# seldom之数据驱动
如果自动化某个功能,测试数据不一样而操作步骤是一样的,那么就可以使用参数化来节省测试代码。
seldom是我在维护一个Web UI自动化测试框,这里跟大家分享seldom参数化的实现。
GitHub:https://github.com/SeldomQA/seldom
#### 参数化测试用例
```python
import seldom
from seldom import data
class BaiduTest(seldom.TestCase):
@data([
("case1", "seldom"),
("case2", "selenium"),
("case3", "unittest"),
])
def test_baidu(self, name, keyword):
"""
参数化测试用例
:param name: 用例名称
:param keyword: 搜索关键字
"""
self.open("https://www.baidu.com")
self.type(id_="kw", text=keyword)
self.click(css="#su")
self.assertTitle(keyword+"_百度搜索")
if __name__ == '__main__':
seldom.main()
```
通过`@data()` 装饰器来参数化测试用例,用法非常简单。
> 将测试数据写代码里面并不是特别优雅的方式,尤其在数据比较多长时间。那么通过数据文件管理可能会更加优雅。
#### 读取csv文件
seldom支持csv文件的数据解析为 list。
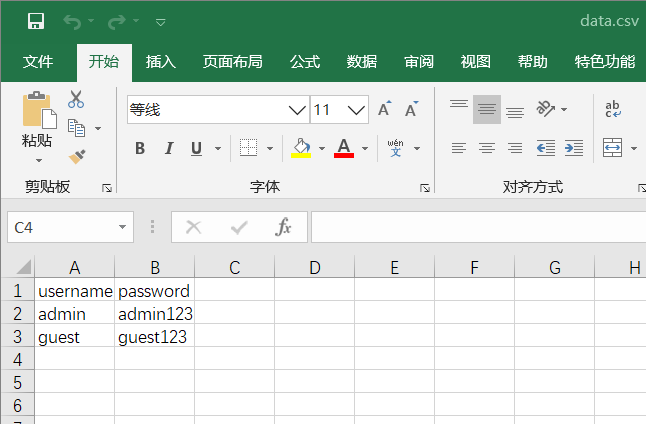
读取CSV文件中的数据。
```python
import seldom
from seldom import data
from seldom import csv_to_list
class YouTest(seldom.TestCase):
@data(csv_to_list(file="data.csv", line=2))
def test_login(self, username, password):
"""a simple test case """
self.open("https://login.xxx.com")
self.type(id_="user", text=username)
self.type(id_="pawd", text=password)
# ...
```
`csv_to_list()` 方法CSV文件内容转化为list。
* file: 指定csv测试文件。
* line: 指定从第几行开始读取,默认第一行。
> CSV文件不支持多个Sheet,这就要求一个组数据必须创建一个单独JSON文件,如果数据多了之后就需要创建许多单独的JSON文件,这就不太方便了。
#### 读取excel文件
seldom支持excel文件的数据解析为list。
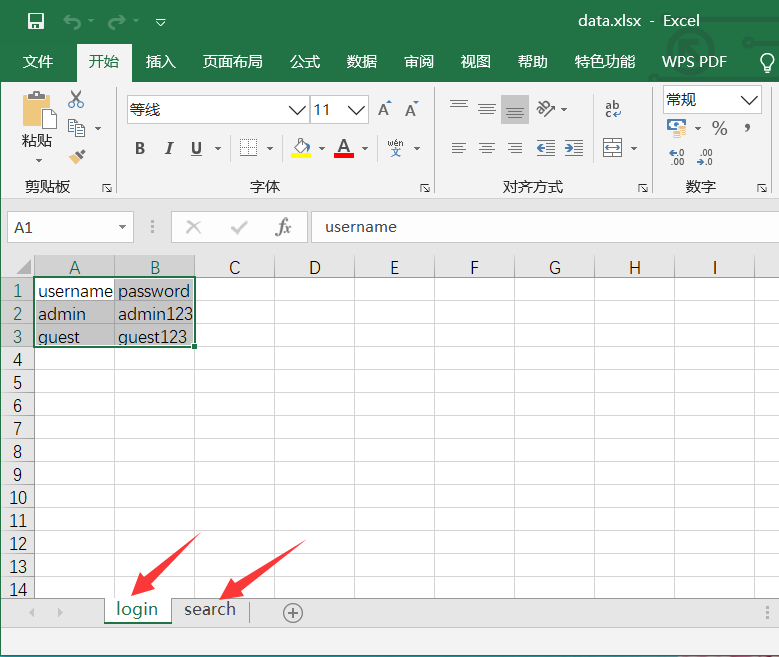
Excel文件可以创建多个Sheet标签,通过不同的标签管理数据。
```python
import seldom
from seldom import data
from seldom import excel_to_list
class YouTest(seldom.TestCase):
@data(excel_to_list(file="data.xlsx", sheet="login", line=2))
def test_login(self, username, password):
"""test login"""
self.open("https://login.xxx.com")
self.type(id_="user", text=username)
self.type(id_="pawd", text=password)
@data(csv_to_list(file="data.xlsx", sheet="search", line=2))
def test_search(self, keyword):
"""test search """
self.open("https://www.baidu.com")
self.type(id_="kw", text=keyword)
```
`excel_to_list()` 方法excel文件数据转化为list。
* file : 指定excel文件的绝对路径。
* sheet: 指定excel的标签页,默认名称为 Sheet1。
* line : 指定从第几行开始读取,默认第一行。
#### 读取JSON文件
seldom支持将JSON文件的数据解析为 listhttps://img.qb5200.com/download-x/dict。
json 文件:
```json
{
"search":[
["python"],
["seldom"],
["unittest"]
],
"login": [
["admin", "admin123"],
["guest", "guest123"]
]
}
```
一个JSON文件里面同样可以表示不同格式的的文件。
```python
import seldom
from seldom import data
from seldom import json_to_list
class YouTest(seldom.TestCase):
@data(json_to_list(file="data.json", key="login"))
def test_login(self, username, password):
"""test login """
self.open("https://login.xxx.com")
self.type(id_="user", text=username)
self.type(id_="pawd", text=password)
@data(csv_to_list(file="data.json", key="search"))
def test_search(self, keyword):
"""test search """
self.open("https://www.baidu.com")
self.type(id_="kw", text=keyword)
```
`json_to_list()` 方法JSON文件数据转化为listhttps://img.qb5200.com/download-x/dict。
* file : 指定JSON文件的绝对路径。
* key: 指定字典的key,默认不指定解析整个JSON文件。
#### 使用第三方ddt
seldom也支持第三方ddt库。
GitHub:https://github.comhttps://img.qb5200.com/download-x/datadriventestshttps://img.qb5200.com/download-x/ddt
安装:
```shell
> pip install ddt
```
创建测试文件`test_data.json`:
```json
{
"test_data_1": {
"word": "seldom"
},
"test_data_2": {
"word": "unittest"
},
"test_data_3": {
"word": "selenium"
}
}
```
在 seldom 使用`ddt`。
```python
import seldom
from ddt import ddt, file_data
@ddt
class YouTest(seldom.TestCase):
@file_data("test_data.json")
def test_case(self, word):
"""a simple test case """
self.open("https://www.baidu.com")
self.type(id_="kw", text=word)
self.click(css="#su")
self.assertTitle(word + "_百度搜索")
if __name__ == '__main__':
seldom.main()
```
更多的用法请查看ddt文档:https:/https://img.qb5200.com/download-x/ddt.readthedocs.io/en/latest/example.html

