
response = requests.post(url)
access_token = json.loads(response.text).get('access_token')
return access_token
拿到access_token后,
调用语音合成接口,
就可以获得生成的音频
# 获取转换后音频
def get_audio(data):
url = "https://openapi.data-baker.com/tts?access_token={}&domain={}&language={}&voice_name={}&text={}&audiotype={}".format(data['access_domain'], data['domain'], data['language'], data['voice_name'], data['text'], data['audiotype'])
response = requests.post(url)
content_type = response.headers['Content-Type']
if 'audio' not in content_type:
raise Exception(response.text)
return response.content
client_secret和client_id:在文章1.2的官网获取,必填
file_save_path:文件保存路径,必填
text:需要转换的文本内容
audiotype:音频类型,默认16K采样率wav格式
domain:所属领域,默认1
language:合成后文本语言,默认中文“zh"
voice_name:发音人选择,默认“Lingling",
# 获取命令行输入参数
def get_args():
text = '欢迎使用标贝开发平台。'
parser = argparse.ArgumentParser(description='ASR')
parser.add_argument('-client_secret', type=str, required=True)
parser.add_argument('-client_id', type=str, required=True)
parser.add_argument('-file_save_path', type=str, required=True)
parser.add_argument('--text', type=str, default=text)
parser.add_argument('--audiotype', type=str, default='6')
parser.add_argument('--domain', type=str, default='1')
parser.add_argument('--language', type=str, default='zh')
parser.add_argument('--voice_name', type=str, default='Lingling')
args = parser.parse_args()
return args

#!/usr/bin/env python
# coding: utf-8
import requests
import json
import argparse
# 获取access_token用于鉴权
def get_access_token(client_secret, client_id):
grant_type = "client_credentials"
url = "https://openapi.data-baker.com/oauth/2.0/token?grant_type={}&client_secret={}&client_id={}".format(grant_type, client_secret, client_id)
response = requests.post(url)
access_token = json.loads(response.text).get('access_token')
return access_token
# 获取转换后音频
def get_audio(data):
url = "https://openapi.data-baker.com/tts?access_token={}&domain={}&language={}&voice_name={}&text={}&audiotype={}".format(data['access_domain'], data['domain'], data['language'], data['voice_name'], data['text'], data['audiotype'])
response = requests.post(url)
content_type = response.headers['Content-Type']
if 'audio' not in content_type:
raise Exception(response.text)
return response.content
# 获取命令行输入参数
def get_args():
text = '欢迎使用标贝开发平台。'
parser = argparse.ArgumentParser(description='ASR')
parser.add_argument('-client_secret', type=str, required=True)
parser.add_argument('-client_id', type=str, required=True)
parser.add_argument('-file_save_path', type=str, required=True)
parser.add_argument('--text', type=str, default=text)
parser.add_argument('--audiotype', type=str, default='6')
parser.add_argument('--domain', type=str, default='1')
parser.add_argument('--language', type=str, default='zh')
parser.add_argument('--voice_name', type=str, default='Lingling')
args = parser.parse_args()
return args
if __name__ == '__main__':
try:
args = get_args()
# 获取access_token
client_secret = args.client_secret
client_id = args.client_id
access_token = get_access_token(client_secret, client_id)
# 读取参数
audiotype = args.audiotype
domain = args.domain
language = args.language
voice_name = args.voice_name
text = args.text
data = {'access_domain': access_token, 'audiotype': audiotype, 'domain': domain, 'language': language,
'voice_name': voice_name, 'text': text}
content = get_audio(data)
#保存音频文件
with open('test.wav', 'wb') as audio:
audio.write(content)
print("task finished successfully")
except Exception as e:
print(e)复制所有代码,保存为online_tts.py,在命令行执行
python online_tts.py -client_secret=你的client_secret -client_id=你的client_id -file_save_path=test.wav --text=今天天气不错

