我们在日常的技术交流中经常会提到Spring循环依赖,听起来挺高大尚的,那Spring到底是如何实现的呢?下面我们就来一一揭秘。
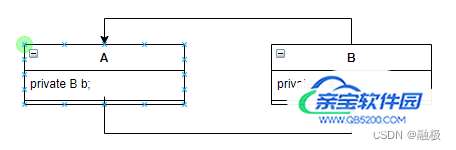
如上图所示,A对象中包含B对象的引用,同时B对象中包含A对象的引用;也就是在创建A的过程中需要同时创建B对象,这就是所谓的循环依赖。
下面是普通对象创建的流程图,也正是循环依赖产生的根因。
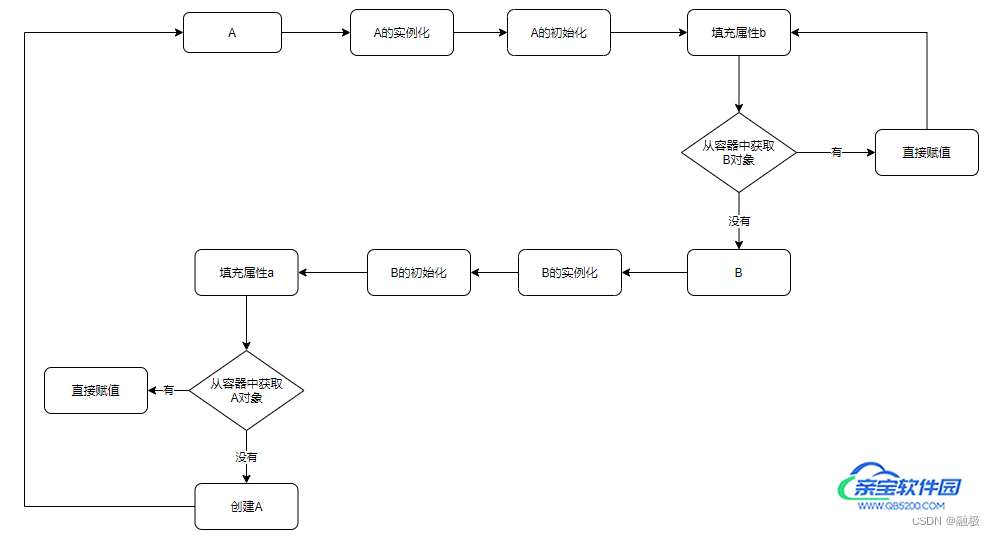
可以看到A对象创建依赖B对象创建,B对象创建依赖A对象创建,形成了闭环,造成死循环了。
上图形成了一个闭环,如果想解决这个问题,那么就必须保证不会出现第二次创建A对象这个步骤,也就是说从容器中获取A的时候必须要能够获取到。
Spring中的如何解决的呢?
在Spring中,对象的创建可以分为实例化和初始化,实例化好但未完成初始化的对象是可以直接给其他对象引用的,所以此时可以做一件事,把完成实例化但未初始化的对象提前暴露出去,让其他对象能够进行引用,就完成了这个闭环的解环操作。
这就是常说的提前暴露对象。
在spring源码的DefaultSingletonBeanRegistry.java类中
/** * 一级缓存 * 用于保存beanName和创建bean实例之间的关系,是已经实例化和初始化完成的bean */ private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256); /** * 二级缓存 * 用于保存beanName和创建bean实例之间的关系,与singletonObject的区别是这里面的bean是半成品,只完成实例化没有完成初始化; * 与singletonFactories的区别是,当一个单例bean被放到这里之后,那么当bean还在创建过程中就可以通过getBean方法获取到,可以方便进行循环依赖的检测。 */ private final Map<String, Object> earlySingletonObjects = new ConcurrentHashMap<>(16); /** * 三级缓存 * 用于保存beanName和和创建bean的工厂之间的关系,ObjectFactory就是一个Lambda表达式。 */ private final Map<String, ObjectFactory<?>> singletonFactories = new ConcurrentHashMap<>(16);
@Component
public class A {
@Autowired
private B b;
public B getB() {
return b;
}
public void setB(B b) {
this.b = b;
}
}
@Component
public class B {
@Autowired
private A a;
public A getA() {
return a;
}
public void setA(A a) {
this.a = a;
}
}
@Configuration
@ComponentScan(basePackages = "com.mashibing.selfcycle")
public class CycleConfig {
}
public class TestCycle {
public static void main(String[] args) {
final AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext(CycleConfig.class);
ac.close();
}
}1、添加A对象工厂到三级缓存
// org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory#doCreateBean
// 为避免后期循环依赖,可以在bean初始化完成前将创建实例的ObjectFactory加入工厂
// bean是实例化后的bean对象
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
// 默认最终公开的对象是bean,通过createBeanInstance创建出来的普通对象
Object exposedObject = bean;
// mbd的systhetic属性:设置此bean定义是否是"synthetic",一般是指只有AOP相关的pointCut配置或者Advice配置才会将 synthetic设置为true
// 如果mdb不是synthetic且此工厂拥有InstantiationAwareBeanPostProcessor
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
// 遍历工厂内的所有后处理器
for (BeanPostProcessor bp : getBeanPostProcessors()) {
// 如果bp是SmartInstantiationAwareBeanPostProcessor实例
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
// 让exposedObject经过每个SmartInstantiationAwareBeanPostProcessor的包装
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
}
2、填充属性b,从beanFactory中获取b对象
