因为花了2天半才解决,中间痛苦的寻找,记录一下解决的流程与经验
1Error in y + 1 : non-numeric argument to binary operator
数据不是可计算的 numeric 或 integer 类型
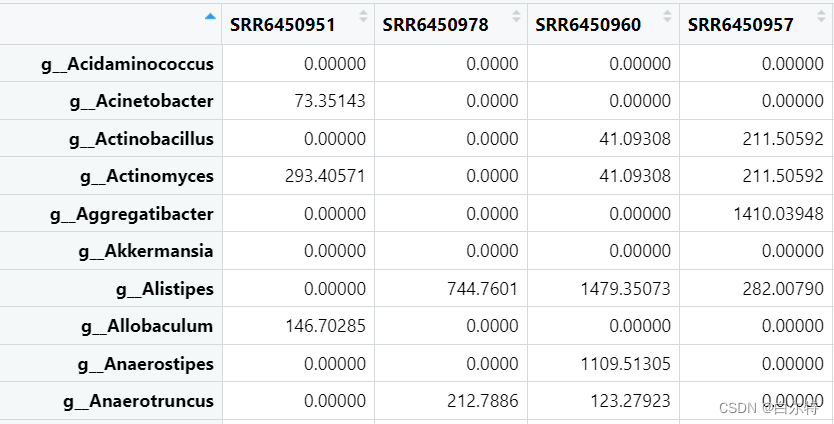
a = read.table(file = study.txt", sep = "\t", header = T, row.names = 1 ) class(a[3, 3]) # integer aa = t(d) class(aa[3, 3]) # character b = sparcc(aa) # 出现报错 Error in y + 1 : non-numeric argument to binary operator
1. 转置后数据类型变为character,因为numeric数据中存在character类型的脏数据
(原因:转置函数t() 是先将dataframe转换为矩阵matrix,而matrix只有一种数据类型。所以如果存在character,所有数据都会被转换成character)
如何发现是否有character脏数据:
read.table设置参数colClasses = “numeric”(确保数据框内只有numeric类型)
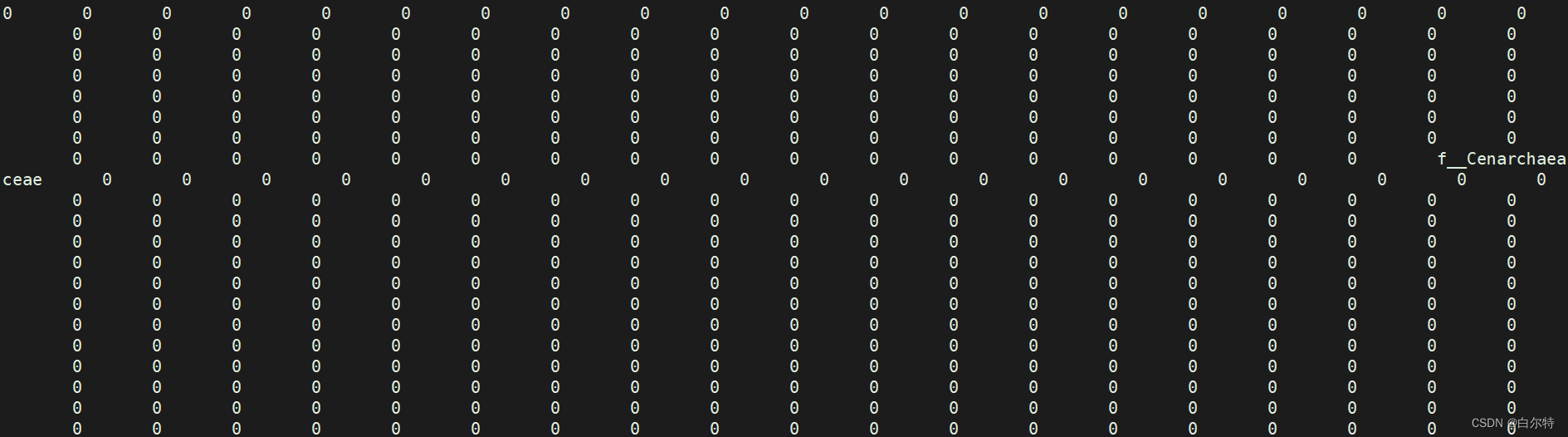
a = read.table(file = study.txt", sep = "\t", header = T, row.names = 1 colClasses = "numeric" # 添加的参数 ) # 出现报错 Error in scan(file = file, what = what, sep = sep, quote = quote, dec = dec, : scan() expected 'a real', got 'f__Cenarchaeaceae'
报错意为 数据框内存在“f__Cenarchaeaceae”,不属于numeric
查看txt内部
2. 引入character脏数据的原因
# 后续分析需要:设置data第一列列名为空格 genus <- data[1] colnames(genus) <- " " # 根据列名提取子集 a <- subset(data, select = (disID[, 1]))
subset()函数将列名为 空格blank 的也提取了,导致了character脏数据的进入

