延时任务相信大家都不陌生,在现实的业务中应用场景可以说是比比皆是。例如订单下单15分钟未支付直接取消,外卖超时自动赔付等等。这些情况下,我们该怎么设计我们的服务的实现呢?
笨一点的方法自然是定时任务去数据库进行轮询。但是当业务量较大,事件处理比较费时的时候,我们的系统和数据库往往会面临巨大的压力,如果采用这种方式或许会导致数据库和系统的崩溃。那么有什么好办法吗?今天我来为大家介绍几种实现延时任务的办法。
你没看错,java内部有内置延时队列,位于java concurrent包内。
DelayQueue是一个jdk中自带的延时队列实现,他的实现依赖于可重入锁ReentrantLock以及条件锁Condition和优先队列PriorityQueue。而且本质上他也是一个阻塞队列。那么他是如何实现延时效果的呢。
首先DelayQueue队列中的元素必须继承一个接口叫做Delayed,我们找到这个类
public interface Delayed extends Comparable<Delayed> {
long getDelay(TimeUnit unit);
}发现这个类内部定义了一个返回值为long的方法getDelay,这个方法用来定义队列中的元素的过期时间,所有需要放在队列中的元素,必须实现这个方法。
然后我们来看看延迟队列的队列是如何操作的,我们就拿最典型的offer和take来看:
public boolean offer(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
q.offer(e);
if (q.peek() == e) {
leader = null;
available.signal();
}
return true;
} finally {
lock.unlock();
}
}offer操作平平无奇,甚至直接调用到了优先队列的offer来将队列根据延时进行排序,只不过加了个锁,做了些数据的调整,没有什么深入的地方,但是take的实现看上去就很复杂了。(注意,Dalayed继承了Comparable方法,所以是可以直接用优先队列来排序的,只要你自己实现了compareTo方法)我尝试加了些注释让各位看得更明白些:
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
// 自选操作
for (;;) {
// 获取队列第一个元素,如果队列为空
// 阻塞住直到有新元素加入队列,offer等方法调用signal唤醒线程
E first = q.peek();
if (first == null)
available.await();
else {
// 如果队列中有元素
long delay = first.getDelay(NANOSECONDS);
// 判断延时时间,如果到时间了,直接取出数据并return
if (delay <= 0)
return q.poll();
first = null;
// 如果leader为空则阻塞
if (leader != null)
available.await();
else {
// 获取当前线程
Thread thisThread = Thread.currentThread();
// 设置leader为当前线程
leader = thisThread;
try {
// 阻塞延时时间
available.awaitNanos(delay);
} finally {
if (leader == thisThread)
leader = null;
}
}
}
}
} finally {
if (leader == null && q.peek() != null)
available.signal();
lock.unlock();
}
}我们可以看到take的实现依靠了无限自旋,直到第一个队列元素过了超时时间后才会返回,否则等待他的只有被阻塞。
看了源码后,我们应该对DelayQueue的实现有了一个大致的了解,也对他的优缺点有了一定的理解。他的优点很明显:
但是他的缺点也是很明显的:
所以有没有更好的延时队列的实现呢,我们继续看下去~
时间轮算法是一个被设计出来处理延时任务的算法,现实中的应用可以在kafka以及netty等项目中找到类似的实现。
所谓时间轮,顾名思义,他是一个类似于时钟的结构,即他的主结构是一个环形数组,如图:

环形数组中存放的是一个一个的链表,链表中存放着需要执行的任务,我们设定好数组中执行的间隔,假设我们的环形数组的长度是60,每个数组的执行间隔为1s,那么我们会在每过1s就会执行数组下一个元素中的链表中的元素。如果只是这样,那么我们将无法处理60秒之外的延时任务,这显然不合适,所以我们会在每个任务中加上一个参数圈数,来表明任务会在几圈后执行。假如我们有一个任务是在150s后执行,那么他应该在30s的位置,同时圈数应该为2。我们每次执行一个链表中的任务的时候会把当圈需要执行的任务取出执行,然后把他从链表中删除,如果任务不是当圈执行,则修改他的圈数,将圈数减1,于是一个简单的时间轮出炉了。
那么这样的时间轮有什么优缺点呢?
