使用pytorch对网络进行训练的时候遇到一个问题,forward阶段很快(只需要几毫秒),backward阶段却用时很长(需要十多秒)。
导致这个问题的原因很容易被大家忽视,而且网上基本上没有直接的解决方案,经过一天的折腾,总算把导致这个问题的原因搞清楚了。
导致这个问题的原因在于训练数据的浅拷贝,由于backward过程中的梯度是和模型推理过程中的张量相关的,如果这些张量在被模型使用之前没有被深拷贝,意味着backward过程的会重复从这些张量的原始内存地址中取值,这个过程非常耗时。所以为了避免这个问题,需要养成一个好习惯,就是将张量数据输入模型之前进行深拷贝
pytorch的深拷贝方式如下:
tensor_a = tensor_b.clone().detach()
backward()是反向传播求梯度,具体实现过程如下
import torch x=torch.tensor([1,2,3],requires_grad=True,dtype=torch.double) y=x**2 z=y.mean() z.backward() print(x.grad)
结果
tensor([0.6667, 1.3333, 2.0000], dtype=torch.float64)
1.必须要加上requires_grad=True才能求
2. 一般来说,需要标量才能求梯度。
3.具体过程如下:
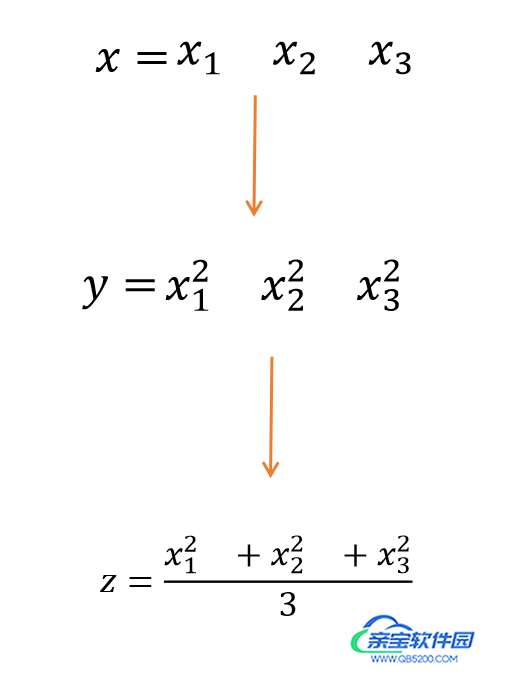
z是一个标量(1*1矩阵)分别对x1,x2,x3求偏导, 再代入x1,x2,x3的数值,就是如上程序输出的结果
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。

