先声明下观点:当有少量结构体成员时,传递结构体指针和结构体变量的差距不大;当有大量结构体成员时,随着成员越来越多,传递指针的效率也越来越高,与传递变量的差距也越来越大。
直接看代码:
测试程序demo01.cpp,如下:
#include <stdio.h>
#include <Windows.h>
struct st_info // 定义结构体
{
int x;
int y;
int m;
int n;
};
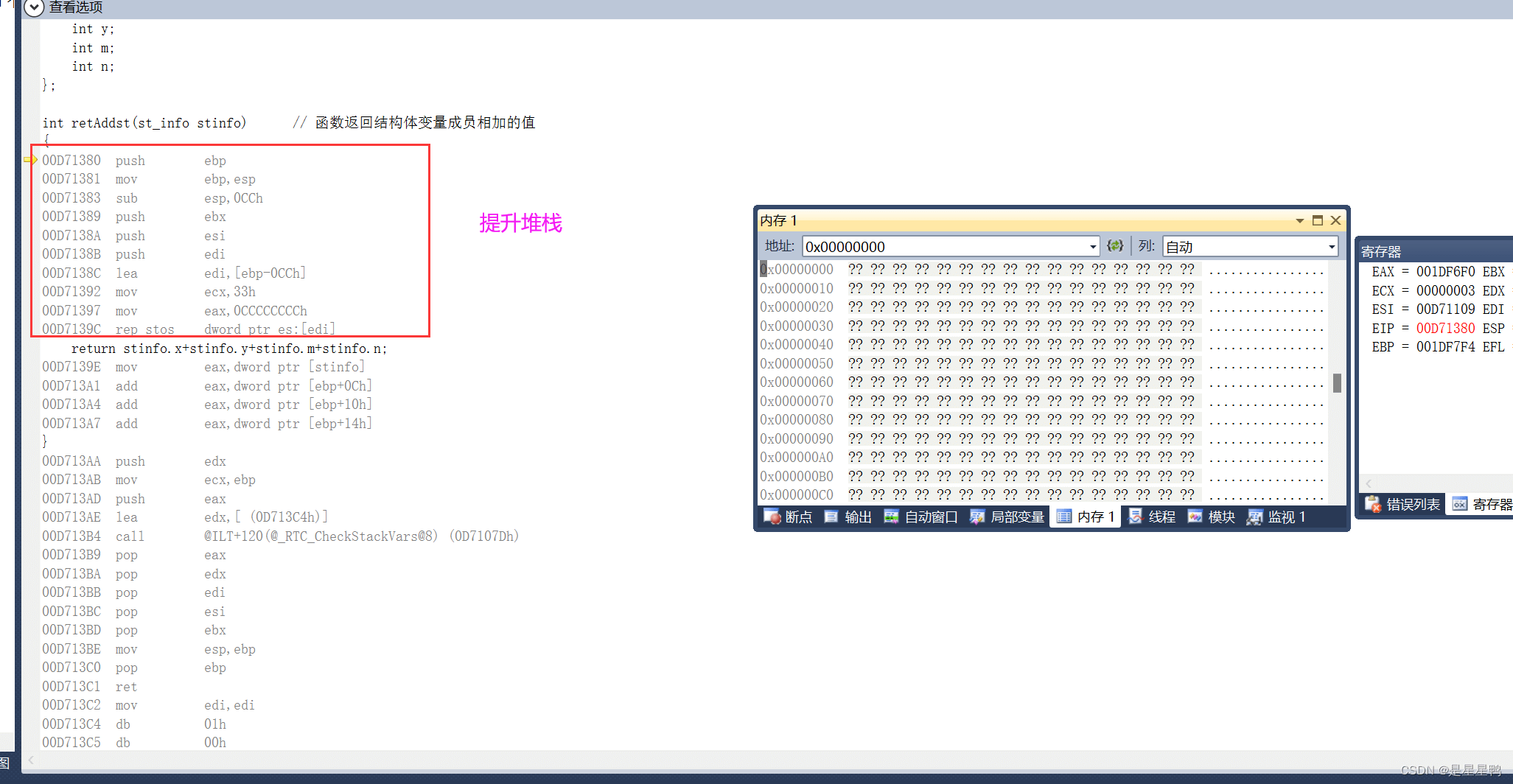
int retAddst(st_info stinfo) // 函数返回结构体变量成员相加的值
{
return stinfo.x+stinfo.y+stinfo.m+stinfo.n;
}
int main()
{
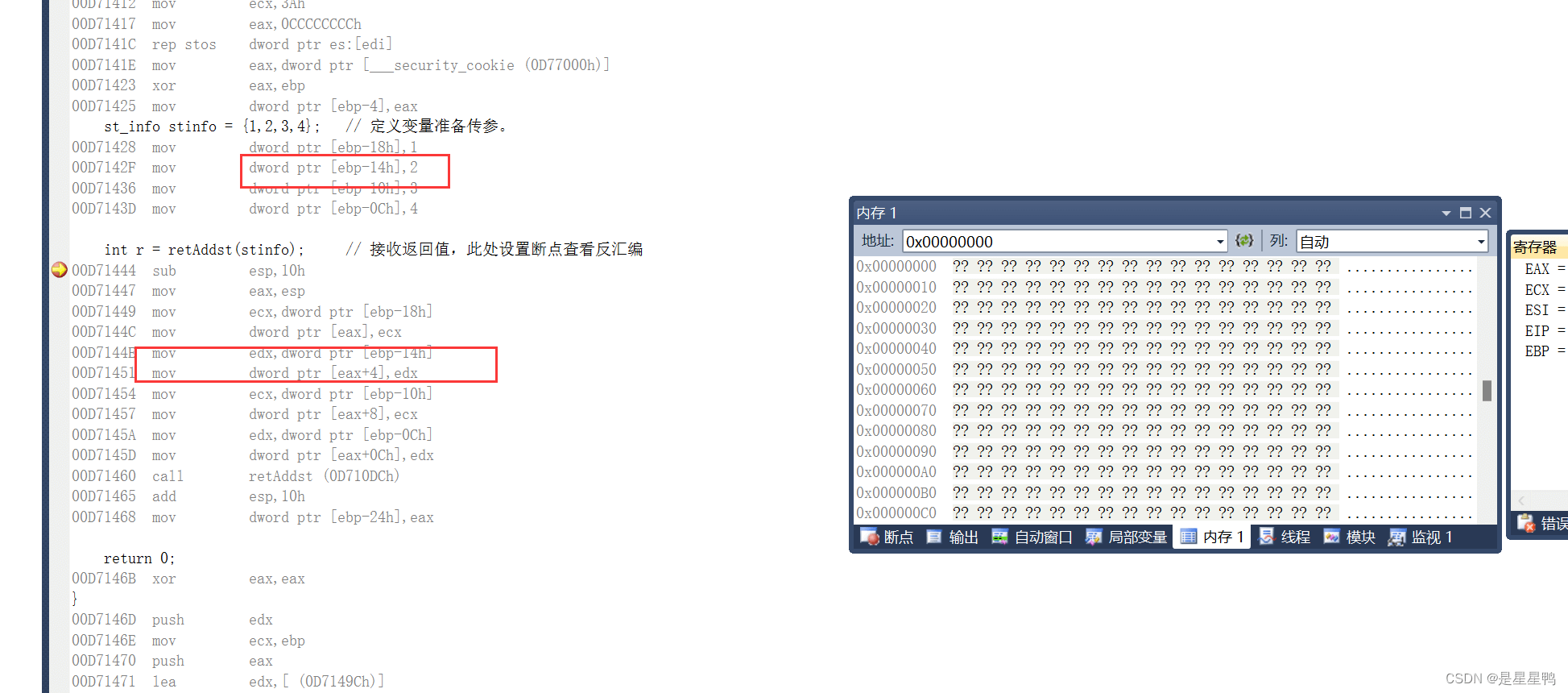
st_info stinfo = {1,2,3,4}; // 定义变量准备传参。
int r = retAddst(stinfo); // 接收返回值,此处设置断点查看反汇编
return 0;
}vs2010:断点、F7编译、F5调试、ALT+8转到反汇编
如下:

当看到这段汇编代码的实现的时候,可能对于新手都不太友好,因为之前对于函数的调用时,汇编代码大多都是使用push进行传参,但是这里调用函数却没有用到push,那他是怎么实现的呢?
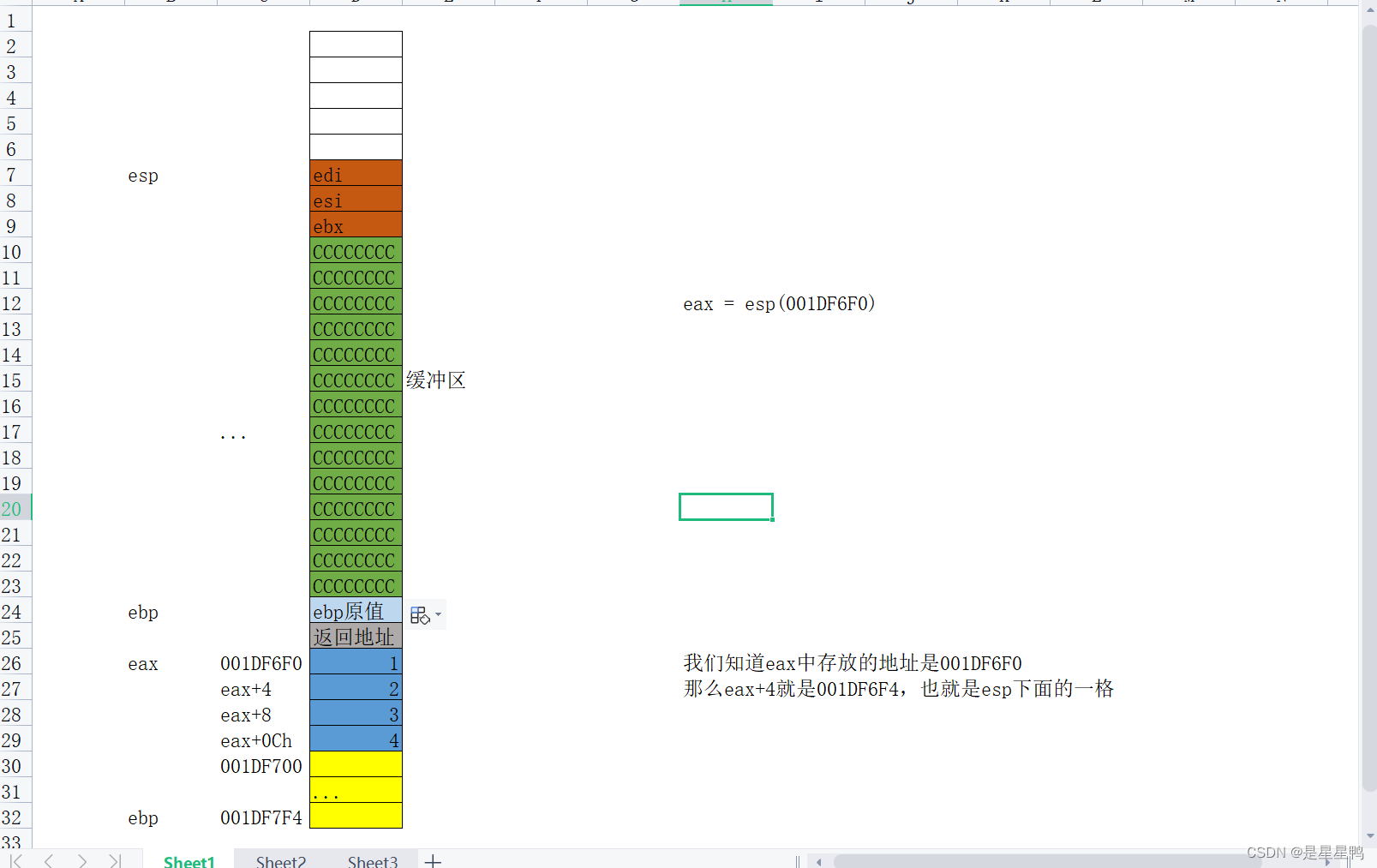
我们画堆栈图逐步分析:
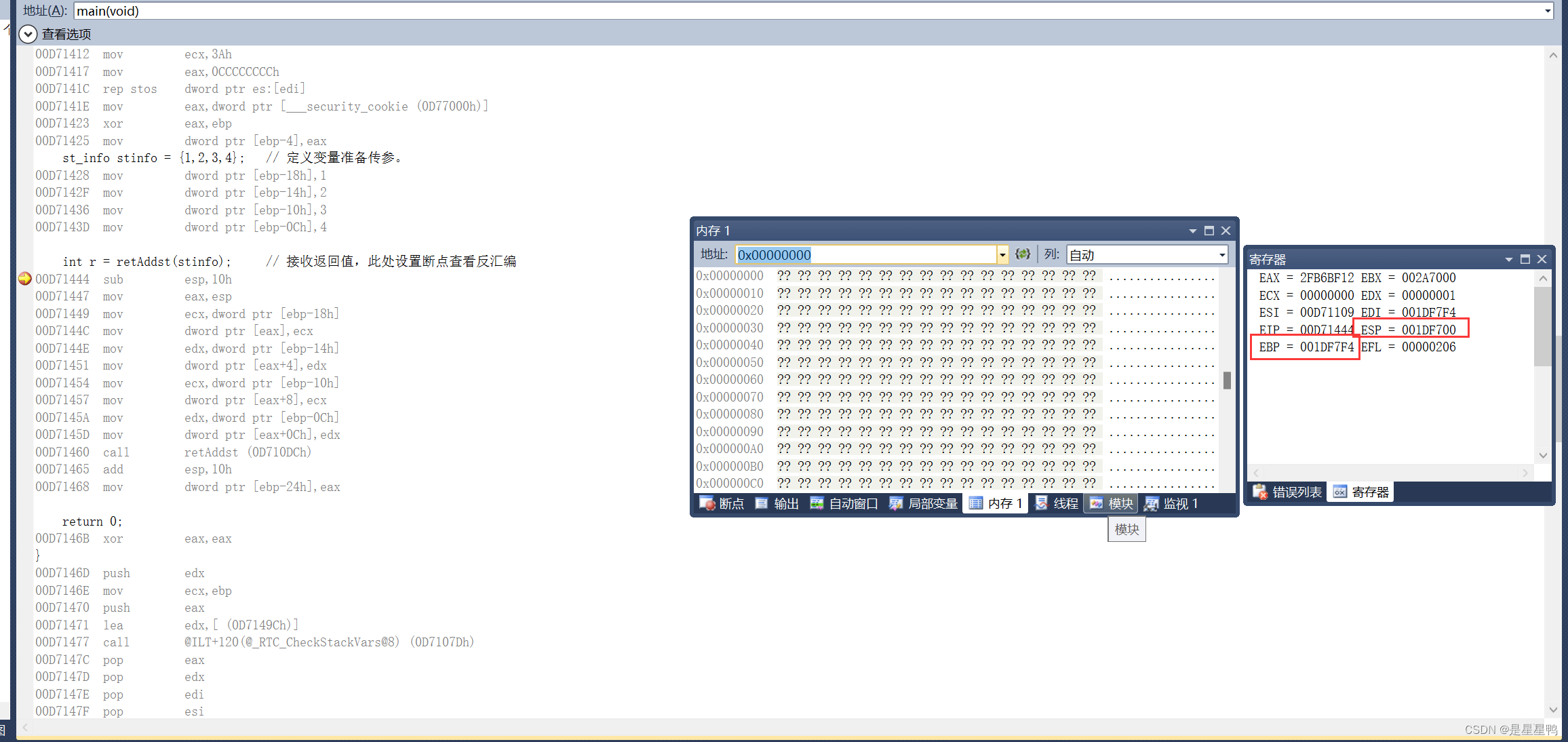
堆栈:

汇编:
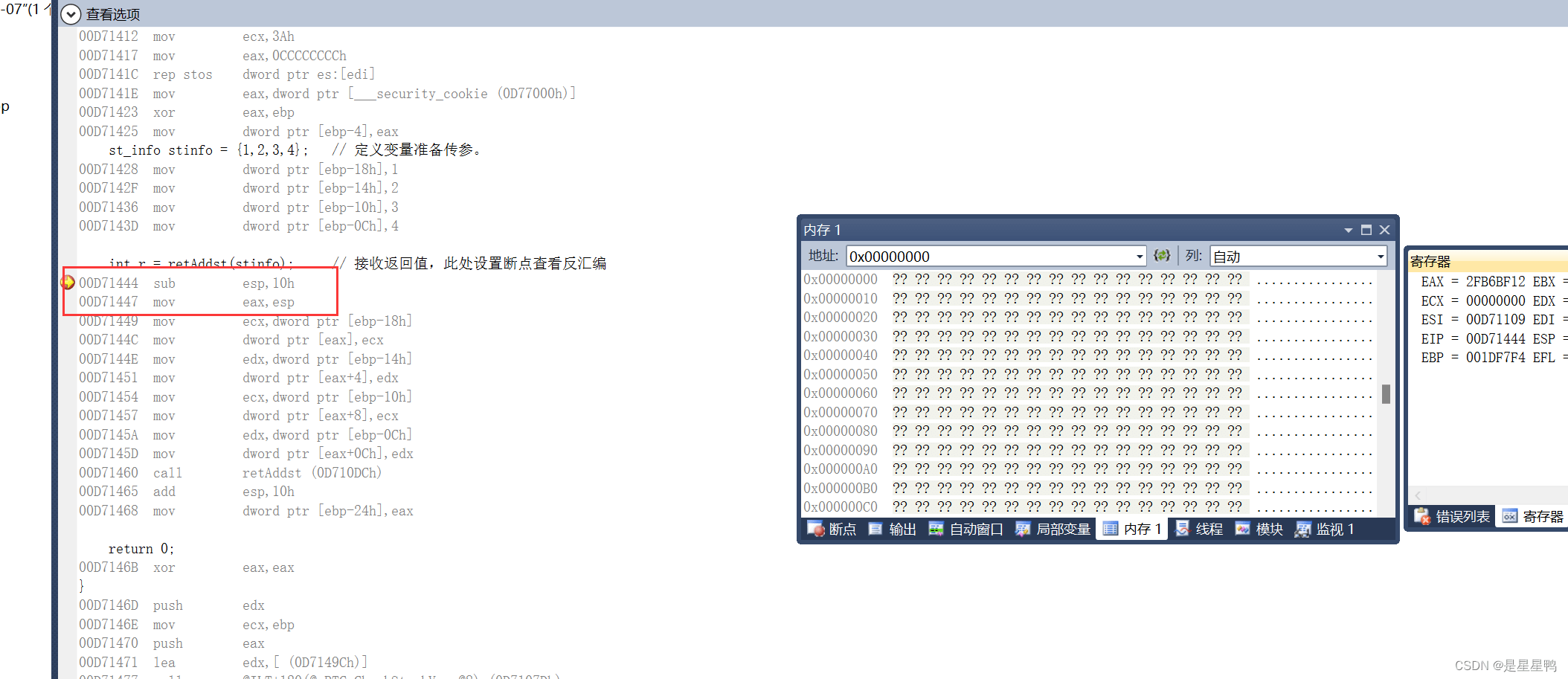
堆栈:

汇编:

堆栈:
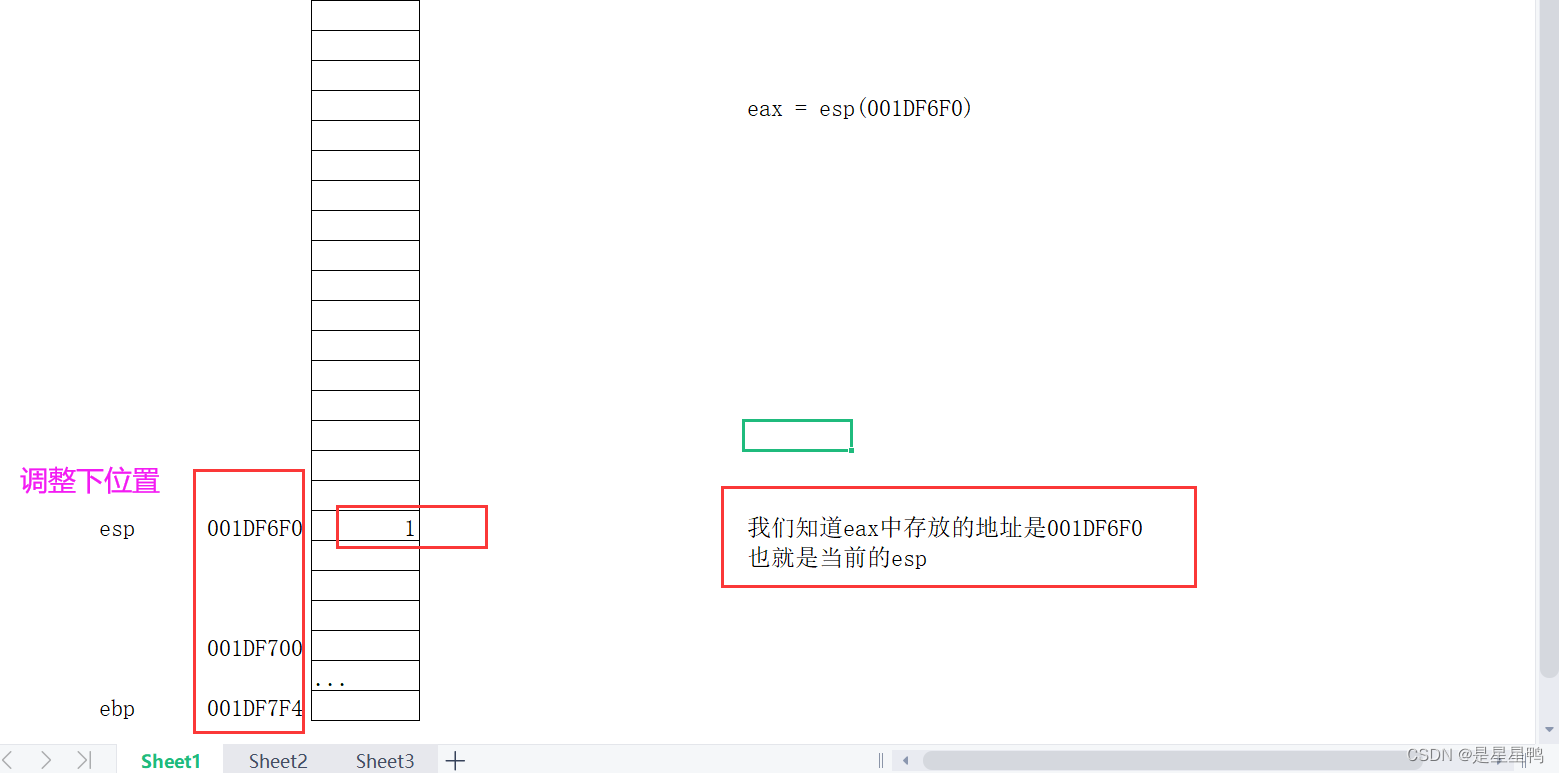
汇编:
堆栈:

汇编:
堆栈:

汇编:
堆栈:

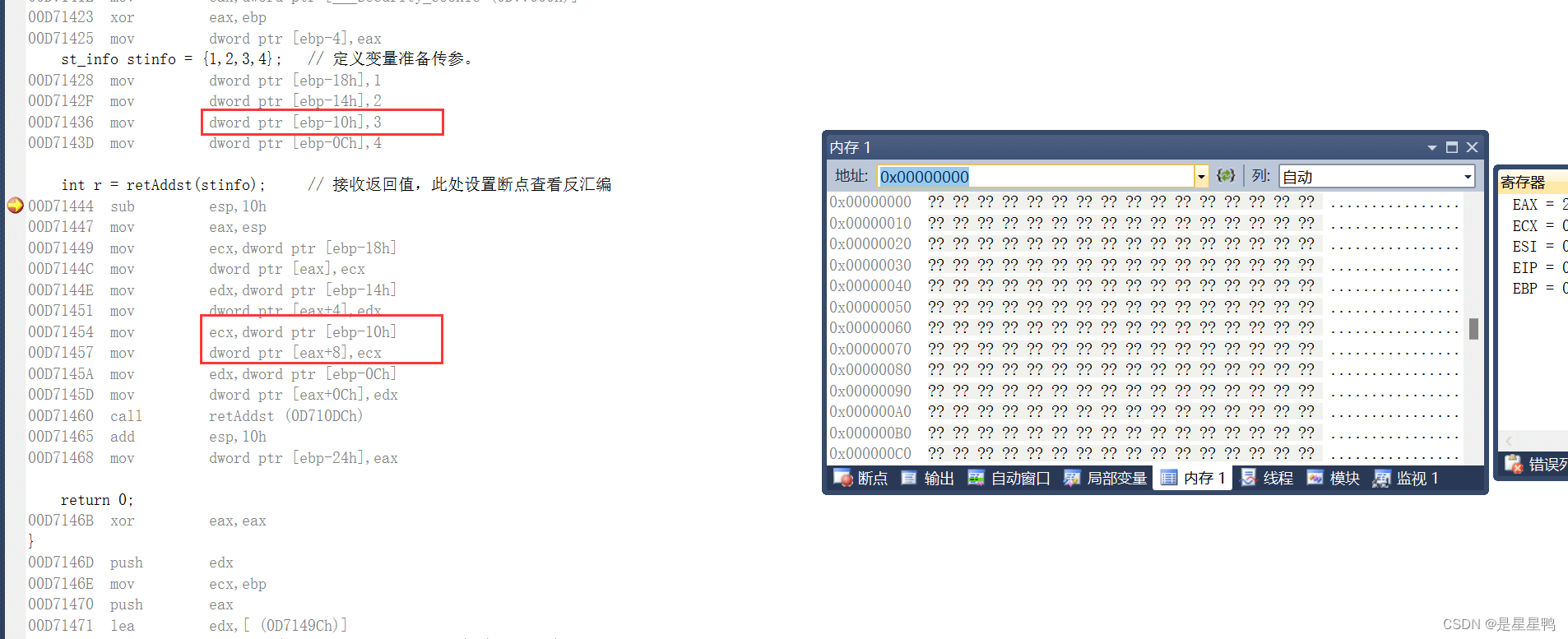
然后下面就是调用函数,让我们看看函数中是怎么使用的
单步F11进入函数内部:
汇编:
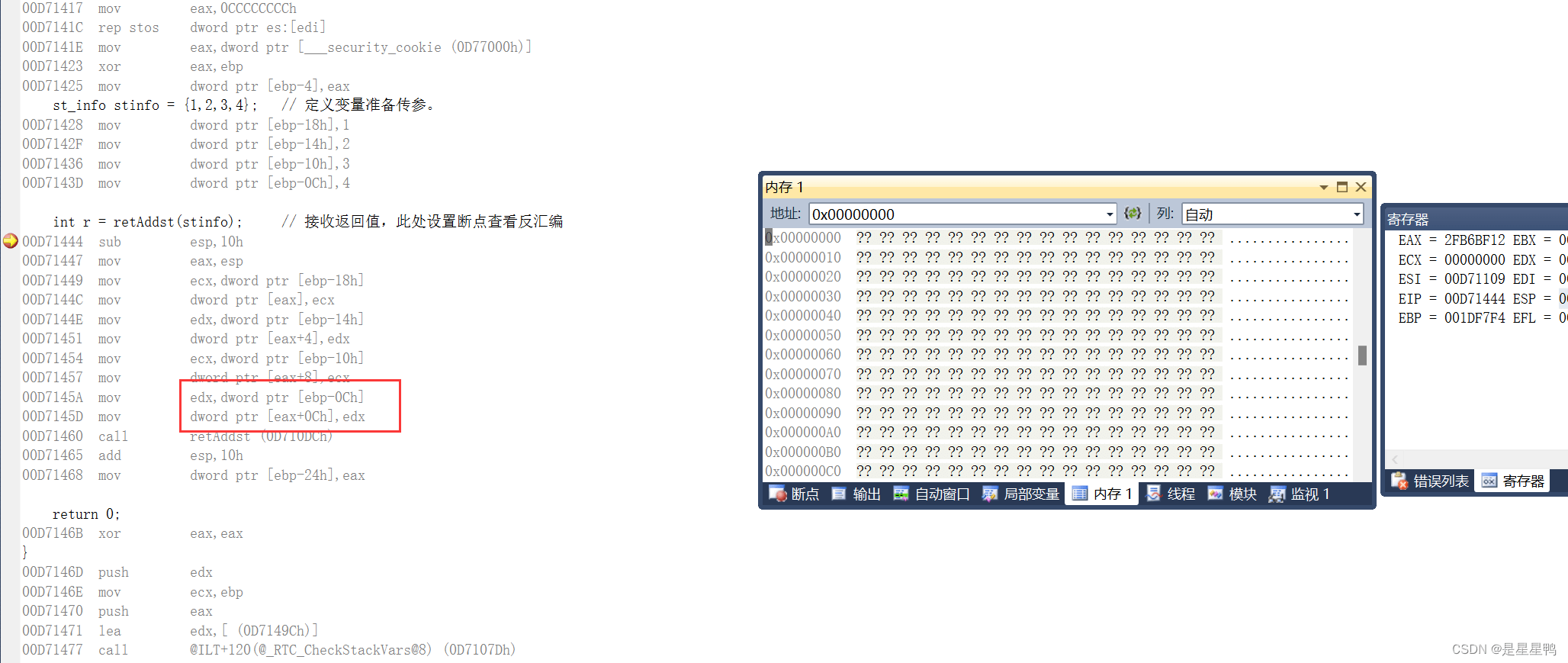
