操作系统基本概念
首先来来说下操作系统,嗯,操作系统是计算机硬件的管理软件,是对计算机硬件的抽象,操作系统将应用程序分为用户态和内核态,例如驱动程序就位于内核态,而我们写的一般程序都是用户态,包括web服务器这些,应用程序无法直接操控硬件,只能通过系统调用,通过操作系统驱动io硬件,通过操作系统管理进程。
接下来说下文件的概念,在操作系统中,文件是对i/o的一种抽象,文件大体包括三类
普通的文件:包括二进制文件和文本文件
目录:就是普通文件的一组链表
套接字文件:用来与另一个进程进行跨网络通信的文件
套接字文件就是通常说的socket,还有值得注意的是无论打开什么文件,内核都会返回给应用程序一个文件描述符。当关闭文件后,内核释放资源,同时回收文件描述符。
进程的内存模型
每个进程都有独立的上下文,它拥有完整的虚拟内存空间。
CPU执行进程,总是在不断对进程的切换中,这种叫时分复用,而且时间很快,从而让人有一种进程并行的感觉,即单个cpu在一个时刻只能做一件事
I/O流程
说下应用程序读文件的大致流程(写文件也差不多),当一个进程想要向磁盘或者接受网络数据时,它会先发起系统调用(可以通过异常等方式),然后将程序控制权交给操作系统,
操作系统向指定的文件发起读的操作,返回给程序一个文件操作符,然后接下来就是比较有意思的地方了,因为文件读出来是需要时间的,文件读出来后会存到内核的缓冲区中(DMA),然后中断提醒CPU,CPU再由内核缓冲区读取到用户进程中,在这个过程中,这段时间里,用户进程可以有阻塞,非阻塞,同步,异步各种状态
