什么是布隆过滤器
布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或 者可能存在”。
相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点 是其返回的结果是概率性(存在误差)的,而不是确切的
注意:不同的数据结构有不同的适用场景和优缺点,你需要仔细权衡自己的需求 之后妥善适用它们,布隆过滤器就是践行这句话的代表。
业务场景问题思考:
1:使用word文档时,判断某个单词是否拼写正确
2:网络爬虫程序,不去爬相同的url页面
3:垃圾邮件过滤算法如何设计?
4:缓存崩溃后造成的缓存击穿?
5:FBI,一个嫌疑人的名字是否已经在嫌疑名单上?
常规思路:
数组
链表
树、平衡二叉树、Trie
Map (红黑树)
HashMap
上述方法在数据量不大的情况下其实已经很好的解决了问题,但是存在一个很大的局限性,就是存储了元素的key值,当数据量达到千万甚至亿级别的时候,就会因为内存过大的问题无法继续,下面具体分析一下上述几个思路的局限性:
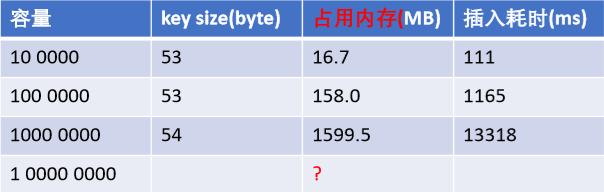
为什么不用HashMap: 值映射到 HashMap 的 Key,然后可以在 O(1) 的时间复杂度内返回结果,效率 也非常高,但是存在两个问题:1存储容量占比高,考虑到负载因子的存在,通常空间是不能被用满 2存储了key,类似URL则非常占空间,下面给出一张hashmap数量和内存空间占用、插入耗时对照表:
为什么不直接使用hash table?
哈希表的存储效率一般只有 50%(为了避免高碰撞,一般哈希存到一半时都翻倍 或采取其他策略),所以很费内存;
Hash面临的问题就是冲突。假设 Hash 函数是良好的,如果我们的位阵列长度为 m 个点,那么如果我们想将冲突率降低到例如1%, 这个散列表就只能容纳 m/100 个 元素。
解决方法较简单,使用k>1的布隆过滤器,即k个函数将每个元素改为对应于k个 bits,因为误判度会降低很多,并且如果参数k和m选取得好,一半的m可被置为 为1
由于上述局限性,布隆过滤器就出现了
布隆过滤器本质:
布隆过滤器是一个 bit 向量或者说 bit 数组(长度到底到底多长),如下所示:

注意:布隆过滤器唯一消耗内存的地方就是构建过滤器bit向量,过滤器是一开始就已经分配好固定大小不可变的空间(而向量表的大小只和设计之初元素数量级别、允许容忍的误报率有关,和元素key本身大小没有任何关系,因为过滤器只记录key对应的hash的布隆过滤器位图映射),后续每次把key新增到过滤器中不会再额外消耗任何内存。
布隆过滤器的原理是,当一个元素被加入集合时,通过K个Hash函数将这个元 素映射成一个位数组中的K个点,把它们置为1。 检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:
◼ 如果这些点有任何一个0,则被检元素一定不在;
◼ 如果都是1,则被检元素很可能(我们期望存在的概率是多少可以设置)存 在。 这就是布隆过滤器的基本思想。
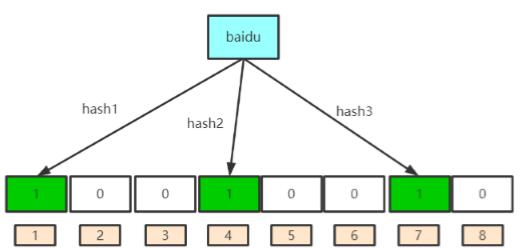
(1) 例如针对值 “baidu” 和三个不同的哈希函数分 别生成了哈希值 1、4、7,则过滤器情况如下图:
(2) 再存一个值 “tencent”,如果哈希函数返回 3、4、8 的 话,则过滤器情况如下图:
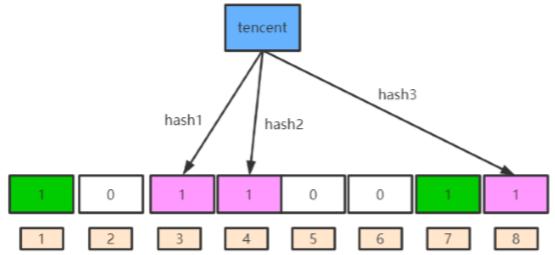
