函数是可重用的程序代码块。函数的作用,不仅可以实现代码的复用,更能实现代码的一致性。一致性指的是,只要修改函数的代码,则所有调用该函数的地方都能得到体现。
在编写函数时,函数体中的代码写法和我们前面讲述的基本一致,只是对代码实现了封装,并增加了函数调用、传递参数、返回计算结果等内容。
为了让大家更容易理解,掌握的更深刻。我们也要深入内存底层进行分析。绝大多数语言内存底层都是高度相似的,这样大家掌握了这些内容也便于以后学习其他语言
Python 中函数分为如下几类:
我们前面使用的 str()、list()、len()等这些都是内置函数,我们可以拿来直接使用。
我们可以通过 import 语句导入库,然后使用其中定义的函数
Python 社区也提供了很多高质量的库。下载安装这些库后,也是通过 import 语句导入,然后可以使用这些第三方库的函数
用户自己定义的函数,显然也是开发中适应用户自身需求定义的函数。
Python 中,定义函数的语法如下:
def 函数名 ([参数列表]) :
'''文档字符串'''
函数体/若干语
要点:
(1) Python 执行 def 时,会创建一个函数对象,并绑定到函数名变量上。
(1) 圆括号内是形式参数列表,有多个参数则使用逗号隔开'
(2) 形式参数不需要声明类型,也不需要指定函数返回值类型
(3) 无参数,也必须保留空的圆括号
(4) 实参列表必须与形参列表一一对应
(1) 如果函数体中包含 return 语句,则结束函数执行并返回值;
(2) 如果函数体中不包含 return 语句,则返回 None 值。
(1) 内置函数对象会自动创建
(2) 标准库和第三方库函数,通过 import 导入模块时,会执行模块中的 def 语
【操作】定义一个函数,实现两个数的比较,并返回较大的值
def print_max(a,b):
'''实现两个数的比较,并返回较大的值'''
if a > b:
print(a,'MAX')
else:
print(b,'MAX')
print_max(10, 20)
print_max(99, -99)
#result
#20 MAX
#99 MAX上面的 printMax 函数中,在定义时写的 print_max(a,b)。a 和 b 称为“形式参数”,
简称“形参”。也就是说,形式参数是在定义函数时使用的。 形式参数的命名只要符合“标识符”命名规则即可。
在调用函数时,传递的参数称为“实际参数”,简称“实参”。上面代码中,
printMax(10,20),10 和 20 就是实际参数。
程序的可读性最重要,一般建议在函数体开始的部分附上函数定义说明,这就是“文档字符串”,也有人成为“函数的注释”。我们通过三个单引号或者三个双引号来实现,中间可以加入多行文字进行说明
【操作】测试文档字符串的使用
def print_max(a,b):
'''实现两个数的比较,并返回较大的值'''
if a > b:
print(a,'MAX')
else:
print(b,'MAX')
print(help(print_max.__doc__))
#result
#No Python documentation found for '实现两个数的比较,并返回较大的值'.
#Use help() to get the interactive help utility.
#Use help(str) for help on the str class.
#Nonereturn 返回值要点:
【操作】计算a + b 不设置返回值
def print_star(a,b):
a + b
c = print_star(4,10)
print(c)
#result
#None【操作】计算a + b 设置返回值
def print_star(a,b):
c = a + b
return c
c = print_star(4,10)
print(c)
#result
#14Python 中,“一切都是对象”。实际上,执行 def 定义函数后,系统就创建了相应的函数对象。我们执行如下程序,然后进行解释:
def print_star(n):
print("*"*n)
print(print_star)
print(id(print_star))
c = print_star
c(3)
#result
#<function print_star at 0x0000000002BB8620>
#45844000
#***上面代码执行 def 时,系统中会创建函数对象,并通过 print_star 这个变量进行引用:
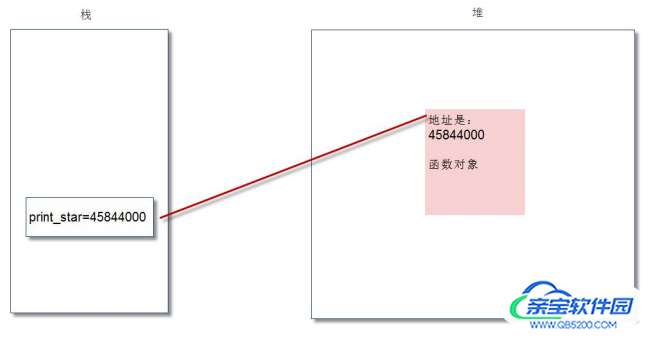
我们执行“c=print_star”后,显然将 print_star 变量的值赋给了变量 c,内存图变成了:
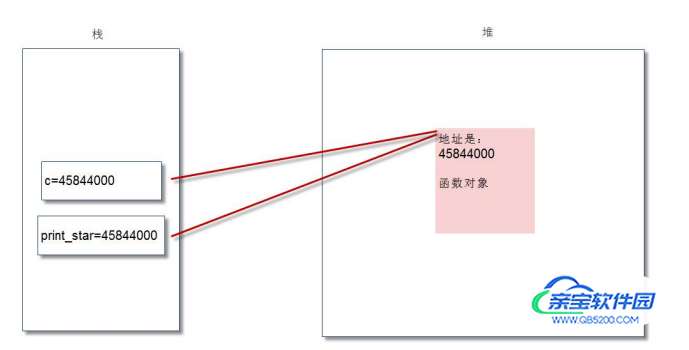
显然,我们可以看出变量 c 和 print_star 都是指向了同一个函数对象。因此,执行 c(3)和执行 print_star(3)的效果是完全一致的。 Python 中,圆括号意味着调用函数。在没有圆括号的情况下,Python 会把函数当做普通对象。
变量起作用的范围称为变量的作用域,不同作用域内同名变量之间互不影响。变量分为:全局变量、局部变量。