linux的I/O模型
网络IO的本质是socket的读取,socket在linux系统被抽象为流,IO可以理解为对流的操作。对于一次IO访问(以read举例),数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。所以说,当一个read操作发生时,它会经历两个阶段:
第一阶段:等待数据准备 (Waiting for the data to be ready)。 第二阶段:将数据从内核拷贝到进程中 (Copying the data from the kernel to the process)。
对于socket流而言,
第一步:通常涉及等待网络上的数据分组到达,然后被复制到内核的某个缓冲区。 第二步:把数据从内核缓冲区复制到应用进程缓冲区。
linux的五种网络i/o模型
同步的概念就是在数据复制到用户进程的这段时间内,用户进程是不干活
异步是在这段时间内,用户进程会继续执行它后续的工作
先在同步异步的基础上进行简单的分类
同步模型(synchronous IO)
- 阻塞IO(bloking IO)
- 非阻塞IO(non-blocking IO)
- 多路复用IO(multiplexing IO)
- 信号驱动式IO(signal-driven IO)
异步IO(asynchronous IO)
接下来进行分类的介绍
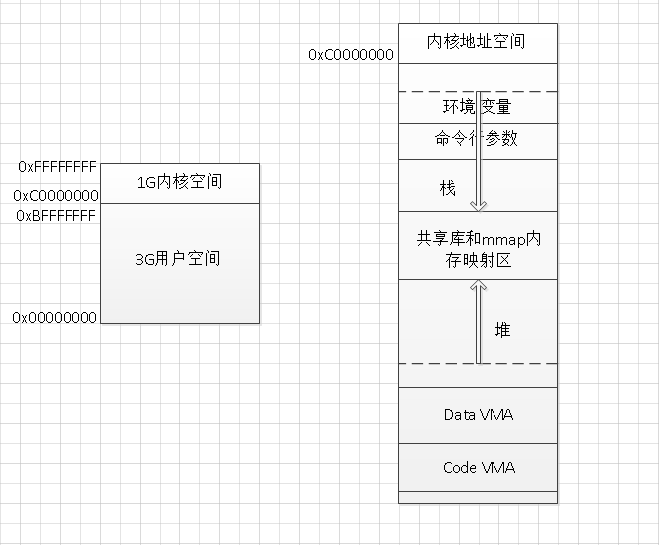
阻塞I/O
阻塞i/o就是整个过程用户进程都是阻塞,它发起系统调用后就被挂起了,直到数据被搬运到缓冲区中,然后数据从缓冲区读进用户进程,它才被唤醒,真个过程它都处于挂起状态(什么都不干)
非阻塞i/o
用户进程发起系统调用后,它没有被挂起,而是继续执行,但它要不断轮询看数据是否运到内核了,数据到了内核后,用户进程将数据从内核读取到用户进程

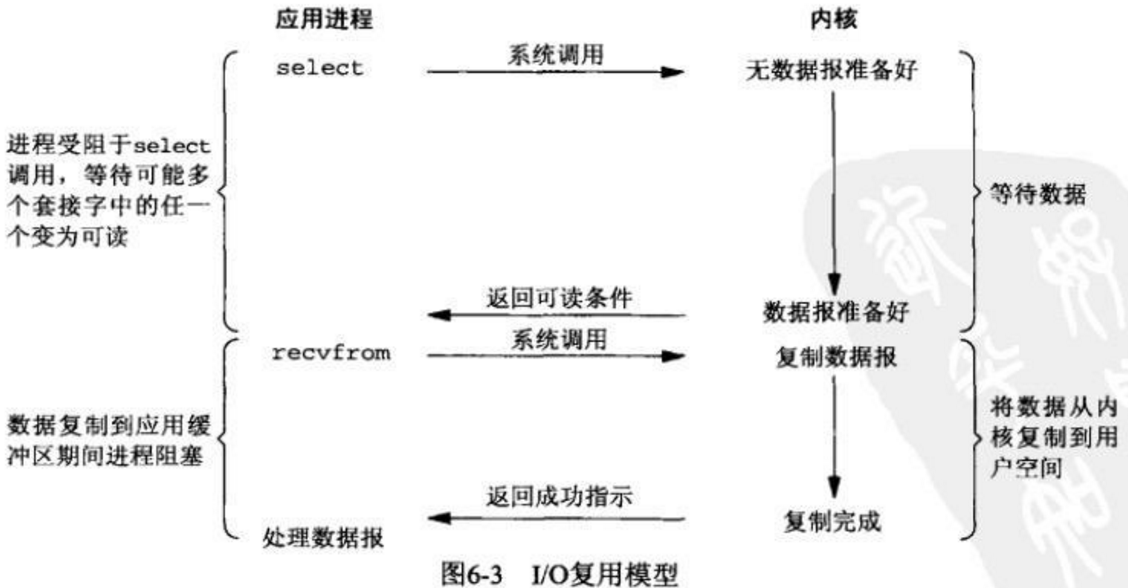
多路复用I/O
多路复用I/O比较复杂,它整个过程也是阻塞的,但不同的是它可以阻塞多个i/o,同时阻塞多个socket连接,有epoll,,poll,select等,epoll是linux最高效的,多路复用的特点是通过一种机制一个进程能同时等待多个IO文件描述符,内核监视这些文件描述符(套接字描述符),其中的任意一个进入读就绪状态,select, poll,epoll函数就可以返回。
select,poll,epoll都是内核状态的函数调用
用户进程发起系统调用后,处于挂起状态,同时监听多个socket连接,只要有其中有一个数据到达内核,用户进程就被唤醒工作,然后将数据从内核读取到用户进程,其实就是由epoll,select同时监听多个io对象,当io对象发生变化的时候,就通知用户进程读写数据,进行操作
即多个io对象复用一个进程,这样可以很充分的利用阻塞的这段时间
IO多路复用是同步阻塞模式
异步驱动I/O
这个理论上是最好的,但在linux系统中很难实现
信号驱动i/o
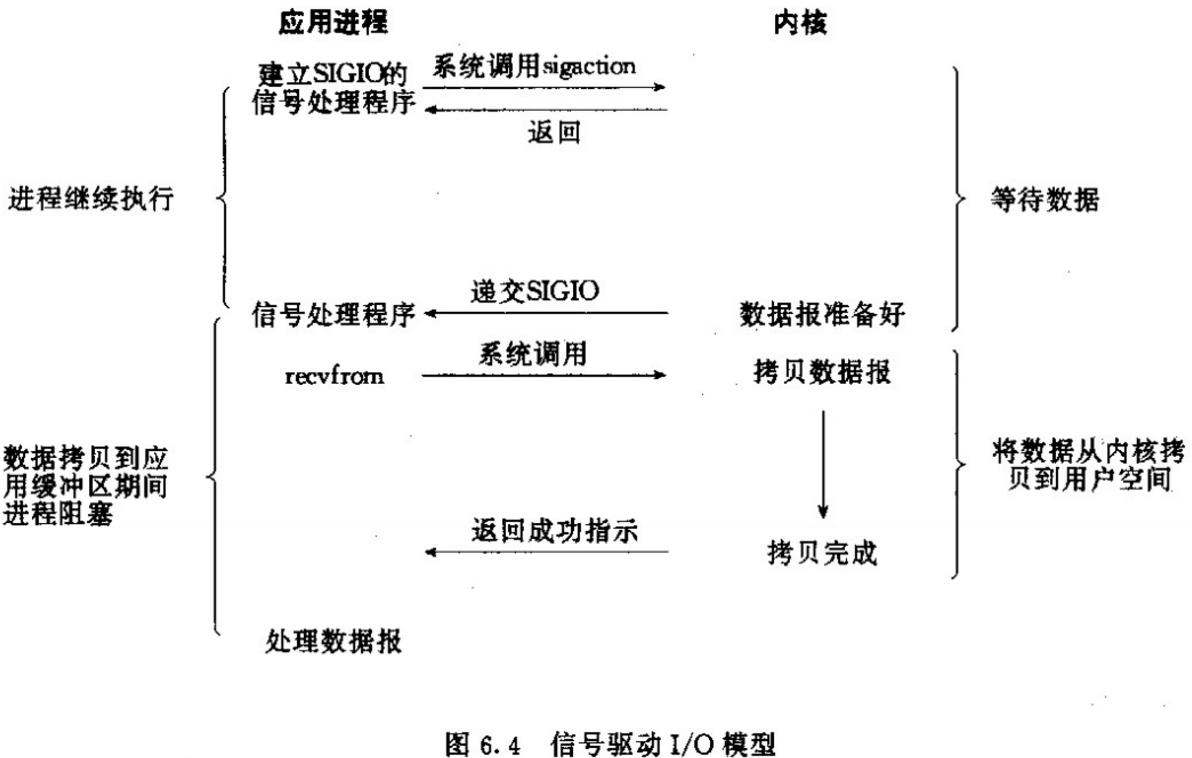
这个很少使用到
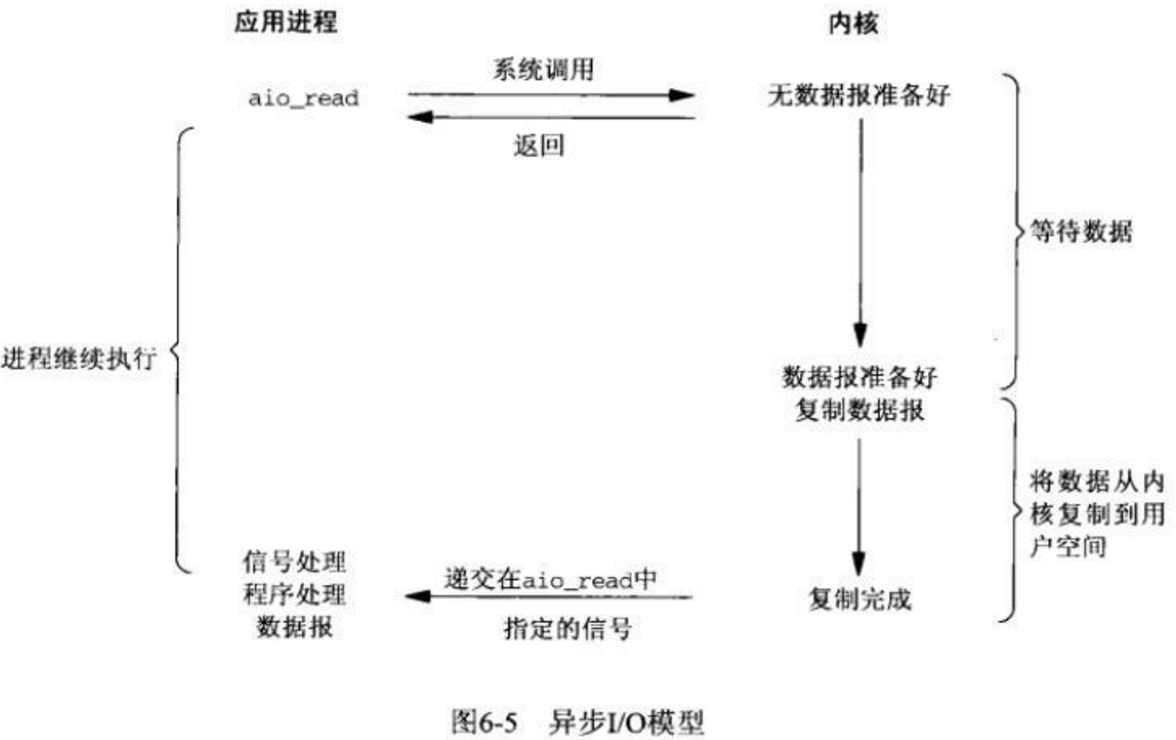
异步IO
异步io在linux中很难实现,但也有一种模拟异步io的方法即多线程和同步阻塞io进行模拟,设置一个主线程,用其它线程进行同步io操作,当io完成时通知主线程去读取进程中的数据,进行后续操作,因为是同一个进程,所以可以共享内存资源。进而实现类似异步io的效果,在linux中有libev,libeio这样的异步io实现库,而在windows,则使用了iocp,可以说异步io的核心就是在子线程上执行io操作,在执行完毕后通知调用者提取相关数据。只不过linux是用户层的线程池,而iocp是内核的线程池。
Node模型
首先说下常见的模型要么是单进程多线程,要么是多进程单线程,node是属于后者
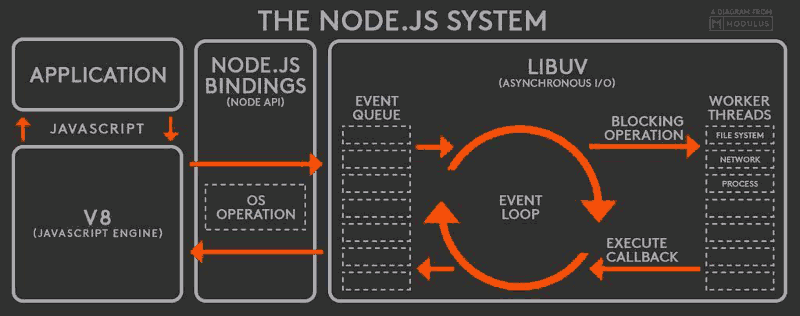
node中最重的就是包含了libuv这个,node的所有io操作都是通过它来实现的,libuv实现了异步IO,libuv中包含一个事件队列(可以理解为就是主线程),如果是网络io,它会使用epoll这种io多路复用的方式(在linux中)对io进行处理,而对于磁盘的io操作,它会采用多线程+阻塞io的方式进行io操作,它读写完数据后就将数据返回给js引擎。从而实现io操作。
最后提一点epoll这种io多路复用模型使用的很广,redis,nginx,都不同程度使用了它,它2者也可以归为多进程单线程这种模型。

