一、产生的背景
二叉查找树的查找时间复杂度是O(logN),整体的查询效率已经足够高了,那么为什么还会有B树和B+树的进化演进呢? 主要的原因是:二叉树可能会退化成一个线性树,造成磁盘IO次数增高的问题,当有大量的数据存储的时候,二叉查找树查询不能将所有的数据加载到内存中,只能逐一加载磁盘页,每个磁盘对应树的节点,造成大量的磁盘IO操作(最坏的情况IO次数为树的高度),平衡二叉树由于树深度过大而造成磁盘IO读写过于频繁,进而导致效率低下。所以,为了减少磁的IO的次数,必须降低树的深度,将瘦高的树变得矮胖。
1.1 进化要求
二、B-tree
B-Tree是一种多叉的平衡搜索树(并不一定是二叉的),以一个三阶B-tree为例子来分析,每个储存块都包含:关键字和指向孩子结点的指针,最多有M个孩子,M的大小主要取决于每个存储块的容量和数据库的配置,M表示M阶数的意思。
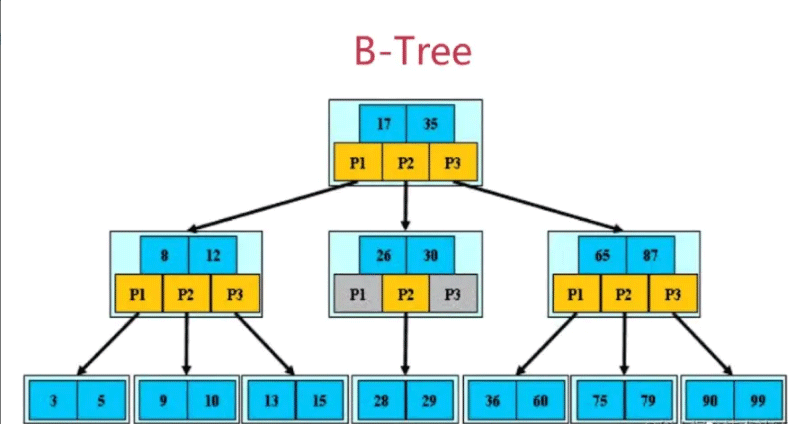
2.1 B-tree特性
- 根节点至少包括两个孩子,范围是[2,M];
- 树中每个节点最多包含M阶数个孩子(M是阶数,3阶,即:每个节点最多包含3个孩子);
- 除了根节点和叶子结点以外,其他每个节点至少有
ceil(M/2)个孩子节点,ceil是取上限函数(M是阶数,3阶,即:每个节点至少有2个孩子); - 所有的叶子结点都位于同一层。
假设每个非叶子节点包含n个关键字信息,其中:
- Ki(i=1,2..,n)为关键字,且关键字按顺序升序排序
K(i-1)< Ki; - 关键字的个数n必须满足:
[ceil(m/2)-1]<=n<=m-1(非叶子结点的关键字 = 指向孩子的指针个数-1); - 非叶子结点的指针:P[1],P[2],...,P[M];其中P[1]指向关键字小于K[1]的子树(即:3和5均小于8),P[M]指向关键字大于K[M-1]的子树(即:13和15均大于12),其他P[i]指向关键字属于
(K[i-1],K[i])的子树,是开区间(即:9和10都处于8-12区间);
假设需要查询数据15,查询步骤:
- 首先从根部开始找,15<17,往左边P1找,P1指向的子树关键字为8和12;
- 由于15比8和12都大,因此会找到P3;
- P3指向了13和15,13<15,最终找到15;
- 查找的时间复杂度为O(logN)。
三、B+tree
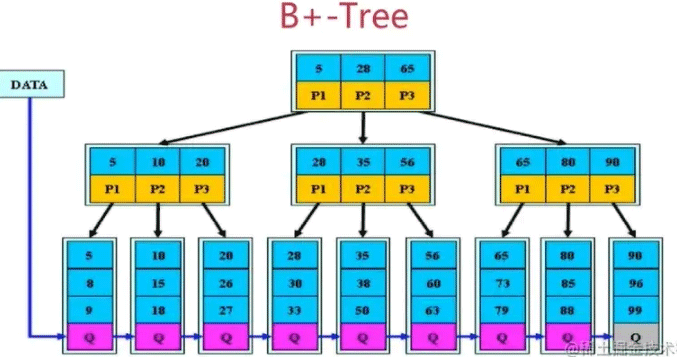
3.1 B+tree特性
B+树是B树的变体,其定义基本上与B树相同,除了:
- 非叶子结点的子树指针与关键字的个数相同;
- 非叶子结点的子树指针P[i],指向关键字值
[K[i],K[i+1])的子树,左闭右开区间; - 非叶子结点仅用于索引,数据都保存在叶子结点中;
- 所有的叶子结点均有一个链指针指向下一个叶子结点;
- B+树非叶子结点仅用来存放索引,能存储更多的关键字,使得B+树相对于B树来说更
矮壮,能存储更多数据。 - 所有的数据都存储在叶子结点。
四、结论
B+tree相比B-tree更适合用来存储索引,原因如下:
- B+树的磁盘读写代价更低,B+树内部节点不存放数据,只存放索引信息,因此其内部节点相对B-tree会更小,所以同一个盘快就能存储更多的关键字,一次性读入内存中需要查找的关键字也就越多,因此IO次数也就越低。
- B+树的查询效率更加稳定,由于B+树内部节点并不是指向文件内容的节点,而只是叶子节点关键字的索引,索引任何一个数据的查询都必须是:
任何关键字查询都是从根节点到叶子节点的查询路线,因此每个数据的查询效率都是稳定一致的。 - B+树跟有利于对数据的扫描,B-tree在解决磁盘IO性能同时并没有解决元素遍历效率低下问题,而B+树只需要遍历叶子节点就可以实现对所有关键字的扫描,所有对数据库频繁的范围查询是有着更高的查询性能。

