之前在训练网络的时候加载数据都是稀里糊涂的放进去的,也没有理清楚里面的流程,今天整理一下,加深理解,也方便以后查阅。
epoch:1个epoch等于使用训练集中的全部样本训练一次,通俗的讲epoch的值就是整个数据集被轮几次。batch_size:批大小。在深度学习中,一般采用SGD训练,即每次训练在训练集中取batchsize个样本训练;iteration:1个iteration等于使用batch_size个样本训练一次;深度学习的优化算法,说白了就是梯度下降。每次的参数更新有两种方式。
第一种,遍历全部数据集算一次损失函数,然后算函数对各个参数的梯度,更新梯度,这称为批梯度下降(Batch gradient descent)。
这样做至少有 2 个好处:其一,由全数据集确定的方向能够更好地代表样本总体,从而更准确地朝向极值所在的方向。其二,由于不同权重的梯度值差别巨大,因此选取一个全局的学习率很困难。 Full Batch Learning 可以使用 Rprop 只基于梯度符号并且针对性单独更新各权值。
对于更大的数据集,以上 2 个好处又变成了 2 个坏处:其一,随着数据集的海量增长和内存限制,一次性载入所有的数据进来变得越来越不可行。其二,以 Rprop 的方式迭代,会由于各个 Batch 之间的采样差异性,各次梯度修正值相互抵消,无法修正。这才有了后来 RMSProp 的妥协方案。
另一种,每看一个数据就算一下损失函数,然后求梯度更新参数,这个称为随机梯度下降(Stochastic gradient descent)。这个方法速度比较快,但是收敛性能不太好,可能在最优点附近晃来晃去,达不到最优点。两次参数的更新也有可能互相抵消掉,造成目标函数震荡的比较剧烈。
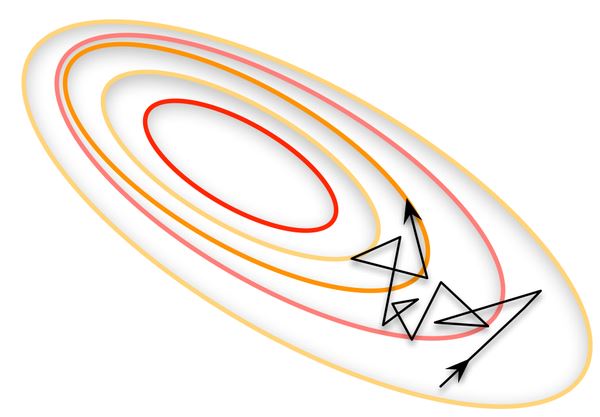
为了克服两种方法的缺点,现在一般采用的是一种折中手段,mini-batch gradient decent,小批的梯度下降,这种方法把数据分为若干个批,按批来更新参数,这样,一个批中的一组数据共同决定了本次梯度的方向,下降起来就不容易跑偏,减少了随机性。另一方面因为批的样本数与整个数据集相比小了很多,计算量也不是很大。
现在用的优化器SGD是stochastic gradient descent的缩写,但不代表是一个样本就更新一回,还是基于mini-batch的。
在小批量梯度下降的情况下,流行的批量大小包括32,64和128个样本。
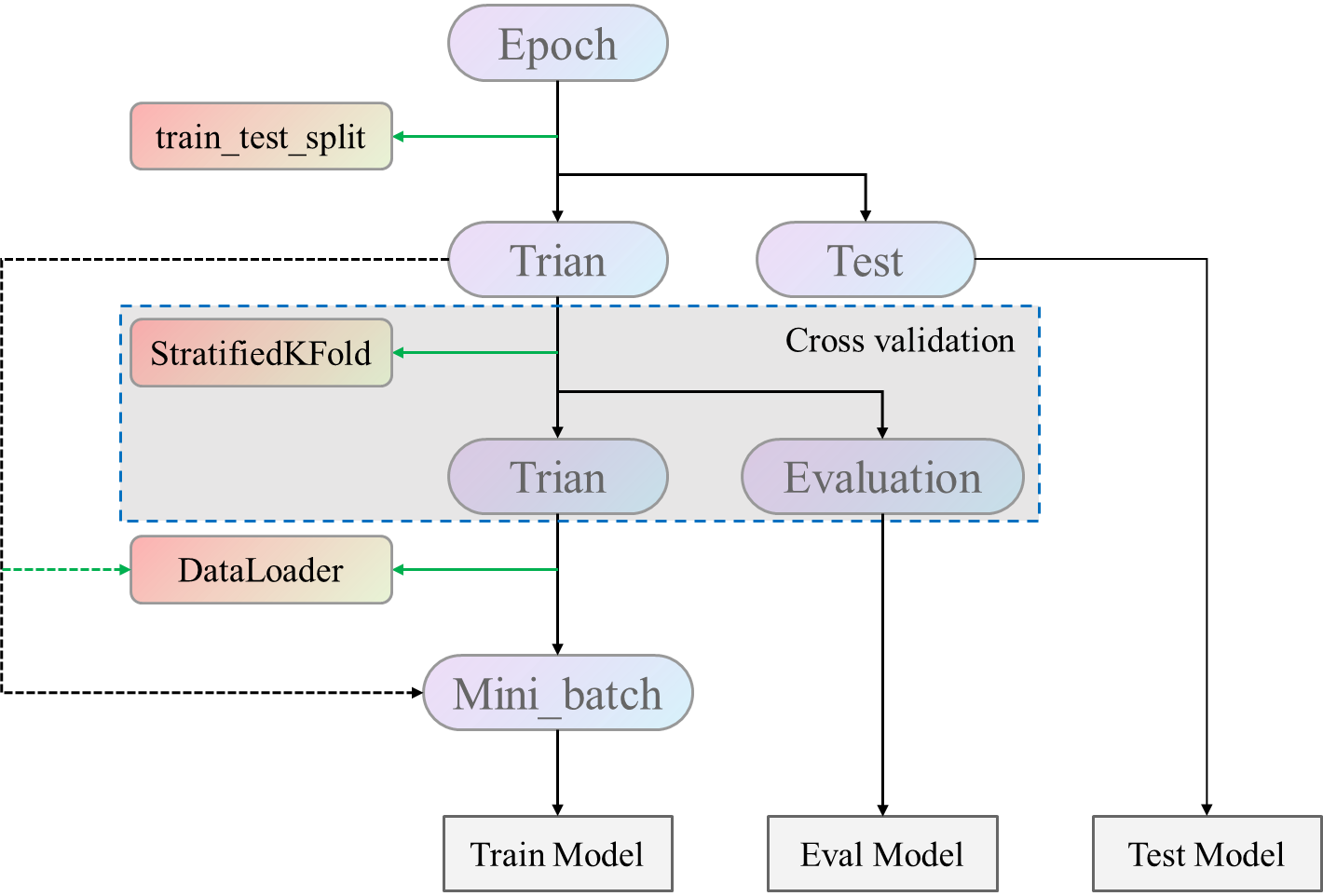
以BCICIV_2a数据为例
import mne import numpy as np import torch import torch.nn as nn
class LoadData:
def __init__(self,eeg_file_path: str):