先来说优点吧:
DelayQueue来说,时间轮的插入更加的高效,时间复杂度为O(1)当然他的缺点也不少:
DelayQueue一样不支持分布式,并且数据放在内存中,没有持久化的支持,服务宕机会丢失数据刚才提到了一些时间轮算法的缺点,那么是不是有一些方法来进行下优化?这里我来介绍一下时间轮的优化版本。
之前我们提到不同圈数的任务会在同一个链表中被重复遍历影响效率,这种情况下我们可以进行如下优化:将时间轮进行分层
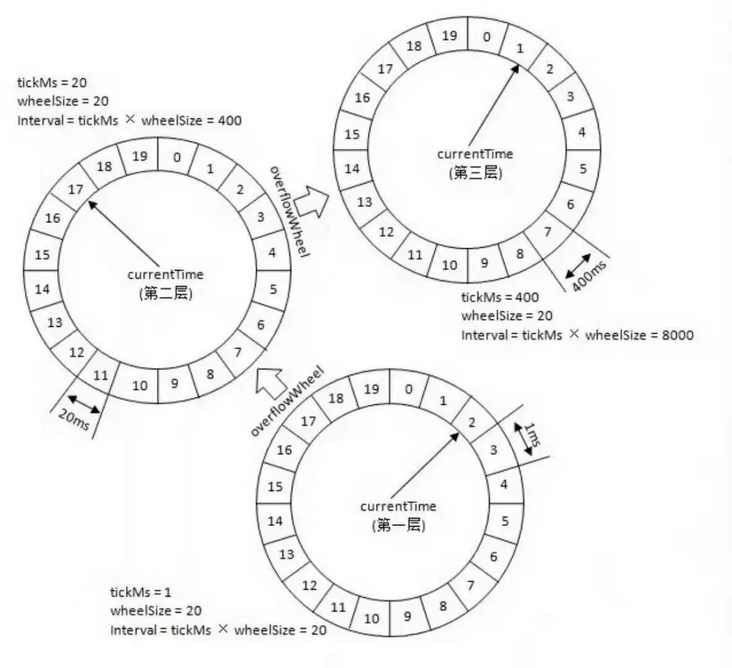
我们可以看到图中,我们采用了多层级的设计,上图中分了三层,每层都是60格,第一个轮盘中的间隔为1小时,我们的数据每一次都是插入到这个轮盘中,每当这个轮盘经过一个小时后来到下一个刻度,就会取出其中的所有元素,按照延迟时间放入到第二个象征着分钟的轮盘中,以此类推。
这样的实现好处可以说是显而易见的:
时间轮算法可能在之前大家没有听说过,但是他在各个地方都有着不小的作用。linux的定时器的实现中就有时间轮的身影,同样如果你是一个喜好看源码的读者,你也可能会在kafka以及netty中找到他的实现。
kafka
kafka中应用了时间轮算法,他的实现和之前提到的进阶版时间轮没有太大的区别,只有在一点上:kafka内部实现的时间轮应用到了DelayQueue。
@nonthreadsafe
private[timer] class TimingWheel(tickMs: Long, wheelSize: Int, startMs: Long, taskCounter: AtomicInteger, queue: DelayQueue[TimerTaskList]) {
private[this] val interval = tickMs * wheelSize
private[this] val buckets = Array.tabulate[TimerTaskList](wheelSize) { _ => new TimerTaskList(taskCounter) }
private[this] var currentTime = startMs - (startMs % tickMs)
@volatile private[this] var overflowWheel: TimingWheel = null
private[this] def addOverflowWheel(): Unit = {
synchronized {
if (overflowWheel == null) {
overflowWheel = new TimingWheel(
tickMs = interval,
wheelSize = wheelSize,
startMs = currentTime,
taskCounter = taskCounter,
queue
)
}
}
}
def add(timerTaskEntry: TimerTaskEntry): Boolean = {
val expiration = timerTaskEntry.expirationMs
if (timerTaskEntry.cancelled) {
false
} else if (expiration < currentTime + tickMs) {
false
} else if (expiration < currentTime + interval) {
val virtualId = expiration / tickMs
val bucket = buckets((virtualId % wheelSize.toLong).toInt)
bucket.add(timerTaskEntry)
if (bucket.setExpiration(virtualId * tickMs)) {
queue.offer(bucket)
}
true
} else {
