CACE全称Compiler Average Casual Effect或者Local Average Treatment Effect。在观测数据中的应用需要和Instrument Variable结合来看,这里我们只讨论CACE的框架给随机AB实验提供的一些learning。你碰到过以下低实验渗透低的情况么?
- 新功能入口很深,多数进组用户并未真正使用新功能,在只能在用户层随机分流的条件下,如何计算新功能的收益
- 触达策略,在发送触达时进行随机分组,但触达过程存在损失,真正触达的用户占比很小,如何计算触达收益
## 背景
当然如果你的新策略渗透非常低,可能你的策略本身就需要调整。但就一些本身旨在提高少数用户体验的策略,或者策略初期试水的情况,CACE可能会比AB组的整体差异(ATE)更合适作为你实验的衡量指标。因为它可能会告诉你策略对少部分用户产生了显著受益,你要做的只是去继续迭代扩大用户渗透而已。
**ATE关注的是整个实验组-对照组的收益,当然也会是策略全量上线后预估能拿到的对全用户的收益。CACE估计的则是实验对真正触达的用户预估产生的收益。**注意这部分用户的收益并不能泛化到全用户,其一实验对不同用户的影响不同,其二策略的渗透率天然有限。往往渗透率越低对用户的选择性越强,触达的用户和整体用户的差异更大,计算出的CACE更难泛化到全用户上
## CACE框架
让我们回忆下ATE的计算, T是treatment,例如app增加的新功能, Y是outcome,比如用户app使用时长,实验效果一般通过ATE估计,因为这会最贴近实验全量后在全用户上拿到的最终受益
$$
ATE = E(Y|T =1) - E(Y|T=0)
$$
CACE额外加入了变量W实验渗透,也就是用户是否真正使用过新功能,CACE估计的是实验对真正触达的用户产生的收益。如果你的实验渗透100%那CACE=ATE,随着实验渗透的降低,理论上CACE会比ATE越来越高,因为部分用户的收益被全体用户稀释。
说了这么多CACE咋算嘞?别急先来展示2种错误却经常被使用的方法
1. Per-protocol Analysis = 实验组渗透用户 - 对照组全用户
$$
E(Y|Z=1, W(z=1)=1) - E(Y|Z=0)
$$
2. As-treated Analysis = 实验组渗透用户 - 实验组未渗透用户
$$
E(Y|Z=1, W(z=1)=1) - E(Y|Z=1, W(z=1)=0)
$$
上面两种方法都同时踩中了一个叫做Selection Bias的坑,也就是功能渗透本身是受到用户行为/主观意愿影响,因此会存在用户选择。从而导致渗透用户既不能代表全用户,也会和未渗透用户存在差异。真要在错的里面找个对的出来,Per-protocol一般更好一点。
## CACE计算
###用户定义
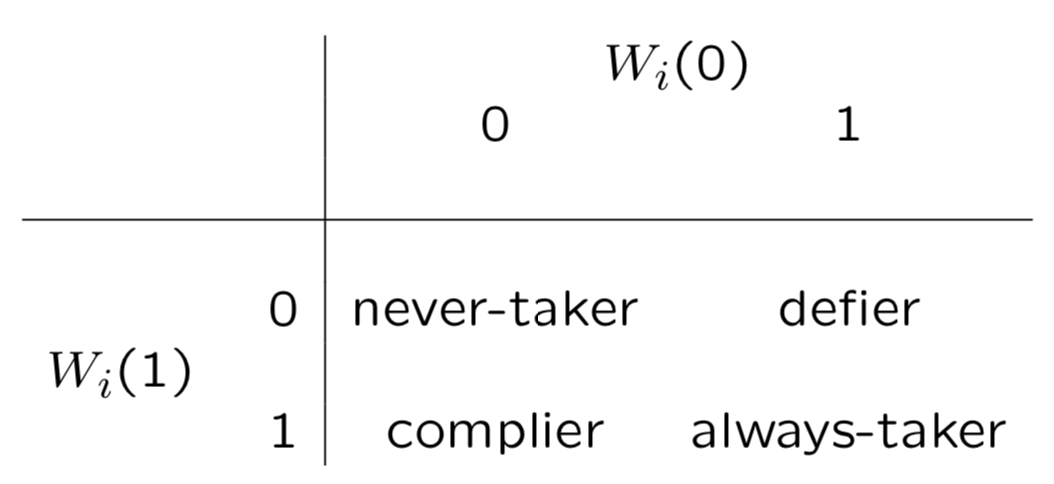
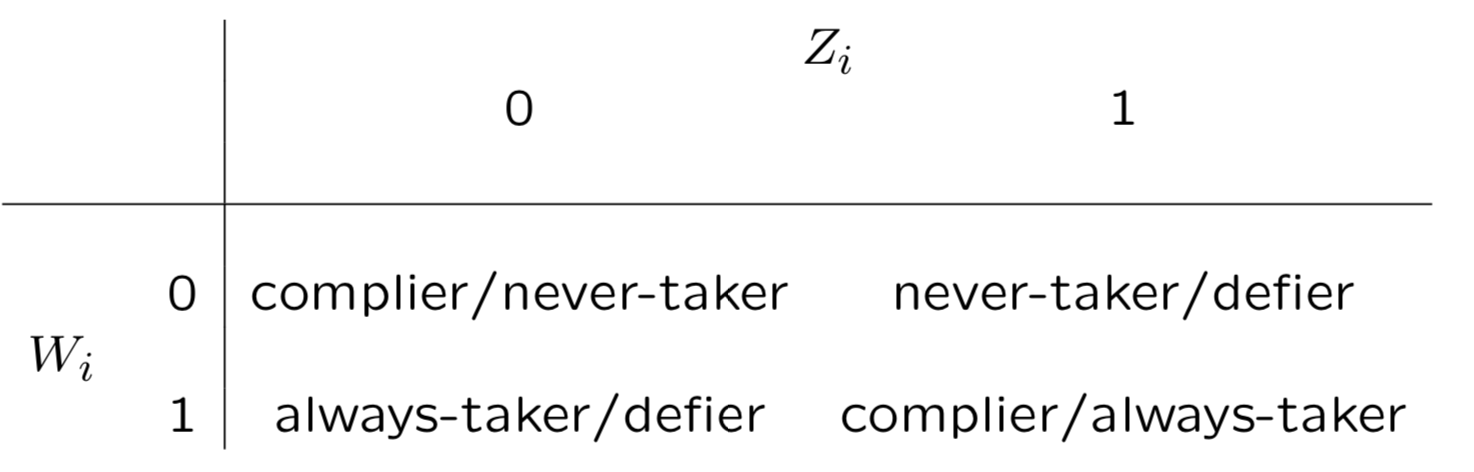
CACE把用户分为4类, compiler, never-taker, always-taker, defier,简单说compiler是给药就吃不给就不吃,never-taker是打死也不吃,always-taker是没事就吃药,defier是不给我药我偏要吃。这四类人群可以通过W和Z进行定义如下
### 假设
要想CACE的计算成立,还需要满足3条假设
**1. Independence**
这个在随机AB实验中一定成立,但在观测数据中需要额外寻找Instrument variable这里不予讨论
$$
Z_i \perp (Y_i(0),Y_i(1),W_i(0),Y_i(1))
$$
**2. Exclusion Restriction**
这个假设即便在随机AB实验中也不一定成立,**因此需要基于策略本身进行判断**,基本原则就是Treatment分组本身对用户没有影响,只有确实被Treatment渗透的用户才受到影响。假设2保证了never-taker,always-taker在实验组和对照组中的表现一致。
$$
Y(z,w) = Y(z',w) \,\,\, \text{for all z, $z'$,w}
$$
印象中有看到过假设2不成立应该如何计算CACE的paper,不过还没碰到过类似情况,以后有用到再加上吧。
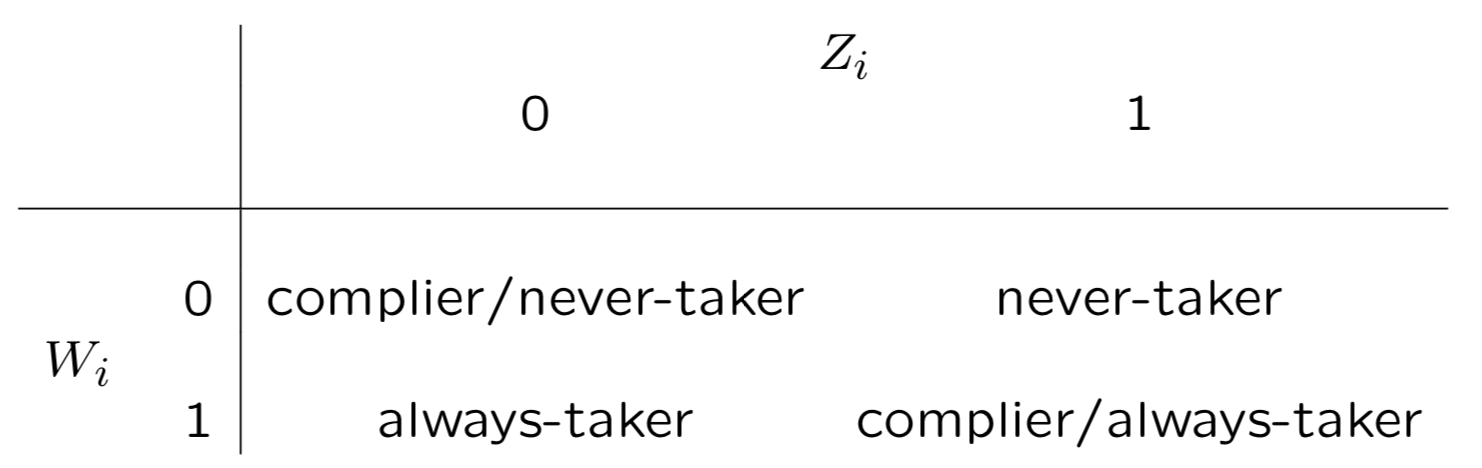
**3. Monotonicity/No-Defier**
单调假设在绝大多数情况下都成立,也就是T对W是正效应,不存在Defier。 这时W和Z对应的人群会被简化为以下,never-taker指向人群就是实验组未渗透人群因此可以直接估计
$$
W_i(1)>W_i(0)
$$
### 计算
随机实验的假设保证了compiler, always-taker, 和never-taker在对照组和实验组中的占比是相同的,因此我们可以直接计算出compiler, always-taker, never-taker在人群中的占比,如下
$$
\begin{align}
\pi_a &= p(W(0)=W(1)=1) = E(W|Z=0)\\
\pi_c &= p(W(0)=0,W(1)=1) = E(W|Z=1) - E(W|Z=0)\\
\pi_n &= P(W(0)=W(1)=0) = 1- E(W|Z=1) \\
\end{align}
$$
因为实验组中未渗透用户一定是never-taker, 对照组中渗透用户一定是always-taker(在一些功能型随机实验中并不存在always-taker),因此这部分用户的表现可以直接拿到
$$
\begin{align}
E(Y|W=1,Z=0) &= E(Y(1)|always)\\
E(Y|W=0,Z=1) &= E(Y(0)|never)\\
\end{align}
$$
我们以此为突破口就可以计算得到compiler的CACE,先把对照组和实验组的人群进行分解如下
$$
\begin{align}
E(Y|Z=0) &= \pi_a * E(Y(1)|always) + \pi_n * E(Y(0)|never) +
\pi_c * E(Y(0)|compiler) \\
E(Y|Z=1) &= \pi_a * E(Y(1)|always) + \pi_n * E(Y(0)|never) +
\pi_c * E(Y(1)|compiler) \\
\end{align}
$$
很显然AB组的差异只来源于compiler的差异,其实在没有always taker的情况下, CACE只是按实验组渗透等比的放大了组间收益而已
$$
\begin{align}
CACE &= E(Y(1)|compiler) - E(Y(0)|compiler)\\
&= \frac{E(Y|Z=1)-E(Y|Z=0)}{\pi_c}\\
&= \frac{E(Y|Z=1)-E(Y|Z=0)}{E(W|Z=1) - E(W|Z=0)}
\end{align}
$$
对于显著性的计算,我个人更偏向于只把CACE应用在原始ATE已经显著的情况下,以避免针对一些没有意义的波动数据进行分析,CACE只是用于估计渗透用户的绝对收益。当然如果想要计算CACE的显著性,可以用Bootstrap来拿到SE。当然因为CACE本身是ratio,也可以用更科学的方法来计算SE,具体细节可以参照Ref4。
用这个方法难免会被问到这部分用户的收益能否泛化到全体用户,理论上是不能的,但也不能一锤子打死。一个比较简单直观的方法是去比较$E(Y(0)|compiler)$,$E(Y(0)|always)$,$E(Y(0)|never)$之间是否存在显著差异,差异越大,能泛化的可能一般是越小的。
对AB实验的高端玩法感兴趣?