全局变量:
局部变量:
【操作】全局变量的作用域测试
def f1():
global a #如果要在函数内改变全局变量的值,增加 global 关键字声明
print(a) #打印全局变量 a 的值
a = 300
f1()
print(a)
#result
#100
#300【操作】全局变量和局部变量同名测试
a=100
def f1():
a = 3 #同名的局部变量
print(a)
f1()
print(a) #a 仍然是 100,没有变
#result
#3
#100【操作】 输出局部变量和全局变
a = 100
def f1(a, b, c):
print(a, b, c)
print(locals())
print('*' * 20)
print(globals())
f1(1, 2, 3)
#result
#1 2 3
#{'a': 1, 'b': 2, 'c': 3} 返回一个字典
#********************
#{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x0000023F0086CA10>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': 'c:\\Users\\chenh\\OneDrive\\Data Learn\\Python 基础\\课堂笔记\\05\\Book_code.py', '__cached__': None, 'a': 100, 'f1': <function f1 at 0x0000023F00810680>}
局部变量的查询和访问速度比全局变量快,优先考虑使用,尤其是在循环的时候。在特别强调效率的地方或者循环次数较多的地方,可以通过将全局变量转为局部变量提高运行速度
【操作】测试局部变量和全局变量效率
#测试局部变量、全局变量的效率
import time
import math
def test01():
start = time.time()
for i in range(100000000):
math.sqrt(30)
end = time.time()
print('耗时{0}'.format(end - start))
def test02():
b = math.sqrt
start = time.time()
for i in range(100000000):
b(30)
end = time.time()
print('耗时{0}'.format(end - start))
test01()
test02()
#result
#耗时7.24362325668335
#耗时6.6801464557647705
函数的参数传递本质上就是:从实参到形参的赋值操作。 Python 中“一切皆对象”,所有的赋值操作都是“引用的赋值”。所以,Python 中参数的传递都是“引用传递”,不是“值传递”。具体操作时分为两类:
字典、列表、集合、自定义的对象等
不可变对象有:
数字、字符串、元组、function
【操作】参数传递:传递可变对象的引用
b = [10,20]
def f2(m):
print("m:",id(m)) #b 和 m 是同一个对象
m.append(30) #由于 m 是可变对象,不创建对象拷贝,直接修改这个对象
f2(b)
print("b:",id(b))
print(b)
#result
#m: 1619876826368
#b: 1619876826368
#[10, 20, 30]
传递参数是不可变对象(例如:int、float、字符串、元组、布尔值),实际传递的还是对象的引用。在”赋值操作”时,由于不可变对象无法修改,系统会新创建一个对象。
【操作】参数传递:传递不可变对象的引用
a = 100
def f1(n):
print("n:",id(n)) #传递进来的是 a 对象的地址
n = n + 200 #由于 a 是不可变对象,因此创建新的对象 n
print("n:",id(n)) #n 已经变成了新的对象
print(n)
f1(a)
print("a:",id(a)) #a的内存地址并没有发生改变
#result
#n: 140717568683912
#n: 2640908885520
#300
#a: 140717568683912
显然,通过 id 值我们可以看到 n 和 a 一开始是同一个对象。给 n 赋值后,n 是新的对象。
为了更深入的了解参数传递的底层原理,我们需要讲解一下“浅拷贝和深拷贝”。我们可以使用内置函数:copy(浅拷贝)、deepcopy(深拷贝)。
浅拷贝:不拷贝子对象的内容,只是拷贝子对象的引用。
深拷贝:会连子对象的内存也全部拷贝一份,对子对象的修改不会影响源对象
【操作】测试浅拷贝和深拷贝
#测试浅拷贝和深拷贝
import copy
def testCopy():
'''测试浅拷贝'''
a = [10, 20, [5, 6]]
b = copy.copy(a)
print("a", a)
print("b", b)
b.append(30)
b[2].append(7)
print("浅拷贝......")
print("a", a)
print("b", b)
def testDeepCopy():
'''测试深拷贝'''
a = [10, 20, [5, 6]]
b = copy.deepcopy(a)
print("a", a)
print("b", b)
b.append(30)
b[2].append(7)
print("深拷贝......")
print("a", a)
print("b", b)
testCopy()
print("*************")
testDeepCopy()
#result
'''
a [10, 20, [5, 6]]
b [10, 20, [5, 6]]
浅拷贝......
a [10, 20, [5, 6, 7]]
b [10, 20, [5, 6, 7], 30]
*************
a [10, 20, [5, 6]]
b [10, 20, [5, 6]]
深拷贝......
a [10, 20, [5, 6]]
b [10, 20, [5, 6, 7], 30]
'''
传递不可变对象时。不可变对象里面包含的子对象是可变的。则方法内修改了这个可变对象,源对象也发生了变化
a = (10,20,[5,6])
print("a:",id(a))
def test01(m):
print("m:",id(m))
m[2][0] = 888
print(m)
print("m:",id(m))
test01(a)
print(a)
#result
'''
a: 3006159512640
m: 3006159512640
(10, 20, [888, 6])
m: 3006159512640
(10, 20, [888, 6])
'''函数调用时,实参默认按位置顺序传递,需要个数和形参匹配。按位置传递的参数,称为:“位置参数”。
【操作】测试位置参数
def f1(a,b,c):
print(a,b,c)
f1(2,3,4)
f1(2,3) #报错,位置参数不匹配
#result
'''
2 3 4
Traceback (most recent call last):
File "c:\Users\chenh\OneDrive\Data Learn\Python 基础\课堂笔记\05\Book_code.py", line 4, in <module>
f1(2,3) #报错,位置参数不匹配
^^^^^^^
TypeError: f1() missing 1 required positional argument: 'c'
'''我们可以为某些参数设置默认值,这样这些参数在传递时就是可选的。称为“默认值参数”。默认值参数放到位置参数后面。
【操作】测试默认值参数
def f1(a, b, c=10, d=20): #默认值参数必须位于普通位置参数后面
print(a, b, c, d)
f1(9, 8)
f1(8, 9, 19)
f1(8, 9, 19, 29)
#result
'''
9 8 10 20
8 9 19 20
8 9 19 29
'''我们也可以按照形参的名称传递参数,称为“命名参数”,也称“关键字参数”。
【操作】测试命名参数
def f1(a,b,c):
print(a,b,c)
f1(8, 9, 19) #位置参数
f1(c=10, a=20, b=30) #命名参数、
#result
'''
8 9 19
20 30 10
'''可变参数指的是“可变数量的参数”。分两种情况:
【操作】测试可变参数处理(元组、字典两种方式
def f1(a,b,*c):
print(a,b,c)
f1(8, 9, 19, 20)
def f2(a,b,**c):
print(a,b,c)
f2(8, 9, name = 'gaoqi', age = 18)
def f3(a,b,*c,**d):
print(a,b,c,d)
f3(8, 9, 20, 30, name = 'gaoqi',age = 18)\
#result
'''
8 9 (19, 20) #将*c参数放在元组中
