常见的统计总数、计算平局值等操作,可以使用聚合函数来实现,常见的聚合函数有:
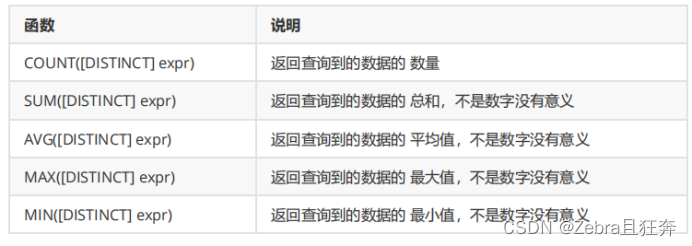

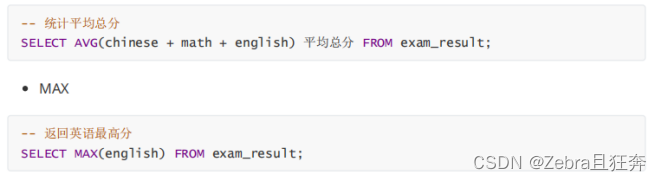


注意点:
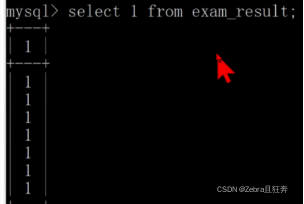
1.count:可以使用count(*),count(0),count(1)这样,说白了实际上和select 1 from整个表是一样的道理,这个count里面的0,1只是作为参数传入而已,先select 1,然后再统计count的值
2.sum,max,min,avg都不可以传入*,必须传入字段或者表达式使用
3.avg可以和sum结合起来用,聚合函数都可以多个一起用
SELECT 中使用 GROUP BY 子句可以对指定列进行分组查询。需要满足:使用 GROUP BY 进行分组查询时,SELECT 指定的字段必须是“分组依据字段”,其他字段若想出现在SELECT 中则必须包含在聚合函数中。
语法:
![]()
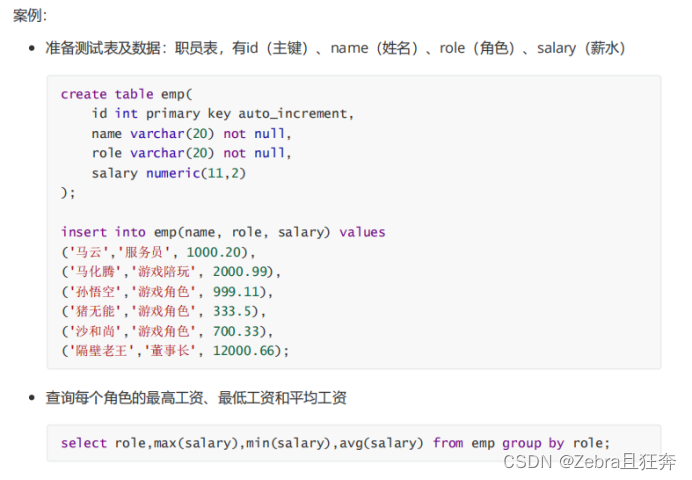
Select指定的字段必须是group by后面有的,没有的只能出现在聚合函数中,不然会出问题
GROUP BY注意事项
1.Group by语句的实质就是分组,常配合聚合查询使用
2.只要有聚合函数出现,就可能要分组
3.分组操作中,查询允许的是分组字段,聚合函数,其他非分组字段需要保证分组后没有多行(如学生id分组,查询字段可以有学生姓名,因为学生id分组以后,只有一行)
4.分组前过滤条件用where,分组后用having(代码是顺序执行的)
执行顺序:from > on> join > where > group by > with > having >select > distinct > order by > limit
5.---select classid,average(score) from student where score>60 group by classid havinng classid<=3
先找出score > 60的行,然后按照classid分组,得到的结果里面,再选出class <=3的行,显示出分数总和(显示出1,2,3各班的分数大于60分的学生的平均分)
6.group by 就是将重复的行合并成一行
7.group by 很多个字段的时候,可能没有合并,但是达到了分组的效果,可以使用聚合函数了。
GROUP BY 子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用 WHERE 语句,而需要用HAVING。HAVING是在GROUP BY 后面执行的

语法:

这里第二个方法的话,你可能不知道哪个是连接条件,哪个是筛选结果集的条件。用哪种都行,还是优先用第一种吧,为了和后面的外连接对应。内连接就相当于是在得到的笛卡尔积上给了连接条件
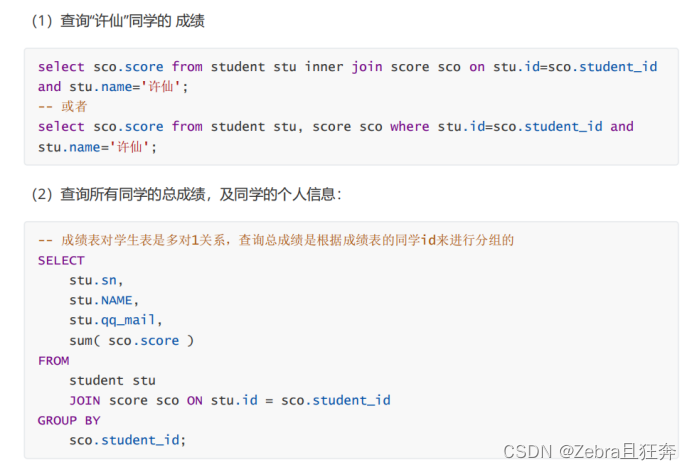
这里要是不group by进行分组的话,就会像下面这样只有一行,相当于是把所有学生的所有成绩全部加起来了。但是我们这里需要的是单个学生的总成绩,所以我们要先按学生id进行分组。

