本次的7个python爬虫小案例涉及到了re正则、xpath、beautiful soup、selenium等知识点,非常适合刚入门python爬虫的小伙伴参考学习。
关于Python7个爬虫小案例的文章分为三篇,本篇为中篇,共两题,其余两篇内容请关注!
先分析:
首先,来到豆瓣Top250页面,首先使用Xpath版本的来抓取数据,先分析下电影列表页的数据结构,发下都在网页源代码中,属于静态数据

接着我们找到数据的规律,使用xpath提取每一个电影的链接及电影名

然后根据链接进入到其详情页
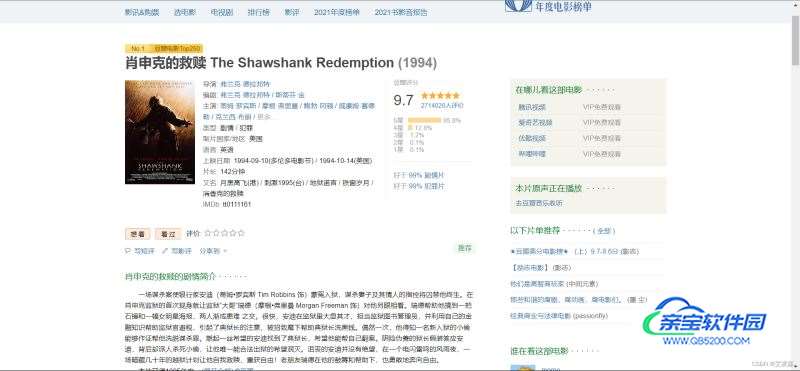
分析详情页的数据,发现也是静态数据,继续使用xpath提取数据

最后我们将爬取的数据进行存储,这里用csv文件进行存储

接着是Beautiful Soup4版的,在这里,我们直接在电影列表页使用bs4中的etree进行数据提取

最后,同样使用csv文件进行数据存储
源代码即结果截图:
XPath版:
import re
from time import sleep
import requests
from lxml import etree
import random
import csv
def main(page,f):
url = f'https://movie.douban.com/top250?start={page*25}&filter='
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.35 Safari/537.36',}
resp = requests.get(url,headers=headers)
tree = etree.HTML(resp.text)
# 获取详情页的链接列表
href_list = tree.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[1]/a/@href')
# 获取电影名称列表
name_list = tree.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[1]/a/span[1]/text()')
for url,name in zip(href_list,name_list):
f.flush() # 刷新文件
try:
get_info(url,name) # 获取详情页的信息
except:
pass
sleep(1 + random.random()) # 休息
print(f'第{i+1}页爬取完毕')
def get_info(url,name):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.35 Safari/537.36',
'Host': 'movie.douban.com',
}
resp = requests.get(url,headers=headers)
html = resp.text
tree = etree.HTML(html)
# 导演
dir = tree.xpath('//*[@id="info"]/span[1]/span[2]/a/text()')[0]
# 电影类型
type_ = re.findall(r'property="v:genre">(.*?)</span>',html)
type_ = '/'.join(type_)
# 国家
country = re.findall(r'地区:</span> (.*?)<br',html)[0]
# 上映时间
time = tree.xpath('//*[@id="content"]/h1/span[2]/text()')[0]
time = time[1:5]
# 评分
rate = tree.xpath('//*[@id="interest_sectl"]/div[1]/div[2]/strong/text()')[0]
# 评论人数
people = tree.xpath('//*[@id="interest_sectl"]/div[1]/div[2]/div/div[2]/a/span/text()')[0]
print(name,dir,type_,country,time,rate,people) # 打印结果
csvwriter.writerow((name,dir,type_,country,time,rate,people)) # 保存到文件中
if __name__ == '__main__':
# 创建文件用于保存数据
with open('03-movie-xpath.csv','a',encoding='utf-8',newline='')as f:
csvwriter = csv.writer(f)
# 写入表头标题
csvwriter.writerow(('电影名称','导演','电影类型','国家','上映年份','评分','评论人数'))
for i in range(10): # 爬取10页
main(i,f) # 调用主函数
sleep(3 + random.random())
Beautiful Soup4版:
import random
import urllib.request
from bs4 import BeautifulSoup
import codecs
from time import sleep
def main(url, headers):
# 发送请求
page = urllib.request.Request(url, headers=headers)
page = urllib.request.urlopen(page)
contents = page.read()
# 用BeautifulSoup解析网页
soup = BeautifulSoup(contents, "html.parser")
infofile.write("")
print('爬取豆瓣电影250: \n')
for tag in soup.find_all(attrs={"class": "item"}):
# 爬取序号
num = tag.find('em').get_text()
print(num)
infofile.write(num + "\r\n")
# 电影名称
name = tag.find_all(attrs={"class": "title"})
zwname = name[0].get_text()
print('[中文名称]', zwname)
infofile.write("[中文名称]" + zwname + "\r\n")
# 网页链接
url_movie = tag.find(attrs={"class": "hd"}).a
urls = url_movie.attrs['href']
print('[网页链接]', urls)
infofile.write("[网页链接]" + urls + "\r\n")
# 爬取评分和评论数
info = tag.find(attrs={"class": "star"}).get_text()
info = info.replace('\n', ' ')
info = info.lstrip()
print('[评分评论]', info)
# 获取评语
info = tag.find(attrs={"class": "inq"})
if (info): # 避免没有影评调用get_text()报错
content = info.get_text()
print('[影评]', content)
infofile.write(u"[影评]" + content + "\r\n")
print('')
if __name__ == '__main__':
# 存储文件
infofile = codecs.open("03-movie-bs4.txt", 'a', 'utf-8')
# 消息头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}
# 翻页
i = 0
while i < 10:
print('页码', (i + 1))
num = i * 25 # 每次显示25部 URL序号按25增加
url = 'https://movie.douban.com/top250?start=' + str(num) + '&filter='
main(url, headers)
sleep(5 + random.random())
infofile.write("\r\n\r\n")
i = i + 1
infofile.close()

