雪花算法是在一个项目体系中生成全局唯一ID标识的一种方式,偶然间看到了Python使用雪花算法不尽感叹真的是太便捷了。
它生成的唯一ID的规则也是通过常用的时间戳来统计的,但是计算方式却更为精准。除此之外,再配合上不同机器属性分布式的使用就可以使生成的ID在整个单击或是分布式项目保持唯一性。
雪花算法通过时间规则,以二进制的方式将进行时间戳以及机器属性等信息的填充,所以生成后的唯一ID是按照时间递增的规律来排列的。为了形成对比,下面先看看在Java开发中的雪花算法是如何生成唯一ID的。
package utils;
public class Snowflake {
/** 开始时间截 (2015-01-01) */
private final long twepoch = 1420041600000L;
/** 机器id所占的位数 */
private final long workerIdBits = 5L;
/** 数据标识id所占的位数 */
private final long datacenterIdBits = 5L;
/** 支持的最大机器id,结果是31 (这个移位算法可以很快的计算出几位二进制数所能表示的最大十进制数) */
private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
/** 支持的最大数据标识id,结果是31 */
private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
/** 序列在id中占的位数 */
private final long sequenceBits = 12L;
/** 机器ID向左移12位 */
private final long workerIdShift = sequenceBits;
/** 数据标识id向左移17位(12+5) */
private final long datacenterIdShift = sequenceBits + workerIdBits;
/** 时间截向左移22位(5+5+12) */
private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
/** 生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095) */
private final long sequenceMask = -1L ^ (-1L << sequenceBits);
/** 工作机器ID(0~31) */
private long workerId;
/** 数据中心ID(0~31) */
private long datacenterId;
/** 毫秒内序列(0~4095) */
private long sequence = 0L;
/** 上次生成ID的时间截 */
private long lastTimestamp = -1L;
public Snowflake(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
public synchronized long nextId() {
long timestamp = timeGen();
//如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常
if (timestamp < lastTimestamp) {
throw new RuntimeException(
String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
//如果是同一时间生成的,则进行毫秒内序列
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
//毫秒内序列溢出
if (sequence == 0) {
//阻塞到下一个毫秒,获得新的时间戳
timestamp = tilNextMillis(lastTimestamp);
}
}
//时间戳改变,毫秒内序列重置
else {
sequence = 0L;
}
//上次生成ID的时间截
lastTimestamp = timestamp;
//移位并通过或运算拼到一起组成64位的ID
return ((timestamp - twepoch) << timestampLeftShift) //
| (datacenterId << datacenterIdShift) //
| (workerId << workerIdShift) //
| sequence;
}
protected long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
protected long timeGen() {
return System.currentTimeMillis();
}
public static void main(String[] args) {
Snowflake idWorker = new Snowflake(0, 0);
for (int i = 0; i < 100; i++) {
long id = idWorker.nextId();
System.out.println(Long.toBinaryString(id));
System.out.println(id);
}
}
}
通过上述的Java代码块就能生成100个唯一的ID,并且在Java代码块中定义生成ID时各种属性信息,大概有100行代码左右,我截取了生成唯一ID的部分结果来展示。
111001000000000011001001011001011010110000000000000000010111
1026834554947633175
111001000000000011001001011001011010110000000000000000011000
1026834554947633176
111001000000000011001001011001011011000000000000000000000000
1026834554951827456
111001000000000011001001011001011011000000000000000000000001
1026834554951827457
这样的代码块可能使用C++的方式实现的话过程可能更为复杂,相比之下Python开发的话比较简单,因为大佬们已经将一些复杂的东西都写好了,我们经常只需要直接调用即可,这里说明一下不同编程语言都是我们做业务的一种工具,都有自己诞生的使命。
接下来,我们使用python调用第三方模块的方式来实现雪花算法,具体使用python实现雪花算法生成唯一ID的思路肯定和Java也是相似的。
在python中,大佬们已经封装了pysnowflake的python非标准库,这也是python之所以方便的原因,通过pip的方式将其安装完成就能大显身手了。
pip install pysnowflake -i http://pypi.tuna.tsinghua.edu.cn/simple/
安装完成之后需要启动雪花算法生成唯一ID的服务,并且可以定义工作的数量,这里我们将工作数量定义为1启动服务。
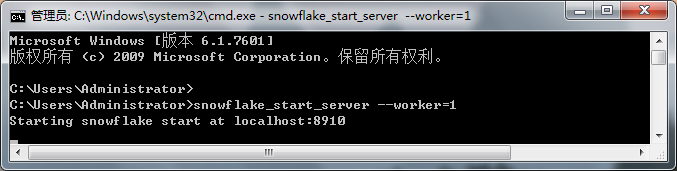
将snowflake.client导入到代码块中,相当于我们作为客户端去访问服务端就会直接生成唯一ID。
# Importing the `snowflake.client` module. import snowflake.client # Calling the `get_guid()` function from the `snowflake.client` module. uuid = snowflake.client.get_guid() # Printing the value of the `uuid` variable. print(uuid) # Printing the binary representation of the `uuid` variable. print(bin(uuid)) # 4674877370191056897 # 0b100000011100000100000000011001100011010110000000001000000000001