public Object resolveCandidate(String beanName, Class<?> requiredType, BeanFactory beanFactory)
throws BeansException {
return beanFactory.getBean(beanName);
}
3、添加B对象工厂到三级缓存
源代码流程与《1、添加A对象工厂到三级缓存,A的实例化对象到二级缓存》 一致。
4、添加B对象的属性a,从beanFactory中获取a对象
DefaultSingleBeanRegistry.java
@Nullable
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// Quick check for existing instance without full singleton lock
// 从单例对象缓存中获取beanName对应的单例对象
Object singletonObject = this.singletonObjects.get(beanName);
// 如果单例对象缓存中没有,并且该beanName对应的单例bean正在创建中
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
//从早期单例对象缓存中获取单例对象(之所称成为早期单例对象,是因为earlySingletonObjects里
// 的对象的都是通过提前曝光的ObjectFactory创建出来的,还未进行属性填充等操作)
singletonObject = this.earlySingletonObjects.get(beanName);
// 如果在早期单例对象缓存中也没有,并且允许创建早期单例对象引用
if (singletonObject == null && allowEarlyReference) {
// 如果为空,则锁定全局变量并进行处理
synchronized (this.singletonObjects) {
// Consistent creation of early reference within full singleton lock
singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null) {
// 当某些方法需要提前初始化的时候则会调用addSingletonFactory方法将对应的ObjectFactory初始化策略存储在singletonFactories
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
// 如果存在单例对象工厂,则通过工厂创建一个单例对象
singletonObject = singletonFactory.getObject();
// 记录在缓存中,二级缓存和三级缓存的对象不能同时存在
this.earlySingletonObjects.put(beanName, singletonObject);
// 从三级缓存中移除
this.singletonFactories.remove(beanName);
}
}
}
}
}
}
return singletonObject;
}
5、添加B对象到一级缓存,同时删除二级、三级缓存
org.springframework.beans.factory.support.DefaultSingletonBeanRegistry#addSingleton
protected void addSingleton(String beanName, Object singletonObject) {
synchronized (this.singletonObjects) {
// 将映射关系添加到单例对象的高速缓存中
this.singletonObjects.put(beanName, singletonObject);
// 移除beanName在单例工厂缓存中的数据
this.singletonFactories.remove(beanName);
// 移除beanName在早期单例对象的高速缓存的数据
this.earlySingletonObjects.remove(beanName);
// 将beanName添加到已注册的单例集中
this.registeredSingletons.add(beanName);
}
}
6、A对象赋值b属性,添加到一级缓存,完成A对象的创建 流程图
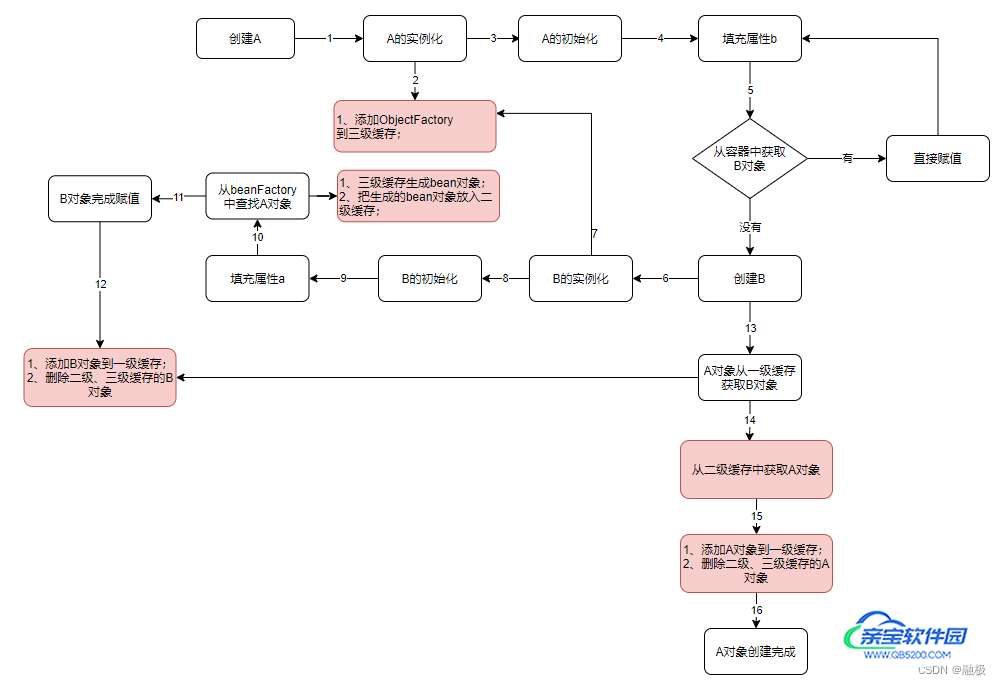
理论上使用二级缓存就能解决上面的循环依赖问题,为什么要三级缓存呢?
三级缓存存放的是objectFactory,并不是bean对象,也就是说是用来创建bean对象的。 对于动态代理对象(比如切面切到的类),需要使用三级缓存来生成代理对象。 比如,如果A,B都被切点切中了:
1、A创建时首先生成A的实例化对象a,a对象的ObjectFactory放入三级缓存。
2、填充A对象的属性b时,先实例化B对象b,b对象的ObjectFactory放入三级缓存。
3、b对象填充a属性时,如果发现a需要代理,根据三级缓存生成a的代理对象a1。
4、b对象通过a1填充a属性,在initialBean的时候走的beanPostProcessor方法是,生成b的代理对象b1,同时b1的a属性是a1。
5、a对象从一级缓存获取b1,并填充b属性。
6、a对象在initialBean的时候走的beanPostProcessor方法是,从二级缓存获取a1对象,同时a的b属性是a1。
7、最后一级缓存中存放的就是a1,b1;a1的b属性是b1,b1的a属性是a1。