8 9 {'name': 'gaoqi', 'age': 18} #将**c参数放在字典中
8 9 (20, 30) {'name': 'gaoqi', 'age': 18}
'''在带星号的“可变参数”后面增加新的参数,必须在调用的时候“强制命名参数”。
【操作】强制命名参数的使用
def f1(*a,b,c):
print(a,b,c)
#f1(2,3,4) #会报错。由于 a 是可变参数,将 2,3,4 全部收集。造成 b 和 c 没有赋值。
f1(2,b=3,c=4)
f1(2, 3, 4, b=10, c=100)
'''
result:
(2,) 3 4
(2, 3, 4) 10 100
'''lambda 表达式可以用来声明匿名函数。lambda 函数是一种简单的、在同一行中定义函数的方法。lambda 函数实际生成了一个函数对象。
lambda 表达式只允许包含一个表达式,不能包含复杂语句,该表达式的计算结果就是函数的返回值。
ambda 表达式的基本语法如下:
lambda arg1,arg2,arg3... : <表达式>
arg1/arg2/arg3 为函数的参数。<表达式>相当于函数体。运算结果是:表达式的运算结果。
【操作】lambda 表达式使
f = lambda a, b, c : a + b + c print(f) print(f(2, 3, 4)) ''' result: <function <lambda> at 0x0000024E1DBA0680> 9 ''' g = [lambda a : a*2, lambda b : b*3, lambda c : c*4] print(g) print(g[0](6),g[1](7),g[2](8)) ''' result: [<function <lambda> at 0x0000019D11368E00>, <function <lambda> at 0x0000019D11368F40>, <function <lambda> at 0x0000019D11368FE0>] 12 21 32 '''
功能:将字符串 str 当成有效的表达式来求值并返回计算结果。
语法参数:
eval(source[, globals[, locals]]) -> value source:一个 Python 表达式或函数 compile()返回的代码对象 globals:可选。必须是 dictionary locals:可选。任意映射对象
s = "print('abcde')"
eval(s)
a = 10
b = 20
c = eval("a + b")
print(c)
dict1 = dict(a = 100, b = 200)
d = eval("a+b",dict1)
print(d)
'''
result:
abcde
30
300
'''eval 函数会将字符串当做语句来执行,因此会被注入安全隐患。比如:字符串中含有删除文件的语句。那就麻烦大了。因此,使用时候,要慎重!!!
递归函数指的是:自己调用自己的函数,在函数体内部直接或间接的自己调用自己。递归类似于大家中学数学学习过的“数学归纳法”。 每个递归函数必须包含两个部分:
表示递归什么时候结束。一般用于返回值,不再调用自己。
把第 n 步的值和第 n-1 步相关联。
递归函数由于会创建大量的函数对象、过量的消耗内存和运算能力。在处理大量数据时,谨慎使用。
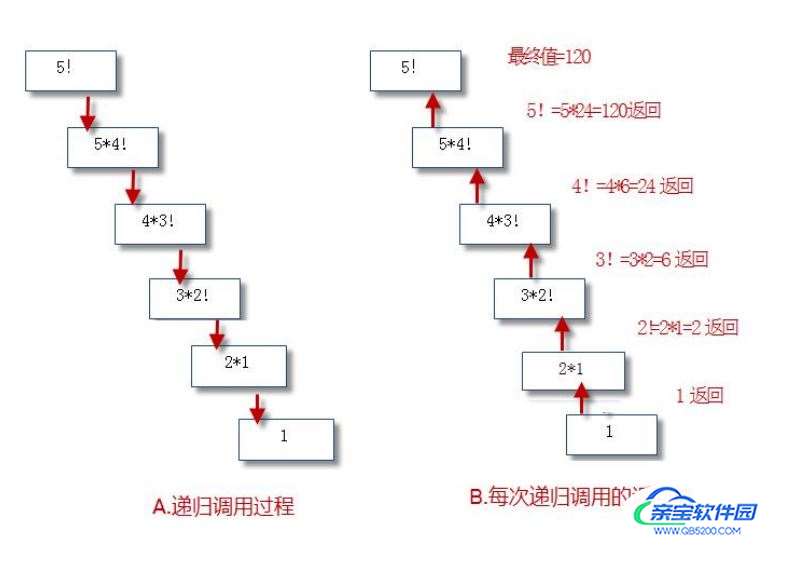
【操作】 使用递归函数计算阶乘(factorial
def factorial(n):
if n == 1:
return 1
else:
return n * factorial(n-1)
for i in range(1,11):
print(i,'!=',factorial(i))
'''
result:
1 != 1
2 != 2
3 != 6
4 != 24
5 != 120
6 != 720
7 != 5040
8 != 40320
9 != 362880
10 != 3628800
'''