在布尔索引中,我们将根据 DataFrame 中数据的实际值而不是它们的行/列标签或整数位置来选择数据子集。在布尔索引中,我们使用布尔向量来过滤数据。
布尔索引是一种使用 DataFrame 中数据的实际值的索引。在布尔索引中,我们可以通过四种方式过滤数据:
为了访问具有布尔索引的数据帧,我们必须创建一个数据帧,其中数据帧的索引包含一个布尔值,即“真”或“假”。
例子
# importing pandas as pd
import pandas as pd
# 列表字典
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
df = pd.DataFrame(dict, index = [True, False, True, False])
print(df)
输出:

现在我们已经创建了一个带有布尔索引的数据框,之后用户可以在布尔索引的帮助下访问数据框。用户可以使用 .loc[]、.iloc[]、.ix[] 三个函数访问数据帧
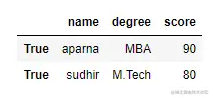
为了使用 .loc[] 访问具有布尔索引的数据帧,我们只需在 .loc[] 函数中传递一个布尔值(True 或 False)。
# importing pandas as pd
import pandas as pd
# 列表字典
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
# 使用布尔索引创建数据框
df = pd.DataFrame(dict, index = [True, False, True, False])
# 使用 .loc[] 函数访问数据框
print(df.loc[True])
输出:
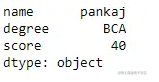
为了使用 .iloc[] 访问数据帧,我们必须传递一个布尔值(True 或 False),但 iloc[] 函数只接受整数作为参数,因此它会抛出错误,因此我们只能在我们访问数据帧时访问在 iloc[] 函数中传递一个整数
代码#1:
# importing pandas as pd
import pandas as pd
# 列表字典
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
# 使用布尔索引创建数据框
df = pd.DataFrame(dict, index = [True, False, True, False])
# 使用 .iloc[] 函数访问数据帧
print(df.iloc[True])
输出:
TypeError
代码#2:
# importing pandas as pd
import pandas as pd
# 列表字典
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
# 使用布尔索引创建数据框
df = pd.DataFrame(dict, index = [True, False, True, False])
# 使用 .iloc[] 函数访问数据帧
print(df.iloc[1])
输出:
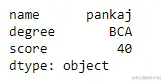
为了使用 .ix[] 访问数据帧,我们必须将布尔值(True 或 False)和整数值传递给 .ix[] 函数,因为我们知道 .ix[] 函数是 .loc[] 的混合体和 .iloc[] 函数。
代码#1:
# importing pandas as pd
import pandas as pd
# 列表字典
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
# 使用布尔索引创建数据框
df = pd.DataFrame(dict, index = [True, False, True, False])
# 使用 .ix[] 函数访问数据帧
print(df.ix[True])
输出:

代码#2:
# importing pandas as pd
import pandas as pd
# 列表字典
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
# 使用布尔索引创建数据框
df = pd.DataFrame(dict, index = [True, False, True, False])
# 使用 .ix[] 函数访问数据帧
print(df.ix[1])
输出:
在数据框中,我们可以应用布尔掩码。为此,我们可以使用 getitems 或 [] 访问器。我们可以通过给出与数据帧中包含的长度相同的 True 和 False 列表来应用布尔掩码。当我们应用布尔掩码时,它将仅打印我们传递布尔值 True 的数据帧。
代码#1:
# importing pandas as pd
import pandas as pd
# 列表字典
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
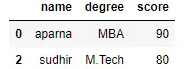
df = pd.DataFrame(dict, index = [0, 1, 2, 3])
print(df[[True, False, True, False]])
输出:
代码#2:
# importing pandas package
import pandas as pd
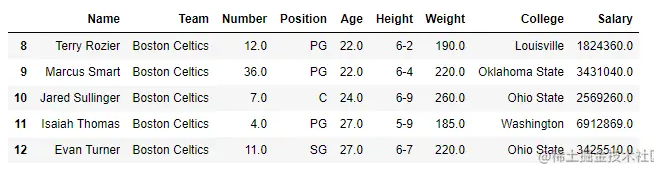
# 从csv文件制作数据框
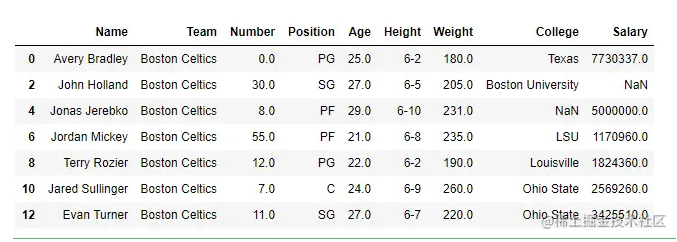
data = pd.read_csv("nba1.1.csv")
df = pd.DataFrame(data, index = [0, 1, 2, 3, 4, 5, 6,
7, 8, 9, 10, 11, 12])
print(df[[True, False, True, False, True,
False, True, False, True, False,
True, False, True]])输出:
在数据框中,我们可以根据列值过滤数据。为了过滤数据,我们可以使用不同的运算符对数据框应用某些条件,例如 ==、>、<、<=、>=。当我们将这些运算符应用于数据帧时,它会产生一系列真假。
代码#1:
# importing pandas as pd
import pandas as pd
# 列表字典
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["BCA", "BCA", "M.Tech", "BCA"],
'score':[90, 40, 80, 98]}
# 创建数据框
df = pd.DataFrame(dict)
# 使用比较运算符过滤数据
print(df['degree'] == 'BCA')
输出:

代码#2:
# importing pandas package
import pandas as pd
# 从csv文件制作数据框
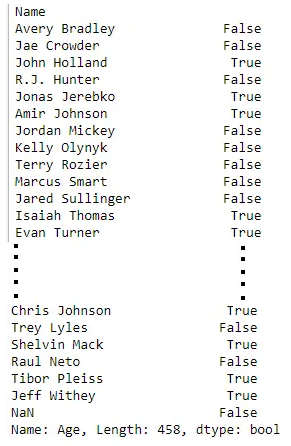
data = pd.read_csv("nba.csv", index_col ="Name")
# 使用大于运算符过滤数据
print(data['Age'] > 25)
输出:
根据索引值屏蔽数据:
在数据框中,我们可以根据列值过滤数据。为了过滤数据,我们可以使用 ==、>、< 等不同的运算符根据索引值创建掩码。
代码#1:
# importing pandas as pd
import pandas as pd
# 列表字典
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["BCA", "BCA", "M.Tech", "BCA"],
'score':[90, 40, 80, 98]}
df = pd.DataFrame(dict, index = [0, 1, 2, 3])
mask = df.index == 0
print(df[mask])
输出:

代码#2:
# importing pandas package
import pandas as pd
# 从csv文件制作数据框
data = pd.read_csv("nba1.1.csv")
# 为数据框提供索引
df = pd.DataFrame(data, index = [0, 1, 2, 3, 4, 5, 6,
7, 8, 9, 10, 11, 12])
# 根据索引值过滤数据
mask = df.index > 7
print(df[mask])
输出: