df['sum_age'] = df['age'].cumsum() print(df)

df['sum_age_new'] = df.groupby(['gender','is_good'])['age'].cumsum() print(df)

df['rank_g'] = df.groupby(['gender'])['age'].rank() print(df)
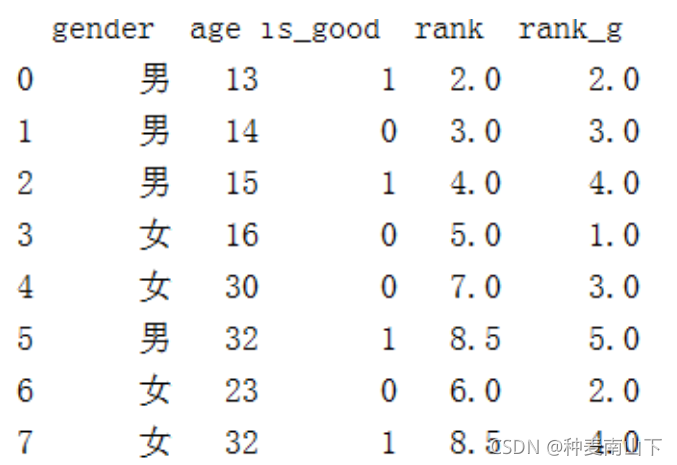
这里的 rank( ) 即 'rank_g' ,并不是按照1、2、3、4、、依次排
按照官方文档的意思,该函数是沿着某个轴来计算数值数据等级(1到n)。默认情况下,为相等的值分配同一个等级,该等级是这些值的等级的平均值。
例子:
import pandas as pd obj = pd.Series([7,-5,7,4,2,0,4]) print(obj.rank())
代码对 [7, -5, 7, 4, 2, 0, 4] 进行从小到大地排序,很明显地,可以排成 [-5, 0, 2 ,4, 4, 7, 7],数值7有第6和第7两个位置,那应该排序应该排到第几级?根据官方文档,取平均值,(6+7)/2=6.5,所以两个7的等级都为6.5,同理可得两个4的等级都为(4+5)/2=4.5。
输出:
0 6.5
1 1.0
2 6.5
3 4.5
4 3.0
5 2.0
6 4.5
dtype: float64
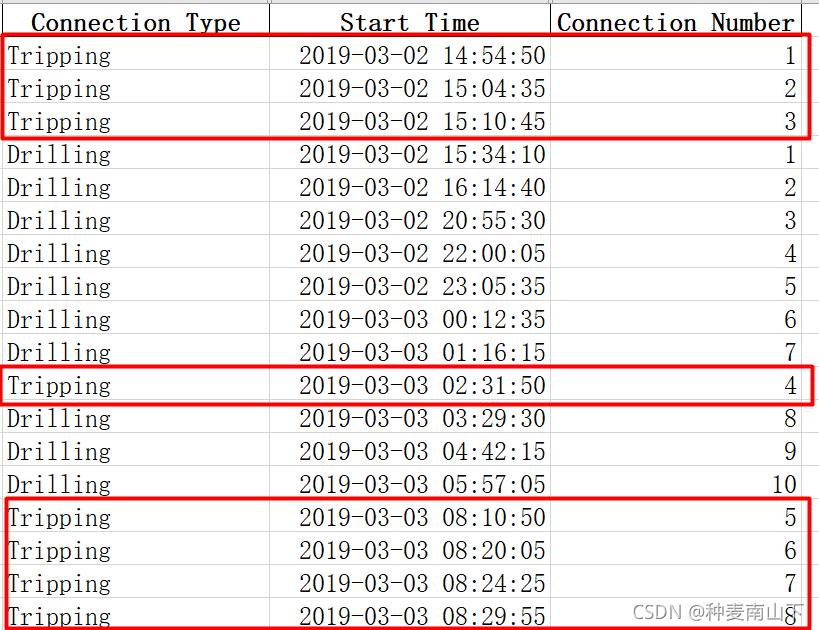
# 对Start Time进行排序,Connection Type分组,temp进行累计求和cumsum wsw_1 = wsw.sort_values(['Start Time']) wsw_1.loc[:, 'Connection Number'] = wsw_1.groupby(['Connection Type'])['temp'].cumsum()
这里如果不对start time排序,Connection Number不会按时间顺序,统计drilling、tripping 的number数
在一个班级里,学生考试科目有语文、数学、英语,分别有对应的成绩。
现在,想要列出每个科目班级的前五名的情况,要求包含科目、姓名、成绩、名次。
通过以下代码实现:
import pandas as pd
a=['小红','小绿','小蓝','小白','小青','小紫','小粉','小傻','小红','小绿','小蓝','小白','小青','小紫','小粉','小傻','小红','小绿','小蓝','小白','小青','小紫','小粉','小傻']
b=['语文','语文','语文','语文','语文','语文','语文','语文','数学','数学','数学','数学','数学','数学','数学','数学','英语','英语','英语','英语','英语','英语','英语','英语']
c=[97,65,23,43,67,23,55,98,56,45,67,78,98,45,87,65,67,23,55,98,56,45,67,78]
len(a),len(b),len(c)
df=pd.DataFrame({'name':a,'kemu':b,'score':c})
df2=df.sort_values(['kemu','score','name'], ascending=[1, 0,1])
df2['rn']=df2.groupby(['kemu']).rank(method='first',ascending =0)['score']
df2[df2['rn']<=5]
''''以上为个人经验,希望能给大家一个参考,也希望大家多多支持。