外连接分为左外连接和右外连接。如果联合查询,左侧的表完全显示我们就说是左外连接;右侧的表完全显示我们就说是右外连接。
注意点:
语法:(注意:On后面还能跟上where)


同样的查询方法,这次能显示出第8名成绩为空的学生的信息,左表也就是student表中的数据会全部显示出来,不会受到连接条件stu.id = sco.student_id这一连接条件的影响,如果是之前的内连接,就显示不出老外学中文这一学生的信息,因为在sco表中根本就没有老外学中文这一学生的id。
自连接是指在同一张表连接自身进行查询。
使用场景:同一张表,多行进行比较。
注:自连接查询也可以使用join on语句来进行查询。
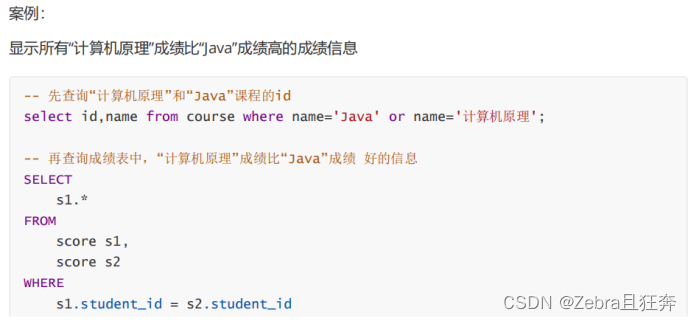
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询
查询与“不想毕业” 同学的同班同学:(自连接)

多行子查询:返回多行记录的子查询(用的多)
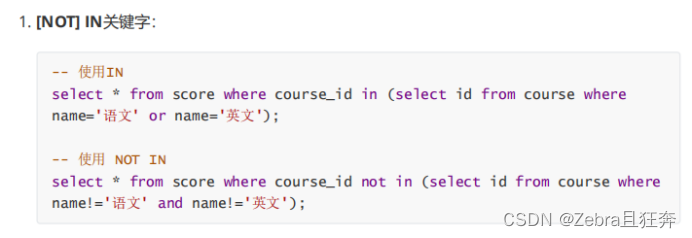
案例:查询“语文”或“英文”课程的成绩信息:(内连接)
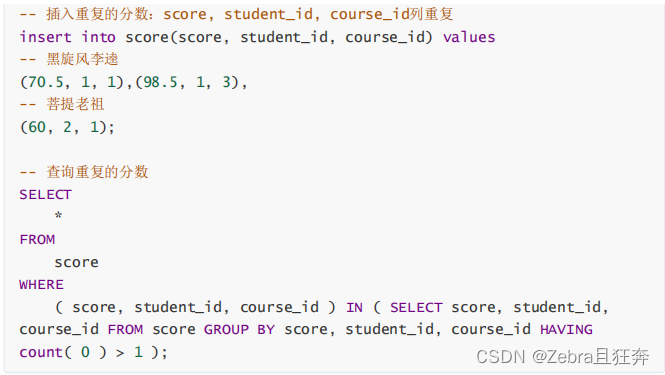
这里的group by没有起到合并的作用,但是起到了分组的作用
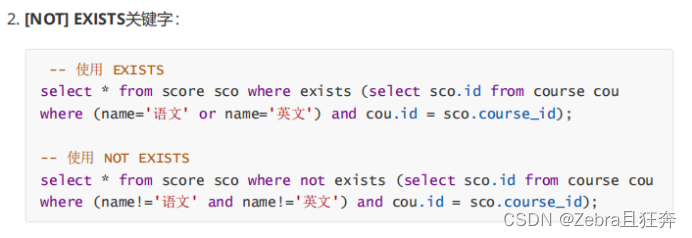
在实际应用中,为了合并多个select的执行结果,可以使用集合操作符 union,union all。使用UNION和UNION ALL时,前后查询的结果集中,字段需要一致。
**有些情况下,多张表之间没法关联,但是要查询一样字段的数据
**union的效率比or高
该操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行(取到的数据内容完全一样的时候,会自动去重)。
案例:查询id小于3,或者名字为“英文”的课程:
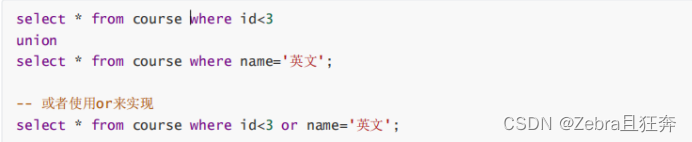
该操作符用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行。(取到的数据完全一样的时候,都会显示出来,不会进行去重)
案例:查询id小于3,或者名字为“Java”的课程