先分析:
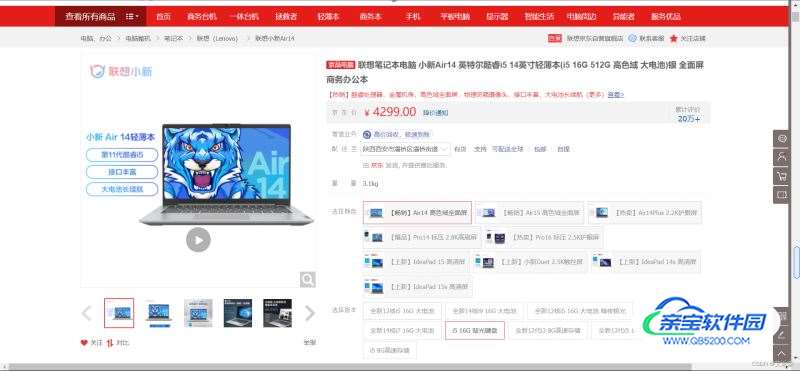
本次选取的某东官网的一款联想笔记本电脑,数据为动态加载的,通过开发者工具抓包分析即可。
源代码及结果截图:
import requests
import csv
from time import sleep
import random
def main(page,f):
url = 'https://club.jd.com/comment/productPageComments.action'
params = {
'productId': 100011483893,
'score': 0,
'sortType': 5,
'page': page,
'pageSize': 10,
'isShadowSku': 0,
'fold': 1
}
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.35 Safari/537.36',
'referer': 'https://item.jd.com/'
}
resp = requests.get(url,params=params,headers=headers).json()
comments = resp['comments']
for comment in comments:
content = comment['content']
content = content.replace('\n','')
comment_time = comment['creationTime']
score = comment['score']
print(score,comment_time,content)
csvwriter.writerow((score,comment_time,content))
print(f'第{page+1}页爬取完毕')
if __name__ == '__main__':
with open('04.csv','a',encoding='utf-8',newline='')as f:
csvwriter = csv.writer(f)
csvwriter.writerow(('评分','评论时间','评论内容'))
for page in range(15):
main(page,f)
sleep(5+random.random())
