索引下推(Index Condition PushDown,简称ICP)是从MySQL5.6开始引入的一个特性,索引下推通过减少回表的次数来提高数据库的查询效率;
准备:
①.为了演示索引下推,需要安装MySQL5.5和MySQL5.7两个版本的MySQL,因为索引下推是MySQL5.6版本中开始引入的新特性,所以这两个版本就可以演示出索引下推的特点;
②.数据库脚本:
CREATE TABLE `user1` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`username` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`address` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `username` (`username`,`age`)
) ENGINE=InnoDB AUTO_INCREMENT=100001 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
insert into user1(username,age,address) values('zhangsan',25,'China'),('lisi',30,'China');
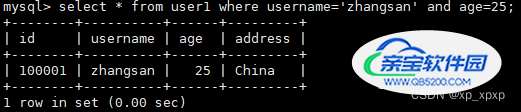
1>.精确匹配:
select * from user1 where username='zhangsan' and age=25;
2>.查看执行计划
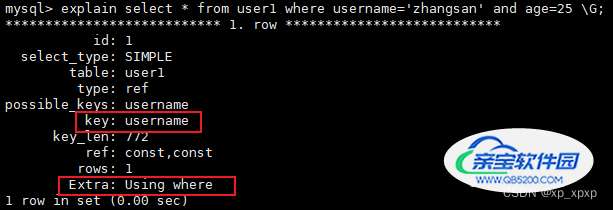
type: ref表示通过索引查找数据,一般出现在等值匹配的时候,type为ref;
extra: Usering where表示数据在server层进行了过滤操作;
可以看到,这个查询SQL是使用了索引(非主键索引)的!
在MySQL5.5中,由于没有索引下推,所以上面查询SQL的执行流程如下:
①.首先MySQL的server层调用存储引擎获取username='zhangsan’的一条记录;
②.存储引擎找到username='zhangsan’的第一条记录之后,在B+Tree的叶子节点中保存着主键id,此时通过回表操作,去主键索引中找到该条记录的完整数据,并返回给server层;
③.server层拿到数据之后,判断该条记录的age是否为25,如果是,就把该条记录返回给客户端,如果不是,那么就丢弃该条记录;
④.由于userame+age组成的复合索引只是一个普通索引,并不是唯一索引(如果是唯一索引,那么这个查询就到此结束了),所以还需要继续去搜索有没有满足条件的记录;
注意: 第④步的搜索方式,并不是直接去B+Tree中搜索.由于在username索引中,username字段的存储是有序的,即username='zhangsan'的记录都是挨着的,而B+Tree的叶子节点之间通果双向链表关联,通过一个叶子节点就能找到下一个叶子节点(或者上一个叶子节点),第②步返回的数据中有一个next_record属性,该属性就直接指向二级索引的下一条记录,找到下一条记录之后,回表拿到所有数据并返回给server层,然后重复③,④步;
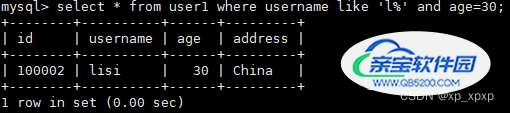
3>.模糊匹配:
select * from user1 where username like 'l%' and age=30;
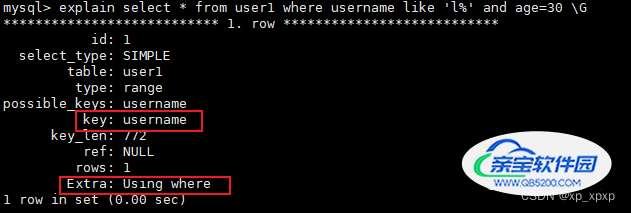
type: range表示按照范围搜索;
也使用了索引,其SQL的执行流程跟上面一条查询SQL的执行流程基本一致!
小结:
前面两个查询SQL,由于查询的时候是"select *",所以都是需要回表操作的,虽然是复合索引,索引中既有username又有age,但是查询条件中只能传入username到存储引擎中,从存储引擎中回表拿到一行数据的完整记录之后,再返回给server层,再在server层判断age是否满足条件.其实这样的查询效率比较低,明明索引中有age的值,但是却不在索引中比较age的值,而是要回表,取一行的完整记录出来,返回给server层,然后在和age去比较,要是比较不通过,这条记录就会被丢弃了.如果我们能够把age直接传入存储引擎,在存储引擎中直接去判断age是否满足条件.如果满足条件了,再去回表查询完整的记录.如果不满足条件就到此结束,这样就可以减少回表的次数,进而提高查询效率;
从MySQL5.6开始引进的索引下推技术,就是用来解决这样的问题的!
1>.模糊匹配:
select * from user1 where username like 'l%' and age=30;

2>.查看执行计划:
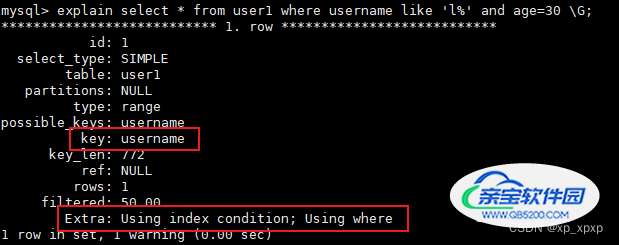
可以看到,MySQL5.7中的这个执行计划和上面MySQL5.5中的执行计划相比,主要是最后的Extra为"Using index condition",这就是MySQL5.6开始引入的索引下推技术(ICP);
执行流程如下:
①.MySQL中的server层首先调用存储引擎定位到第一个以"l"开头的username;
②.找到记录后,存储引擎并不急着回表,而是继续在存储引擎中判断这条记录的age是否为30,如果是,再去回表查询完整的记录;如果不是,不去回表了,直接继续读取下一条记录;
③.存储引擎将符合条件的数据返回给server层,此时如果还有其他非索引的查询条件,server层继续过滤,在上面的案例中,此时没有其他查询条件了,server层将最终的数据返回给客户端.假设server层还有其他的查询条件,并且这个查询条件把刚刚查到的记录过滤掉了,那么就会通过该记录中的next_record属性读取下一条记录,然后重复第②步;
这就是索引下推(Index Condition Pushdown,ICP),有效的减少了回表次数,提高了查询效率!
上面的案例索引下推的时候不仅判断age的值也判断username的值;
3>.精确匹配:
select * from user1 where username='zhangsan' and age=25;
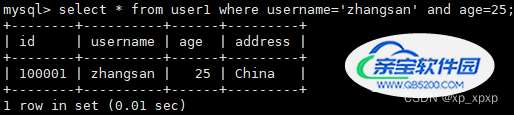
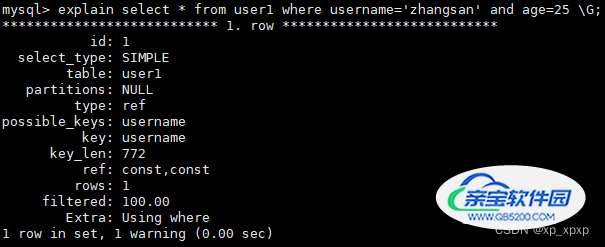
可以看到,这个查询计划也使用了索引.如果最后的Extra为null,就表示没有额外的操作了,其实这只是一个特殊的处理而已,利用搜索条件"username='zhangsan' and age=25",从存储引擎中找到数据之后,没有再去重复判断了而已;
所谓的索引下推,就是在搜索引擎中提前判断对应的搜索条件是否满足,满足了再去回表,通过减少回表次数进而提高查询效率;