self.eeg_file_path = eeg_file_path
def load_raw_data_gdf(self,file_to_load):
self.raw_eeg_subject = mne.io.read_raw_gdf(self.eeg_file_path + '/' + file_to_load)
return self
def load_raw_data_mat(self,file_to_load):
import scipy.io as sio
self.raw_eeg_subject = sio.loadmat(self.eeg_file_path + '/' + file_to_load)
def get_all_files(self,file_path_extension: str =''):
if file_path_extension:
return glob.glob(self.eeg_file_path+'/'+file_path_extension)
return os.listdir(self.eeg_file_path)class LoadBCIC(LoadData):
'''Subclass of LoadData for loading BCI Competition IV Dataset 2a'''
def __init__(self, file_to_load, *args):
self.stimcodes=('769','770','771','772')
# self.epoched_data={}
self.file_to_load = file_to_load
self.channels_to_remove = ['EOG-left', 'EOG-central', 'EOG-right']
super(LoadBCIC,self).__init__(*args)
def get_epochs(self, tmin=0,tmax=1,baseline=None):
self.load_raw_data_gdf(self.file_to_load)
raw_data = self.raw_eeg_subject
# raw_downsampled = raw_data.copy().resample(sfreq=128)
self.fs = raw_data.info.get('sfreq')
events, event_ids = mne.events_from_annotations(raw_data)
stims =[value for key, value in event_ids.items() if key in self.stimcodes]
