以网页表格为例:https://www.kuaidaili.com/free/
该网站数据存在table标签,直接用requests,需要结合bs4解析正则/xpath/lxml等,没有几行代码是搞不定的。
今天介绍的黑科技是pandas自带爬虫功能,pd.read_html(),只需传人url,一行代码搞定。
原网页结构如下:

python代码如下:
import pandas as pd url='http://www.kuaidaili.com/free/' df=pd.read_html(url)[0] # [0]:表示第一个table,多个table需要指定,如果不指定默认第一个 # 如果没有【0】,输入dataframe格式组成的list df
输出dataframe格式数据
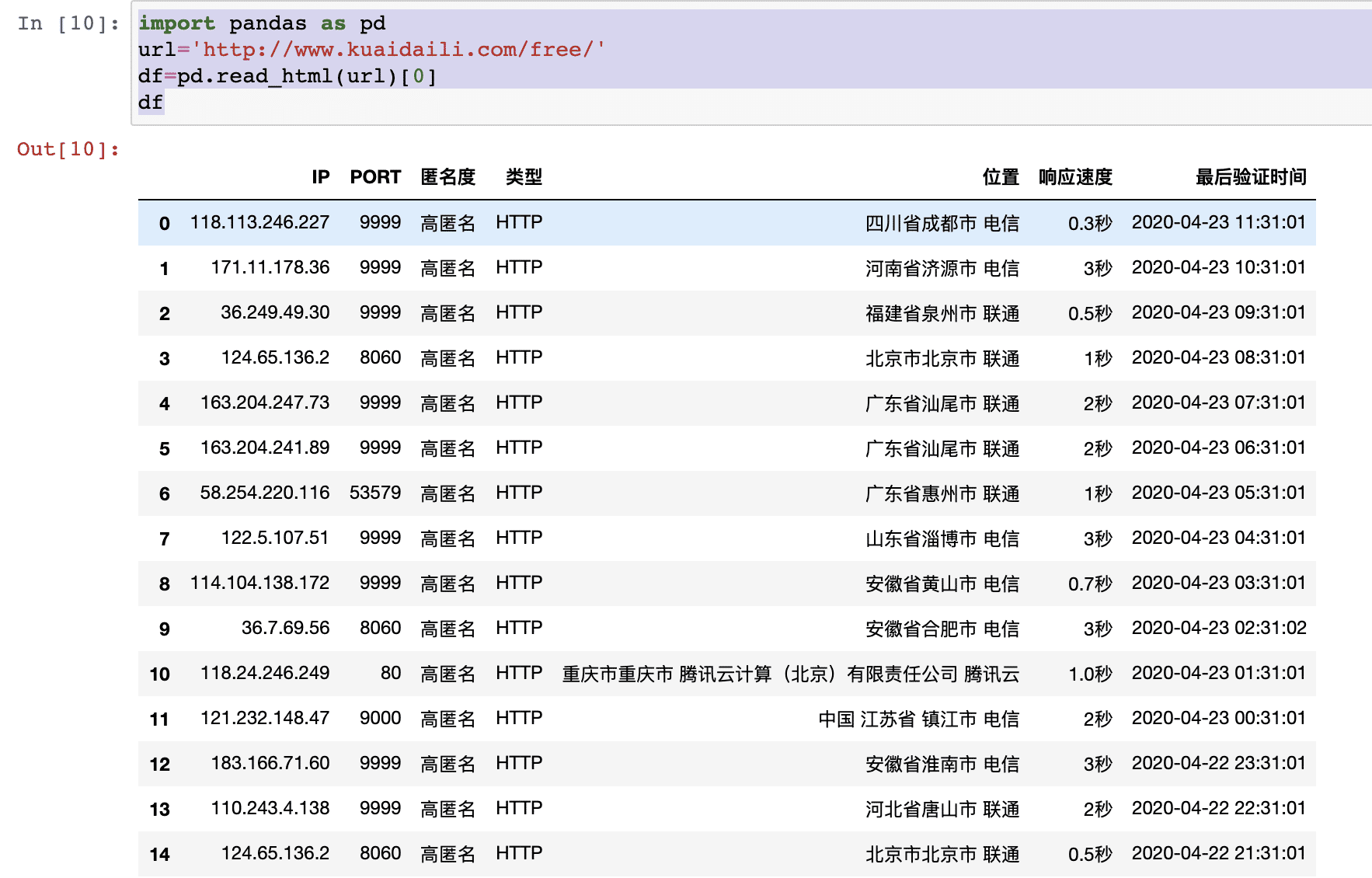

再次保存到本地,csv格式,注意中文编码:utf_8_sig
print(type(df))df.to_csv('free ip.csv',mode='a', encoding='utf_8_sig', header=1, index=0)print('done!')
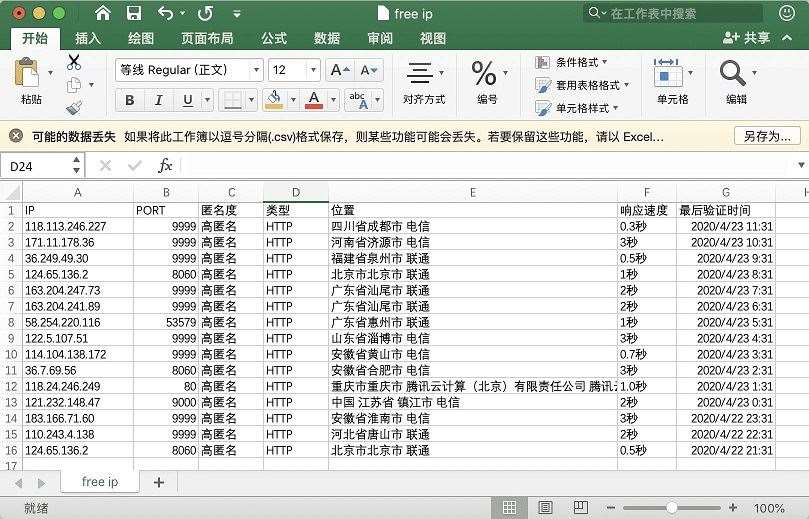
查看csv文件
先来了解一下read_html函数的api:
pandas.read_html(io, match='.+', flavor=None, header=None, index_col=None, skiprows=None, attrs=None, parse_dates=False, tupleize_cols=None, thousands=', ', encoding=None, decimal='.', converters=None, na_values=None, keep_default_na=True, displayed_only=True)
常用的参数:
注意:返回的结果是**DataFrame**组成的**list**。
若要dataframe,直接取list【0】

