Puppeteer 相关介绍与安装不过多介绍,可通过以下链接进行学习
一、Puppeteer
二、爬取动态网页
1. 需求
首先,了解下我们的需求: 爬取zoomcharts 文档中 Net Chart 目录下所有访问连接对应的页面,并保存到本地

2. 研究 ZoomCharts 文档页面结构
首先,我们得研究透 ZoomCharts 页面如何加载,以及左侧导航的 DOM 树结构,才好进行下一步操作
页面首次加载

页面首次加载,左侧导航第一个目录 Introduction 高亮,从控制台可看出,该元素增加了 active 类,同时 li[data-section="net-chart"] 节点下只有一个元素节点 a
点击 Net Chart 目录
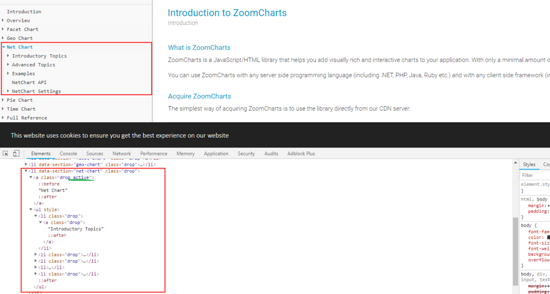
点击 Net Chart 目录, Net Chart 目录高亮,下拉显示子目录,查看控制台,其元素节点增加 active 类,并增加 ul 子元素节点, 此时,第一个子目录节点也只有一个子元素节点 a
结论
不难发现, 左侧目录是动态生成的,而不是静态写死的,只有点击父级目录,其子目录才会生成显示,同时,父级目录元素上的 drop 类表明存在子级目录
3. 编写主程序
通过上面分析,得出大概流程如下
Net Chart 目录的 DOM 树,当找到 a.drop 的元素节点,模拟鼠标点击事件 click ,生成子目录节点Net Chart 目录下所有的 a 链接,生成一个数组接下来实现每个具体流程
项目初始化
安装 puppeteer , rimraf (文件夹操作时需用到)
npm i -S puppeteer rimraf
新建 test.js 文件并引入
const puppeteer = require('puppeteer');
const chalk = require('chalk');
const path = require('path');
const https = require('https');
const fs = require('fs');
const rm = require('rimraf');
const settings = {
headless: false
}
function resolve(dir, dir2 = '') {
return path.posix.join(__dirname, './', dir, dir2);
}
async function main () {
const browser = await puppeteer.launch(settings); // 创建一个Browser 对象
try {
const page = await browser.newPage(); // 使用 Browser 创建 Page
page.setDefaultNavigationTimeout(600000);
// 监听 console
page.on('console', msg => {
for (let i = 0; i < msg.args().length; ++i) {
console.log(`${i}: ${msg.args()[i]}`);
}
});
<!-- main start -->
// main 区域
<!-- end start-->
console.log('服务正常结束')
} catch (error) {
console.log('服务出现错误:')
console.log(error)
} finally {
}
}
main()
接下来所有代码都在 main 区域内完成, 完整代码可访问github代码仓库 查看,下面仅列出每部分的思路
创建文件夹,用于保存爬取的文件
实现 Net Chart 目录下所有 a.drop 元素的点击事件
这部分涉及到DOM 操作, 只有在 page.evaluate() 中才能访问真实的 DOM 元素,同时,在 page.evaluate() 中不能直接调用外面定义的函数,可将函数传递进去,或将函数绑定到 window 对象上
await page.evaluate(async () => {
const rootNode = document.querySelector('#menu > ul > li:nth-child(5) > ul > li:nth-child(5)');
await window.walkDOM(rootNode)
})
此时,绑定到 window 对象上的 walkDOM 函数需要在 page.evaluateOnNewDocument 函数中定义才能生效
await page.evaluateOnNewDocument(() => {
// 遍历DOM
window.walkDOM = (node) => {
if (node === null) {
return
}
if (node.tagName === 'A' && node.className.indexOf('drop') > -1) {
node.click() // 点击事件
}
node = node.firstElementChild
while (node) {
walkDOM(node)
node = node.nextElementSibling
}
}
})
当Net Chart 目录下所有 a.drop 元素点击过后, Net Chart 目录下所有后代子目录都会加载生成,接下来操作就简单了
获取Net Chart 目录下所有 a 元素
document.querySelectorAll() 查找到所有 a 元素,保存到数组{href: '',text: ''} 对象遍历对象数组, 访问每一个链接,下载其HTML文件
4. 总结
第一次使用Puppeteer也是磕磕绊绊,花费不少时间,期间也参考了不少文章,还需多多练习
代码仓库

