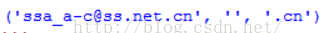今天接到一个需求有一个同事离职了,但是留下了非常多(2W多封)的邮件,我需要将他的邮件进行分类,只要邮件中以@xxx.com结尾的存放在文件夹中(下图名叫【是】的文件夹),否则放在另一个文件夹中(下图名叫【否】的文件夹)。 目录结构
import email(我发现是内置模块,不用安装) 下面是注意事项(就当是注释吧!!!!) 1、提取包含一下后缀的邮箱,我用了split(“@”),所以不用写 @e_a = [‘Honeywell.com’, ‘honeywell.com’, ‘garrettmotion.com’, ‘HONEYWELL.COM’, ‘resideo.com’]
2、提取,收件人、发件人、抄送人的邮箱(这个是可以不写的,但是我这个代码是借鉴的,没找到提取全部内容的函数,只找到提取内容的函数,所以加上了下面的代码)fjr = email.utils.parseaddr(msg.get(“from”))[1]
3、将eml文件内容与收件人、发件人、抄送人拼接,并且加 " " 间隔,不加会有些小问题
sjr = email.utils.parseaddr(msg.get(‘to’))[1]
csr = email.utils.parseaddr(msg.get(‘cc’))[1]
print(“发件人”, fjr)
print(“收件人”, sjr)
print(“抄送人”, csr)text = text + " " + fjr + " " + " " + " " + " " + sjr + " " + " " + csr
4、正则匹配邮箱prog = re.compile(r’[a-zA-Z0-9_.±]+@[a-zA-Z0-9-]+.[a-zA-Z0-9-.]+')
5、移动文件 os.remove()
res = prog.findall(text)
import email
import os
import re
from email import policy
from email.parser import BytesParser
e_a = ['Honeywell.com', 'honeywell.com', 'garrettmotion.com', 'HONEYWELL.COM', 'resideo.com']
for f in os.listdir("./数据源/"):
# print(f)
text = ""
with open("./数据源/" + f, 'rb') as fp:
msg = BytesParser(policy=policy.default).parse(fp)
fjr = email.utils.parseaddr(msg.get("from"))[1]
sjr = email.utils.parseaddr(msg.get('to'))[1]
csr = email.utils.parseaddr(msg.get('cc'))[1]
print("发件人", fjr)
print("收件人", sjr)
print("抄送人", csr)
if msg.get_body(preferencelist=('plain'))==None:
text = text + " " + fjr + " " + " " + " " + " " + sjr + " " + " " + csr
else:
text = msg.get_body(preferencelist=('plain')).get_content()
text = text + " " + fjr + " " + " " + " " + " " + sjr + " " + " " + csr
# print(text)
prog = re.compile(r'[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+')
res = prog.findall(text)
for e in res:
res1 = e.split("@")[1]
if res1 in e_a:
print(f, "在")
ori = "./数据源/" + f
now = "./是/" + f
os.rename(ori, now)
break
else:
ori = "./数据源/" + f
now = "./否/" + f
os.rename(ori, now)
print(f, "不在")下面来看看python验证邮箱模式的例子。
(首先还是把环境列出来)
环境:python 2.7.10
下面的例子中:邮箱中可以出现 数字、大小写字母、下划线、和横线(-)
# -*- coding:utf-8 -*-
# 邮箱格式-正则表达式匹配
import re
# 一次匹配多个邮箱
str1 = 'aaf ssa@ss.net asdf asdb@163.com.cn asdf ss-a@ss.net asdf asdd.cba@163.com afdsaf'
reg_str1 = r'([\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+)'
mod = re.compile(reg_str1)
items = mod.findall(str1)
for item in items:
print item结果输出:

这种情况,常见在登录界面用户名为邮箱时, 此时一个字符串只有一个 邮箱
# 只匹配一个
str2 = 'ssa_a-c@ss.net.cn'
reg_str2 = r'(^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$)'
mod = re.compile(reg_str2)
items = mod.findall(str2)
for item in items:
print item结果输出: