如果你用过 FastAPI 的话,那么你一定知道 uvicorn,它是一个基于 uvloop 和 httptools 实现的高性能 ASGI 服务器。
其中 uvloop 采用 Cython 编写,用于替换 asyncio 中的事件循环,可以让 asyncio 速度增加 2 到 4 倍。而 httptools 是基于 C 语言实现的 HTTP 解析器,用来解析 HTTP 请求的。
本次就来聊一聊 httptools 这个模块的详细用法,至于 uvloop、uvicorn 等相关内容,后续我会一点一点补充上去,并从源码的角度全给说明白(挖了个坑)。
httptools 是一个 HTTP 解析器,它首先提供了一个 parse_url 函数,用来解析 URL。
import httptools # 第一个参数必须是 bytes 对象 url = httptools.parse_url( b"http://www.baidu.com" ) # 返回一个 URL 对象 print(url.__class__) """ <class 'httptools.parser.parser.URL'> """
那么这个 URL 对象有哪些属性呢?

通过源码可知,总共有七个属性,我们来测试一下。
import httptools
# 第一个参数是 bytes 对象
url = b"http://satori:123456@www.baidu.com:80/s?wd=koishi#flag"
url_obj = httptools.parse_url(url)
print("协议:", url_obj.schema)
print("IP:", url_obj.host)
print("端口:", url_obj.port)
print("路径:", url_obj.path)
print("查询参数:", url_obj.query)
print("锚点:", url_obj.fragment)
print("用户信息:", url_obj.userinfo)
"""
协议: b'http'
IP: b'www.baidu.com'
端口: 80
路径: b'/s'
查询参数: b'wd=koishi'
锚点: b'flag'
用户信息: b'satori:123456'
"""比较简单,如果参数不符合 URL 的标准格式,那么会抛出 HttpParserInvalidURLError 错误。
然后是 HTTP 请求报文和响应报文的解析,因为报文只是一坨字节流,需要将它解析成某个 Request 对象或 Response 对象,而 httptools 就是干这件事情的。
首先来看一下报文格式,请求报文如下:
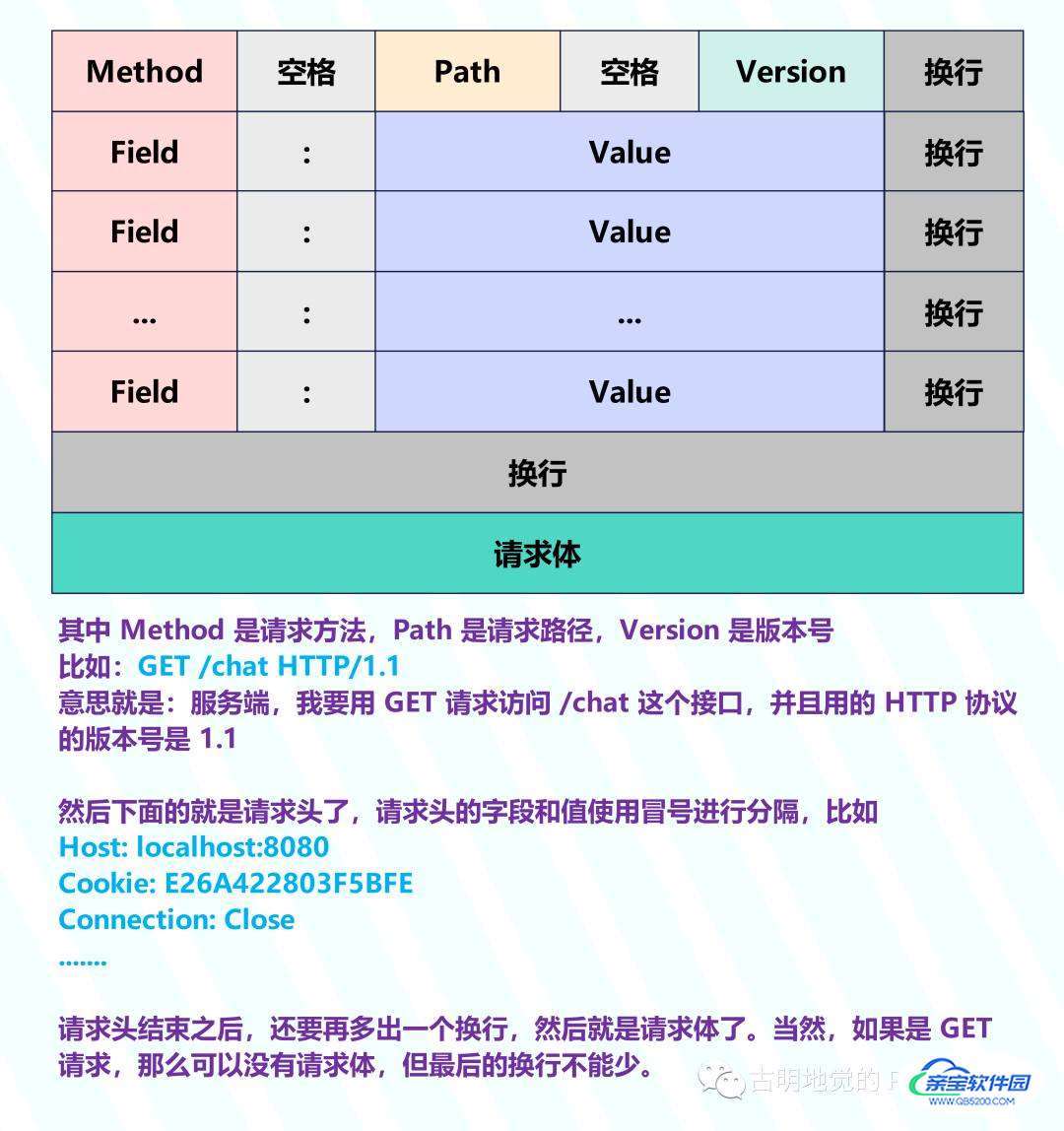
接下来是响应报文:

所以无论是请求报文还是响应报文,都由 起始行 + 请求头/响应头 + 请求体/响应体 组成。而我们在拿到原始的报文之后,也可以很方便地进行解析,从图中可以看出最后一个 Header 字段和响应体之间有两个换行,而换行用 \r\n 表示。因此我们只要按照 "\r\n\r\n" 进行 split 即可,会得到一个数组,数组的第二个元素就是请求体/响应体,第一个元素就是起始行 + 请求头/响应头。
然后对数组的第一个元素按照 "\r\n" 再进行 split,又可以得到一个数组,该数组的第一个元素就是起始行,剩余的元素就是请求头/响应头。
所以我们在拿到报文之后,完全可以自己手动解析,但 httptools 是用 C 实现的,所以速度会快一些,但干的事情是一样的。下面来看看 httptools 如何解析请求报文:
from pprint import pprint
import httptools
# 请求报文
request_payload = b"""POST /index?a=1 HTTP/1.1
Host: localhost:8080
Connection: keep-alive
Content-Length: 26
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
Accept: text/html
Accept-Encoding: gzip, deflate, sdch
Cookie: _octo=GH1.1.1989111283.1493917476; logged_in=yes
{"name":"satori","age":17}"""
class Request:
"""
将请求报文的解析结果封装成 Request 对象
"""
def __init__(self):
self.headers = {}
self.body = b""
self.path = None
def on_url(self, path: bytes):
self.path = path
def on_header(self, name: bytes, value: bytes):
self.headers[name] = value
def on_body(self, body: bytes):
self.body = body
# 实例化 Request 对象
request = Request()
# 将 request 作为参数传到 HttpRequestParser 中
parser = httptools.HttpRequestParser(request)