4 这个 bit 位由于两个哈希函数都返回了这个 bit 位,因此它被覆盖了。现在我们如果想查询 “yahusousuo” 这个值是 否存在,哈希函数返回了 1、5、8三个值,结果我们发现 5 这个 bit 位上的值为 0,说明没有任何一个值映射到 这个 bit 位上,因此我们可以很确定地说 “yahusousuo” 这个值不存在。而当我们需要查询 “baidu” 这个值是否存在的 话,那么哈希函数必然会返回 1、4、7,然后我们检查发现这三个 bit 位上的值均为 1,那么我们可以说 “baidu” 存在了么?答案是不可以,只能是 “baidu” 这个值可能存在。 这是为什么呢?答案更简单,因为随着增加的值越来越多,被置为 1 的 bit 位也会越来越多,这样某个值 “taobao” 即使没有被存储过,但是万一哈希函数返回的三个 bit 位都被其他值置位了 1 ,那么程序还是会判断 “taobao” 这个值存在。 -> 误判率





布隆过滤器一个很关键的点—Hash函数选择
◼ 常见的应用比较广的hash函数有MD5, SHA1, SHA256,一般用于信息安全方面, 比如签名认证和加密等。 比如我们传输文件时习惯用对原文件内容计算它的MD5值,生成128 bit的整数,通 常我们说的32位MD5值,是转换为HEX格式后的32个字符。
◼ MurmurHash是2008年发明的,相比较MD5, MurMurhash不太安全(当然MD5也被 破译了, sha也可以被破译),但是性能是MD5的几十倍; MurmurHash有很多个版 本, MurmurHash3修复了MurmurHash2的一些缺陷同时速度还要快一些,因此很多 开源项目有用,比如nginx、 redis、 memcashed、 Hadoop等,比如用于计算一致性 hash等。
◼ MurmurHash被比较好的测试过了,测试方法见 https://github.com/aappleby/smhasher, MurMurhash的实现也可以参考smhasher,或 者参考https://sites.google.com/site/murmurhash。
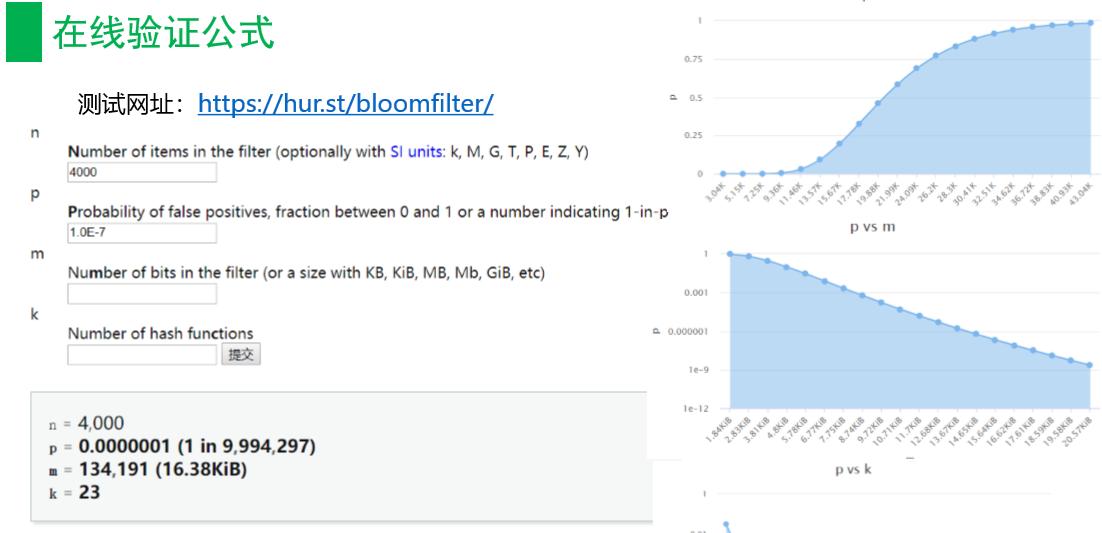
在线验证公式
测试网址:https://hur.st/bloomfilter/
可以删除元素吗?
在布隆过滤器算法中,不能因为有碰撞的可能,那即添加一个元素后,如 果设置了k个bit为1,且某个bit位碰撞后,我们删除该元素时恰恰设置该bit 位为0,则碰撞的元素无法判断,那么即不能在布隆过滤器中删除元素 。
布隆过滤器可以重置迁移吗?—布隆过滤器扩容
我们知道,布隆过滤器是不可变的,但如果布隆过滤器容量确实不够了,该怎么办呢?或者如果要每个月都删除几个月前的去重数据,该如何处理呢?这边要记录一种布隆过滤器的巧用,多个布隆过滤器组成的循环布隆过滤器。因为布隆过滤器的不可逆,我们没法重新建一个更大的布隆过滤器然后去把数据重新导入,但是可以在数据库中读取key,重新构建更大的过滤器,只是说不能过滤器之间数据迁移。这边采取的扩容的方法是,保留原有的布隆过滤器,建立一个更大的,新增数据都放在新的布隆过滤器中,去重的时候检查所有的布隆过滤器。
布隆过滤器解决缓存穿透:
缓存穿透(大量查询一个不存在的key)定义:缓存穿透,是指查询一个数据库中不一定存在的数据;
正常使用缓存查询数据的流程是,依据key去查询value,数据查询先进行缓存查询,如果key不存在或者key已经过期,再对数据库进行查询,并把查询到的对象,放进缓存。如果数据库查询对象为空,则不放进缓存。
如果每次都查询一个不存在value的key,由于缓存中没有数据,所以每次都会去查询数据库;当对key查询的并发请求量很大时,每次都访问DB,很可能对DB造成影响;并且由于缓存不命中,每次都查询持久层,那么也失去了缓存的意义。
解决方法—布隆过滤器:
将数据库中所有的查询条件,放入布隆过滤器中,当一个查询请求过来时,先经过布隆过滤器进行查,如果判断请求查询值存在,则继续查;如果判断请求查询不存在,直接丢弃。