epochs = mne.Epochs(raw_data, events, event_id=stims, tmin=tmin, tmax=tmax, event_repeated='drop',
baseline=baseline, preload=True, proj=False, reject_by_annotation=False)
epochs = epochs.drop_channels(self.channels_to_remove)
self.y_labels = epochs.events[:, -1] - min(epochs.events[:, -1])
self.x_data = epochs.get_data()*1e6
eeg_data={'x_data':self.x_data,
'y_labels':self.y_labels,
'fs':self.fs}
return eeg_datadata_path = "/home/pytorch/LiangXiaohan/MI_Dataverse/BCICIV_2a_gdf" file_to_load = 'A01T.gdf'
'''for BCIC Dataset'''
bcic_data = LoadBCIC(file_to_load, data_path)
eeg_data = bcic_data.get_epochs() # {'x_data':, 'y_labels':, 'fs':}
X = eeg_data.get('x_data')
Y = eeg_data.get('y_labels')
Y.shape
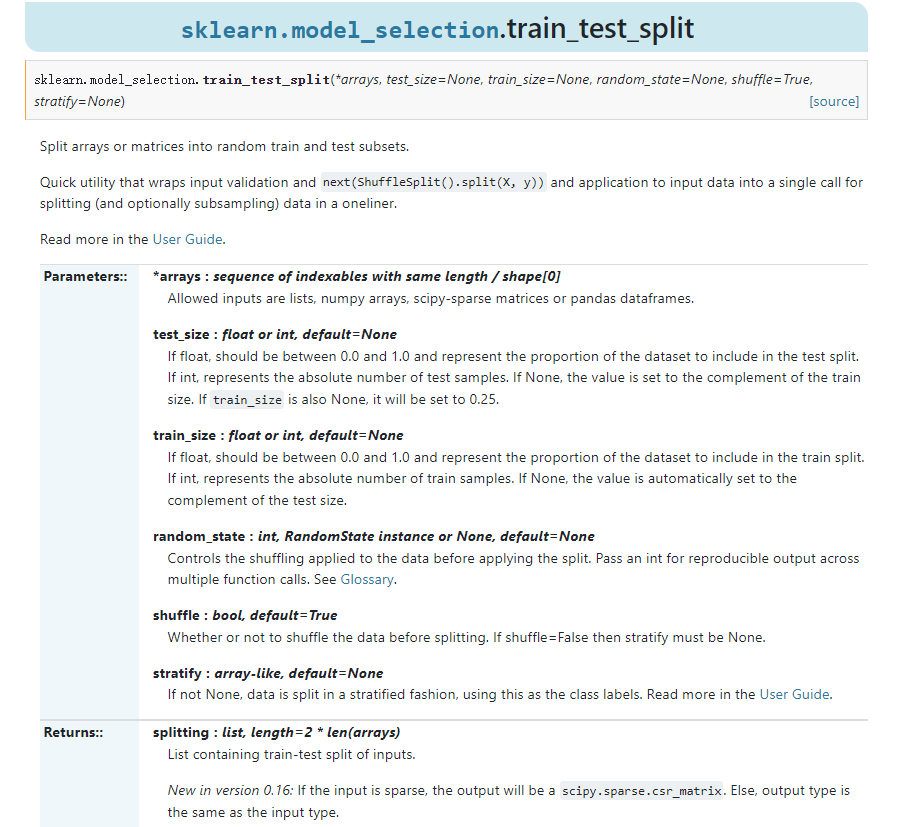
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.2, random_state=0) X_train.shape

from sklearn.model_selection import StratifiedKFold
train_idx = {}
eval_idx = {}skf = StratifiedKFold(n_splits=4, shuffle=True)
i = 0
for train_indices, eval_indices in skf.split(X_train, y_train):
train_idx.update({i: train_indices})
eval_idx.update({i: eval_indices})
i += 1
train_idx.get(1).shape
def split_xdata(eeg_data, train_idx, eval_idx):
x_train=np.copy(eeg_data[train_idx,:,:])
x_eval=np.copy(eeg_data[eval_idx,:,:])
