1.词向量预训练模型的优势:
(1)训练和保存含有语义信息的词向量,在用于模型训练之前,enbedding的过程同样带有语义信息,使模型训练的效果更好;
(2)可以用预训练好的词向量模型直接计算两个词和文本的相似度,常推荐用余弦相似度计算;
2.词向量预训练模型的限制因素:
(1)对训练语料的要求非常高,要求训练语料大而全,所以训练起来比较费时间,并且训练语料的来源也是个问题;
(2)公开的预训练模型一般都是用大量的公共数据训练的,如百科、文献、报纸等公开数据集,所以只能适用于一些通用型的机器学习任务,像医学、生物等领域就不太实用。
3.自己训练词向量的全流程:
(1)准备数据:我这边是训练的电子病历数据,将来也是用于电子病历的enbedding过程,所以我这边只准备了电子病历数据,大概是1000w+的数据。
(2)清洗数据:电子病历数据的清洗比较麻烦,首先,二次脱敏,保证将姓名、医院名、地市名称以及一些相关的电话和编号等信息脱敏干净,一是防止隐私泄露,二是防止这些噪声的影响训练效果。
(3)选用模型:word2vec中的CBOW:
(4)代码如下:
from gensim.models import Word2Vec import pandas as pd import numpy as np import re import jieba
数据读取:数据量太大,不建议用excel,无内存限制当我没说
pd_data = pd.read_excel('data/emr_500w.xlsx')清洗一下数据:
def clean_data(data):
res = re.sub('[\s@\u3000\u2002\?\*%#¥&::,,。.-_——?、《》;;]+', ' ' ,data)
return res
res = pd_data.text.apply(lambda x : jieba.lcut(clean_data(x))).to_list()
train_data = [i for lis in res for i in lis if i.strip()]
train_data_02 = []
for i in res:
lis_ = [j for j in i if j.strip()]
train_data_02.append(lis_)参数设置和参数解释:
· sentences:可以是一个list,对于大语料集,建议使用BrownCorpus,Text8Corpus或·ineSentence构建。
· sg: 用于设置训练算法,默认为0,对应CBOW算法;sg=1则采用skip-gram算法。
· size:是指特征向量的维度,默认为100。大的size需要更多的训练数据,但是效果会更好. 推荐值为几十到几百。
· window:表示当前词与预测词在一个句子中的最大距离是多少。Harris 在 1954 年提出的分布假说( distributional hypothesis)指出, 一个词的词义由其所在的上下文决定。所以word2vec的参数中,窗口设置一般是5,而且是左右随机1-5(小于窗口大小)的大小,是均匀分布,随机的原因应该是比固定窗口效果好,增加了随机性,个人理解应该是某一个中心词可能与前后多个词相关,也有的词在一句话中可能只与少量词相关(如短文本可能只与其紧邻词相关)。
· alpha: 是学习速率
· seed:用于随机数发生器。与初始化词向量有关。
· min_count: 可以对字典做截断. 词频少于min_count次数的单词会被丢弃掉, 默认值为5。该模块在训练结束后可以通过调用model.most_similar('电影',topn=10)得到与电影最相似的前10个词。如果‘电影’未被训练得到,则会报错‘训练的向量集合中没有留下该词汇’。
· max_vocab_size: 设置词向量构建期间的RAM限制。如果所有独立单词个数超过这个,则就消除掉其中最不频繁的一个。每一千万个单词需要大约1GB的RAM。设置成None则没有限制。
· sample: 高频词汇的随机降采样的配置阈值,默认为1e-3,范围是(0,1e-5)
· workers参数控制训练的并行数。
· hs: 如果为1则会采用hierarchica·softmax技巧。如果设置为0(defau·t),则negative sampling会被使用。
· negative: 如果>0,则会采用negativesamp·ing,用于设置多少个noise words
· cbow_mean: 如果为0,则采用上下文词向量的和,如果为1(defau·t)则采用均值。只有使用CBOW的时候才起作用。
· hashfxn: hash函数来初始化权重。默认使用python的hash函数
· iter: 迭代次数,默认为5
· trim_rule: 用于设置词汇表的整理规则,指定那些单词要留下,哪些要被删除。可以设置为None(min_count会被使用)或者一个接受()并返回RU·E_DISCARD,uti·s.RU·E_KEEP或者uti·s.RU·E_DEFAU·T的函数。
· sorted_vocab: 如果为1(defau·t),则在分配word index 的时候会先对单词基于频率降序排序。
· batch_words:每一批的传递给线程的单词的数量,默认为10000。这里我认为是在训练时,控制一条样本(一个句子)中词的个数为10000,大于10000的截断;训练时依次输入batch_words的2*window(实际上不一定是2*window,因为代码内部还对[0,window]取了随机。
模型训练:sg没写,默认CBOW;训练50维度;word2vec的参数中,窗口设置一般是5,而且是左右随机1-5(小于窗口大小)的大小,是均匀分布,随机的原因应该是比固定窗口效果好,增加了随机性;min_count = 1控制词频和筛选;iter = 10迭代10次;
model = Word2Vec(train_data_02, size=50, window=5, min_count=1, workers=8, sg=0, batch_words=1500,iter = 10)
模型保存:
# 第一种
# model = Word2Vec.load(word2vec.model)
model.save('emr2vec.model')
# 第二种
# model = gensim.models.KeyedVectors.load_word2vec_format('word2vec.bin',binary=True)
model.wv.save_word2vec_format('emr2vec.bin')
# 第三种
# gensim.models.KeyedVectors.load_word2vec_format('word2vec.txt',binary=False)
model.wv.save_word2vec_format('emr2vec.txt')测试:导入模型
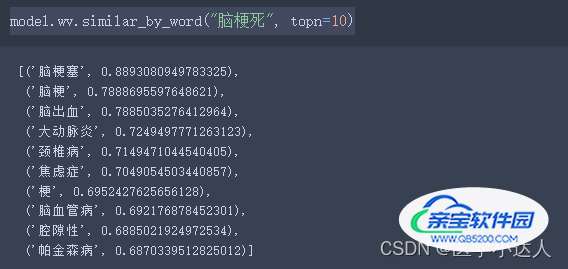
model = Word2Vec.load("emr2vec.model")
#筛选10个与当前词最近的词向量
model.wv.similar_by_word("脑梗死", topn=10)结果: