一、前言
在图像处理领域,卷积神经网络(Convolution Nerual Network,CNN)凭借其强大的性能取得了广泛的应用。作为一种前馈网络,CNN中各输入之间是相互独立的,每层神经元的信号只能向下一层传播,同一卷积层对不同通道信息的提取是独立的。因此,CNN擅长于提取图像中包含的空间特征,但却不能够有效处理时间序列数据(语音、文本等)。
时序数据往往包含以下特性:
- 输入的序列数据长度是不固定(如机器翻译,句子长度不固定)
- 不同时刻的数据存在相互影响(如前一时刻的事实会影响后续时刻的推断)

拿到一个小球,我们并不知道它下一步会往哪一个方向运动,到当我们获取了小球前几个时刻的位置,我们就能推断出小球下一步的运动方向。前一时刻的信息影响了后续时刻的推测,不同时刻下小球的位置信息就是时间序列数据的一种。
二、循环神经网络
与前馈网络不同,循环神经网络(Recurrent Nerual Network,RNN)在隐藏层中带有自反馈的神经元对前面的信息进行记忆并应用于当前输出的计算中,即神经元在接收当前数据输入的同时,也接收了上一个隐藏层的输出结果,一直循环直到所有数据全部输入。RNN能够利用历史信息来辅助当前的决策,它也可以根据任务的不同,灵活地改变输出的个数。
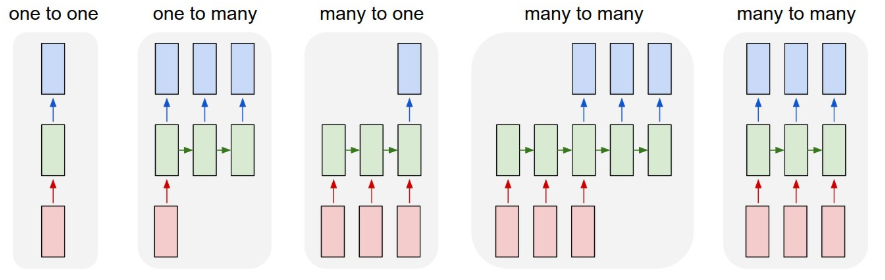
- one to one:一个输入对应一个输出;
- one to many:一个输入对应许多输出,比如图像理解,输入一张图像,让机器试着描述图像内容;
- many to one:语句情感分析,输入句子,对语句中所包含的情感进行分类;
- many to many:机器翻译。
在RNN中,隐藏层状态(Hidden State)通俗的理解就是隐藏层神经元将输入计算后的输出值,这一输出值不仅是当前时刻神经元的输出,也是后一时刻神经元的输入。

其中,ht 为t时刻的隐藏层状态,Xt 为时间序列数据,φ为激活函数(如双曲正切函数、sigmoid函数等),U和W分别为在前一个时刻隐藏层和在当前时刻输入的系数矩阵。
整个RNN的计算图如下图所示:
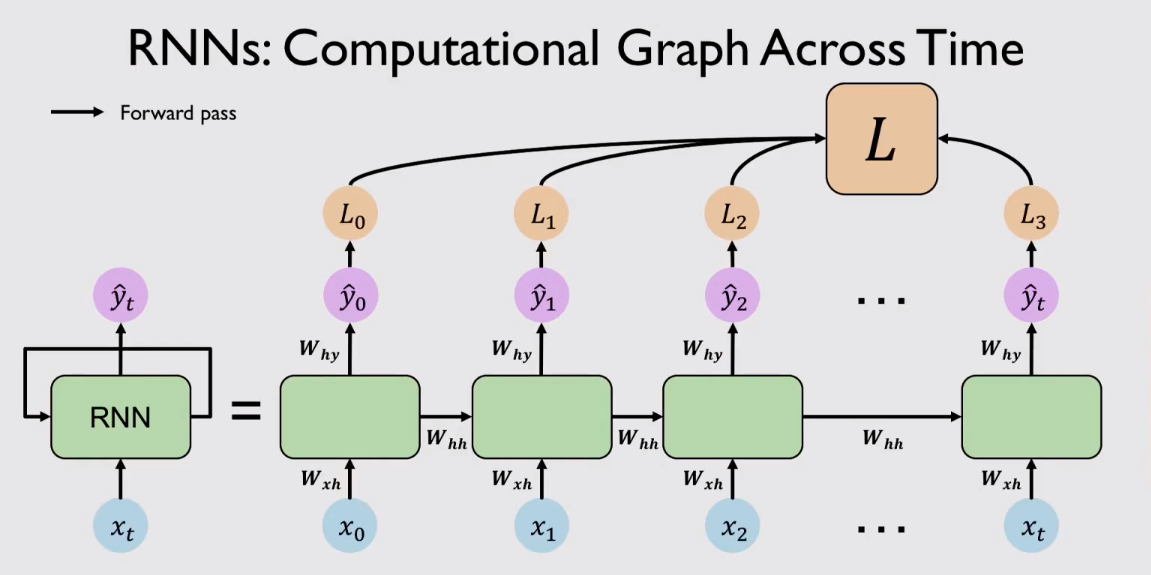
参数共享和循环反馈的设计机制,使得 RNN 模型理论上能够处理任意长度的时间序列,因此RNN非常适用于时间序列数据的分析应用中。理论上,RNN可以无限拓展他的隐藏层,去学习更长序列数据。但是过多的层数不仅会使模型训练速度变慢,而且也会带来“梯度消失”或“梯度爆炸”的问题,造成 RNN 无法获取长时间依赖信息,从而丧失了利用长距离历史信息的能力。
三、长期依赖(Long-Term Dependencies)的问题
对于间隔较长的时间序列数据,在实际应用中RNN往往在学习长距离历史信息表现欠佳。
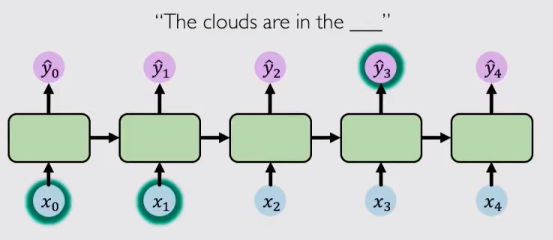
以下面这个例子来说,“The clouds are in the ”最后我们要模型去输出这个词,历史信息告诉模型前面出现了“clouds”,那么模型就可以根据历史信息来推断出要输出“sky”。因为这里的相关信息和预测词的位置之间只有非常小的间隔,如下图所示:
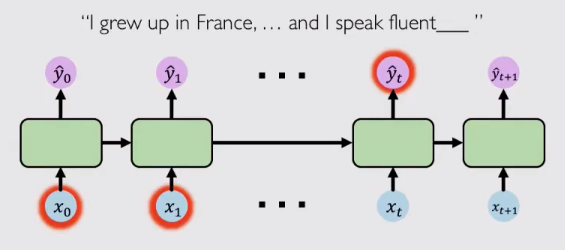
但是在现实应用不仅仅有这种简单的预测任务,还存在大量复杂的时间序列数据,这些数据需要模型去记忆更早的历史信息去完成推断。比如“I grew up in France,...and I speak fluent ”,要去推测这个词,模型需要记忆“France”这一历史信息,但它与输出位置间隔太远,由于“梯度消失”的问题,这么远的历史信息很难被有效传递。
因此,随着间隔的增大,传统RNN在面对这样时间序列数据的建模效果往往差强人意。目前,存在一定方法能够缓解“梯度消失”来解决长期依赖问题,如
- 用RELU函数替换sigmoid函数作为激活函数
- 权重初始化(权重系数矩阵初始化为单位矩阵,偏置系数矩阵初始化为0)
- 使用带有门控(gate)的更复杂循环单元去记录长期历史信息(如LSTM,GRU等)
四、长短时记忆网络(Long Short-Term Memory Network)
LSTM就是为了解决间隔较远的历史信息无法有效传递这一问题,它是利用门控单元(Gated Cell)来控制长期历史信息的传递过程。

门控(Gate)这一概念是指控制循环单元内信息的增加或删除的一种结构,它选择性地让信息通过,例如下图,一个简单的sigmoid函数加哈达玛积即可实现这样一个控制信息传递的过程,sigmoid输出为0表示完全舍弃,输出为1表示完全通过。

LSTM就是靠着sigmoid函数来控制信息的传递过程,LSTM循环单元中一般包含三个门控单元,即遗忘门、输入门和输出门。
不同于传统RNN,LSTM在每个循环单元中添加了单元状态(Cell State)来选择性地记忆过去传递的信息。一个循环单元不仅要接收上一次时间步骤传递出的Hidden State,也要接收传递出的Cell State。通俗的理解,Hidden State是到目前为止我们所看到的总体信息,而Cell State是历史信息的选择性记忆。
LSTM的工作方式可以抽象地分为以下四步:
- 遗忘(Forget)
- 存储(Store)
- 更新(Update)
- 输出(Output)
1、遗忘(Forget)
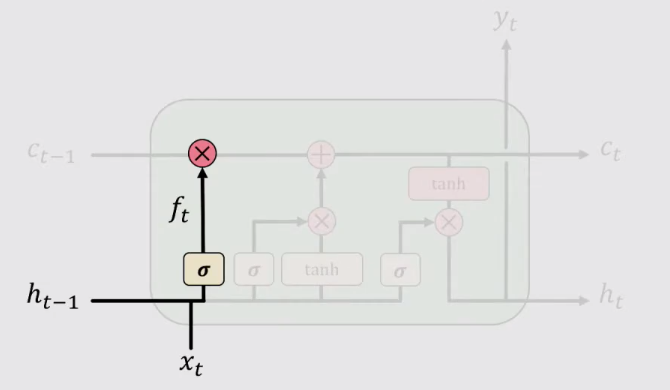
接收上一时间步骤的Hidden State ht-1 和当前输入数据Xt,将他们计算后的值通过sigmoid激活函数,计算遗忘门的信息,来确定需要遗忘的信息。
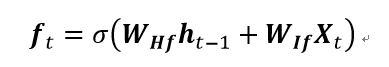
2、存储(Store)
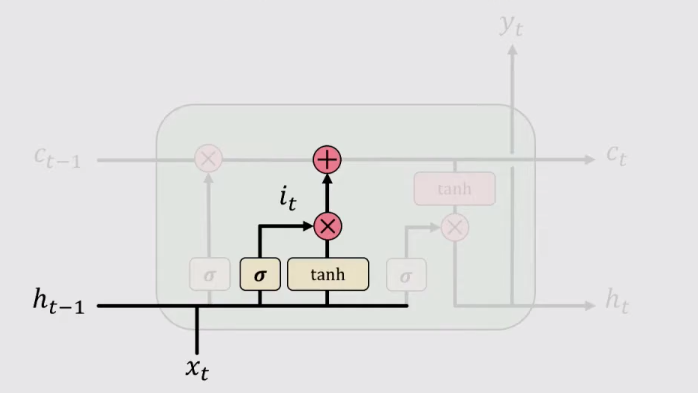
计算输入门的值 it 并将其与整体信息 St 计算哈达玛积。在这一步,之所以要在输入门的值再与整体信息 St 计算哈达玛积的原因是,门控结构(Gate)输出的介于0-1之间的数字,相当于图像的掩膜(mask),与整体信息结合在一起才能确定输入的信息。
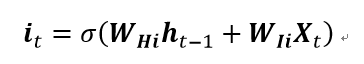
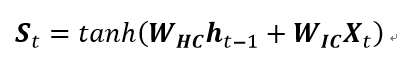
3、更新(Update)
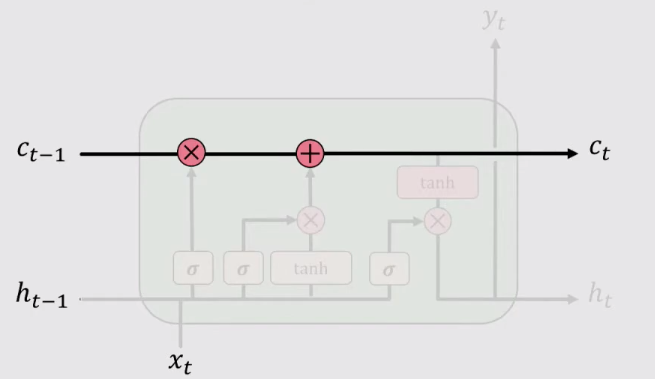
单元状态(Cell State)表示的是到t时刻,循环单元选择性记忆的信息。对它进行更新就需要遗忘 t-1时刻的单元状态Ct-1,并加上当前时刻输入信息,这样更新Cell State。

4、输出(output)
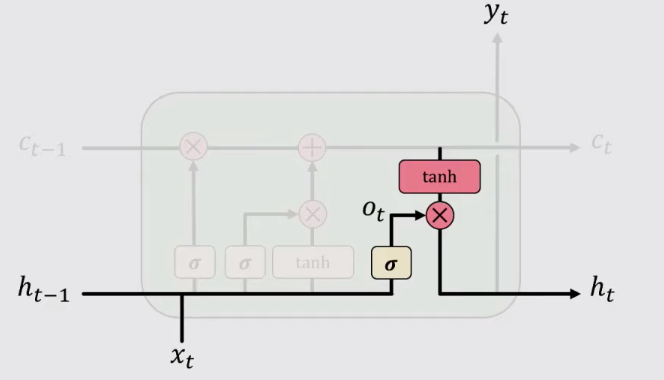
到了输出这一步,循环单元计算输出门的值,并将当前时刻下已经选择性记忆的信息 Ct 拿出来做“掩膜”,来得到输出的Hidden State Ht

四、小结
学习LSTM的关键在于理解单元状态(Cell State)的意义。传统RNN中的Hidden state保留的是到当前时刻为止所积攒的所有信息,而Cell State保留的是经历过遗忘和输入的信息。LSTM有效地解决了 RNN 模型训练时出现的梯度“爆炸”和梯度“消失”问题在很多应用中都取得了不错的效果。
参考资料
https://www.quora.com/How-is-the-hidden-state-h-different-from-the-memory-c-in-an-LSTM-cell
MIT.Introduction to Deep Learning:Deep Sequence Modeling,2020