if (overflowWheel == null) addOverflowWheel()
overflowWheel.add(timerTaskEntry)
}
}
def advanceClock(timeMs: Long): Unit = {
if (timeMs >= currentTime + tickMs) {
currentTime = timeMs - (timeMs % tickMs)
if (overflowWheel != null) overflowWheel.advanceClock(currentTime)
}
}
}上面是kafka内部的实现(使用的语言是scala),我们可以看到实现非常的简洁,并且使用到了DelayQueue。我们刚才已经讨论过了DelayQueue的优缺点,查看源码后我们已经可以有一个大致的结论了:DelayQueue在kafka的时间轮中的作用是负责推进任务的,为的就是防止在时间轮中由于任务比较稀疏而造成的"空推进"。DelayQueue的触发机制可以很好的避免这一点,同时由于DelayQueue的插入效率较低,所以仅用于底层的推进,任务的插入由时间轮来操作,两者配置,可以实现效率和资源的平衡。
netty
netty的内部也有时间轮的实现HashedWheelTimer
HashedWheelTimer的实现要比kafka内部的实现复杂许多,和kafka不同的是,它的内部推进不是依靠的DelayQueue而是自己实现了一套,源码太长,有兴趣的读者可以自己去看一下。
时间轮说了这么多,我们可以看到他的效率是很出众的,但是还是有这么一个问题:他不支持分布式。当我们的业务很复杂,需要分布式的时候,时间轮显得力不从心,那么这个时候有什么好一点的延时队列的选择呢?我们或许可以尝试使用第三方的工具
其实啊说起延时,我们如果常用redis的话,就会想起redis是存在过期机制的,那么我们是否可以利用这个机制来实现一个延时队列呢?
redis自带key的过期机制,而且可以设置过期后的回调方法。基于此特性,我们可以非常容易就完成一个延时队列,任务进来时,设定定时时间,并且配置好过期回调方法即可。
除了使用redis的过期机制之外,我们也可以利用它自带的zset来实现延时队列。zset支持高性能的排序,因此我们任务进来时可以将时间戳作为排序的依据,以此将任务的执行先后进行有序的排列,这样也能实现延时队列。
zset实现延时队列的好处:
redis本身的高可用和高性能以及持久性rocketmq天然支持延时消息,他的延时消息分为18个等级,每个等级对应不同的延时时间。
那么他的原理是怎样的呢?
rocketmq的broker收到消息后会将消息写入commitlog,并且判断这个消息是否是延时消息(即delay属性是否大于0),之后如果判断确实是延时消息,那么他不会马上写入,而是通过转发的方式将消息放入对应的延时topic(18个延时级别对应18个topic)
rocketmq会有一个定时任务进行轮询,如果任务的延迟时间已经到了就发往指定的topic。
这个设计比较的简单粗暴,但是缺点也十分明显:
rocketmq本身是不支持的精确延迟的,他的商业版本ons倒是支持。不过rocketmq的社区中有相应的解决方案。方案是借助于时间轮算法来实现的,感兴趣的朋友可以自行去社区查看。(社区中的一些未被合并的pr是不错的实现参考)
延时队列的实现千千万,但是如果要在生产中大规模使用,那么大部分情况下其实都避不开时间轮算法。改进过的时间轮算法可以做到精准延时,持久化,高性能,高可用性,可谓是完美。但是话又说回来,其他的延时方式就无用了吗?其实不是的,所有的方式都是需要匹配自己的使用场景。如果你是极少量数据的轮询,那么定时轮询数据库或许才是最佳的解决方案,而不是无脑的引入复杂的延时队列。如果是单机的任务,那么jdk的延时队列也是不错的选择。
本文介绍的这些延时队列只是为了向大家展示他们的原理和优缺点,具体的使用还需要结合自己业务的场景。