# 传入请求报文,进行解析
parser.feed_data(request_payload)
# 获取 HTTP 版本
print(parser.get_http_version())
"""
1.1
"""
# 是否是长链接(Connection 指定为 keep-alive)
print(parser.should_keep_alive())
"""
True
"""
# 获取请求方法
print(parser.get_method())
"""
b'POST'
"""
# 以上几个都是 HttpRequestParser 对象的方法
# 获取路径
print(request.path)
"""
b'/index?a=1'
"""
# 获取请求头
pprint(request.headers)
"""
{b'Accept': b'text/html',
b'Accept-Encoding': b'gzip, deflate, sdch',
b'Cache-Control': b'max-age=0',
b'Connection': b'keep-alive',
b'Content-Length': b'26',
b'Cookie': b'_octo=GH1.1.1989111283.1493917476; logged_in=yes',
b'Host': b'localhost:8080',
b'Upgrade-Insecure-Requests': b'1'}
"""
# Cookie 也是请求头的一部分,但在解析的时候会单独拿出来
# 再解析成一个字典,然后通过 request.cookies 获取
# 获取请求体
print(request.body)
"""
b'{"name":"satori","age":17}'
"""以上就是请求报文的解析,再来看看响应报文。
from pprint import pprint
import httptools
# 响应报文
response_payload = b"""HTTP/1.1 200 OK
Server: TornadoServer/6.1
Content-Type: text/html; charset=UTF-8
Date: Sun, 22 May 2022 17:54:11 GMT
Content-Length: 21
name: satori, age: 17"""
class Response:
"""
将响应报文的解析结果封装成 Response 对象
"""
def __init__(self):
self.headers = {}
self.body = b""
self.status = b""
def on_header(self, name: bytes, value: bytes):
self.headers[name] = value
def on_body(self, body: bytes):
self.body = body
def on_status(self, status: bytes):
self.status = status
# 实例化 Response 对象
response = Response()
# 将 response 作为参数传到 HttpResponseParser 中
parser = httptools.HttpResponseParser(response)
# 传入响应报文,进行解析
parser.feed_data(response_payload)
# 获取 HTTP 版本
print(parser.get_http_version())
"""
1.1
"""
# 是否是长链接(不指定 Connection,默认为长连接)
print(parser.should_keep_alive())
"""
True
"""
# 获取状态码
print(parser.get_status_code())
"""
b'OK'
"""
# 获取状态码对应的描述
print(response.status)
"""
b'OK'
"""
# 获取响应头
pprint(response.headers)
"""
{b'Content-Length': b'21',
b'Content-Type': b'text/html; charset=UTF-8',
b'Date': b'Sun, 22 May 2022 17:54:11 GMT',
b'Server': b'TornadoServer/6.1'}
"""
# 获取响应体
print(response.body)
"""
b'name: satori, age: 17'
"""以上就是请求报文和响应报文的解析,但如果你不是手动发送 TCP 请求的话,那么该模块基本用不到。因为对于任何一个成熟的模块而言,都具备了报文解析功能。像 requests, httpx, aiohttp 等等,以及一些 web 框架,它们在拿到报文之后会自动解析成某个对象,我们直接通过指定的属性获取即可。
而 httptools 便是 uvicorn 的报文解析器,我们在使用 uvicorn 的时候,uvicorn 内部也会自动通过 httptools 将报文解析好,而不需要我们手动解析。
因此这里介绍的 httptools 了解一下即可,我们只需要知道它是基于 C 实现的,性能非常高就行。但我们不会手动使用它,而是在使用某个框架(uvicorn)的时候,由框架自动帮我们将报文解析好。