x_train = torch.from_numpy(x_train).to(torch.float32)
x_eval = torch.from_numpy(x_eval).to(torch.float32)
return x_train, x_evaldef split_ydata(y_true, train_idx, eval_idx):
y_train = np.copy(y_true[train_idx])
y_eval = np.copy(y_true[eval_idx])
y_train = torch.from_numpy(y_train)
y_eval = torch.from_numpy(y_eval)
return y_train, y_evalx_train, x_eval = split_xdata(X_train, train_idx.get(1), eval_idx.get(1)) y_train, y_eval = split_ydata(Y_train, train_idx.get(1), eval_idx.get(1)) y_train.shape

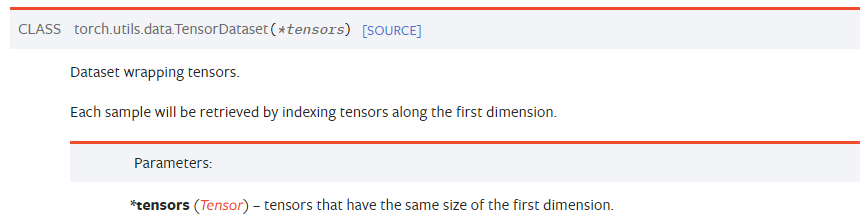
from torch.utils.data import Dataset, DataLoader, TensorDataset
from tqdm import tqdm
def BCICDataLoader(x_train, y_train, batch_size=64, num_workers=2, shuffle=True):
data = TensorDataset(x_train, y_train)
train_data = DataLoader(dataset=data, batch_size=batch_size, shuffle=shuffle, num_workers=num_workers)
return train_datatrain_data = BCICDataLoader(x_train, y_train, batch_size=32)
for inputs, target in tqdm(train_data):
print(target)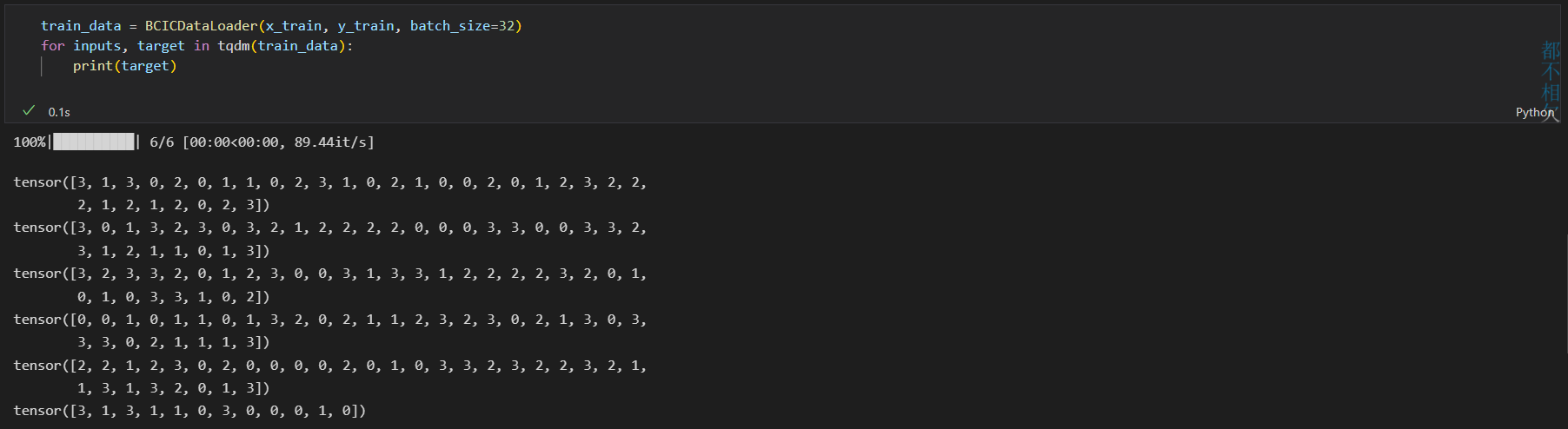
到此数据就读出来了!!!

http://pytorch.org/docs/stable/data.html?highlight=tensordataset#torch.utils.data.TensorDataset
http://pytorch.org/docs/stable/data.html?highlight=dataloader#torch.utils.data.DataLoader