这里我直接给出堆栈结果,不懂得可以看我之前的文章《堆栈图》
汇编:
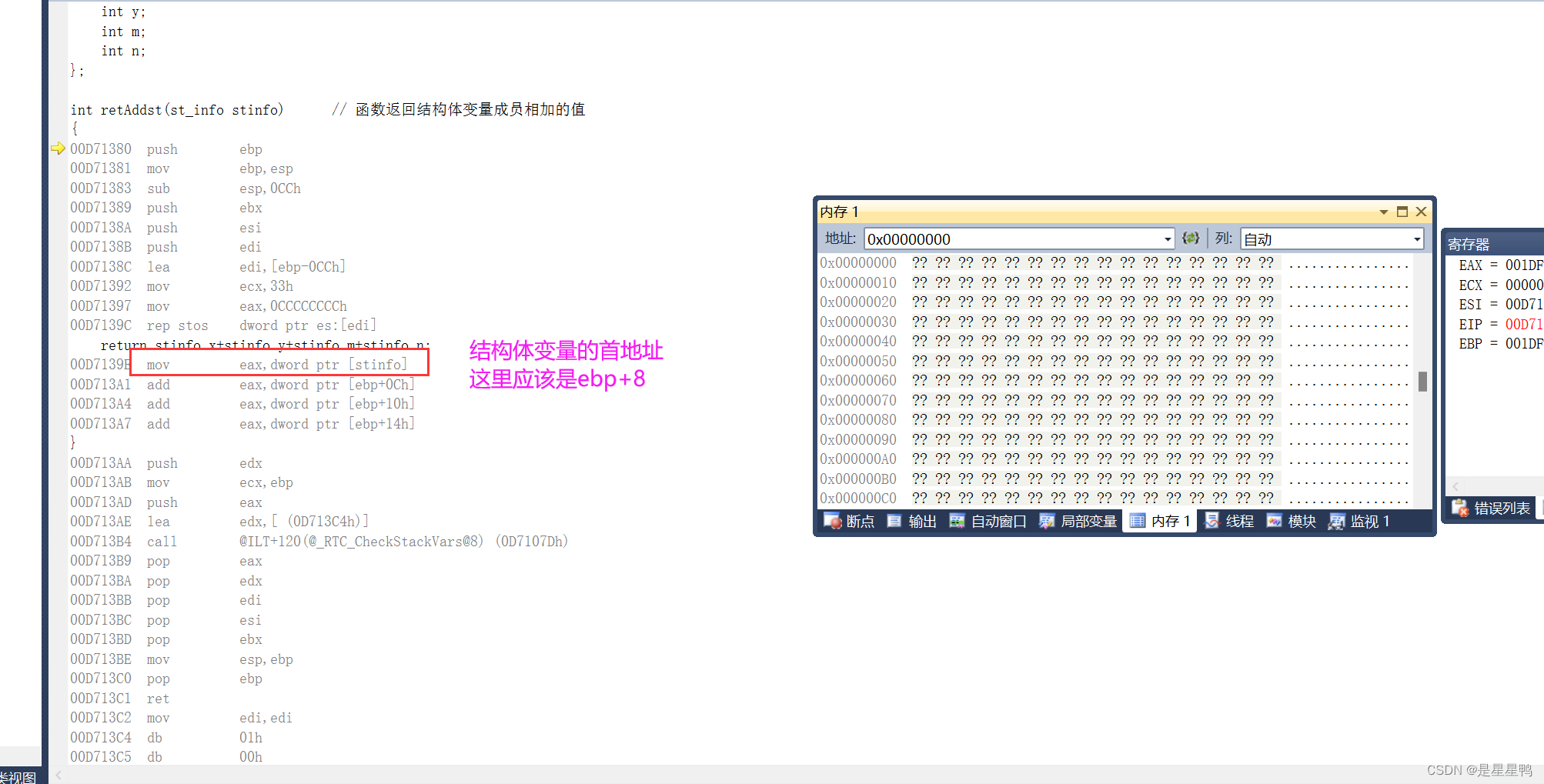
对应堆栈:

可以看出,虽然没有使用push进行参数的传递,但是他还是使用堆栈,使用ebp寻址来实现的函数参数的查找。
为什么说传递结构体变量性能不高?
我们来分析汇编:
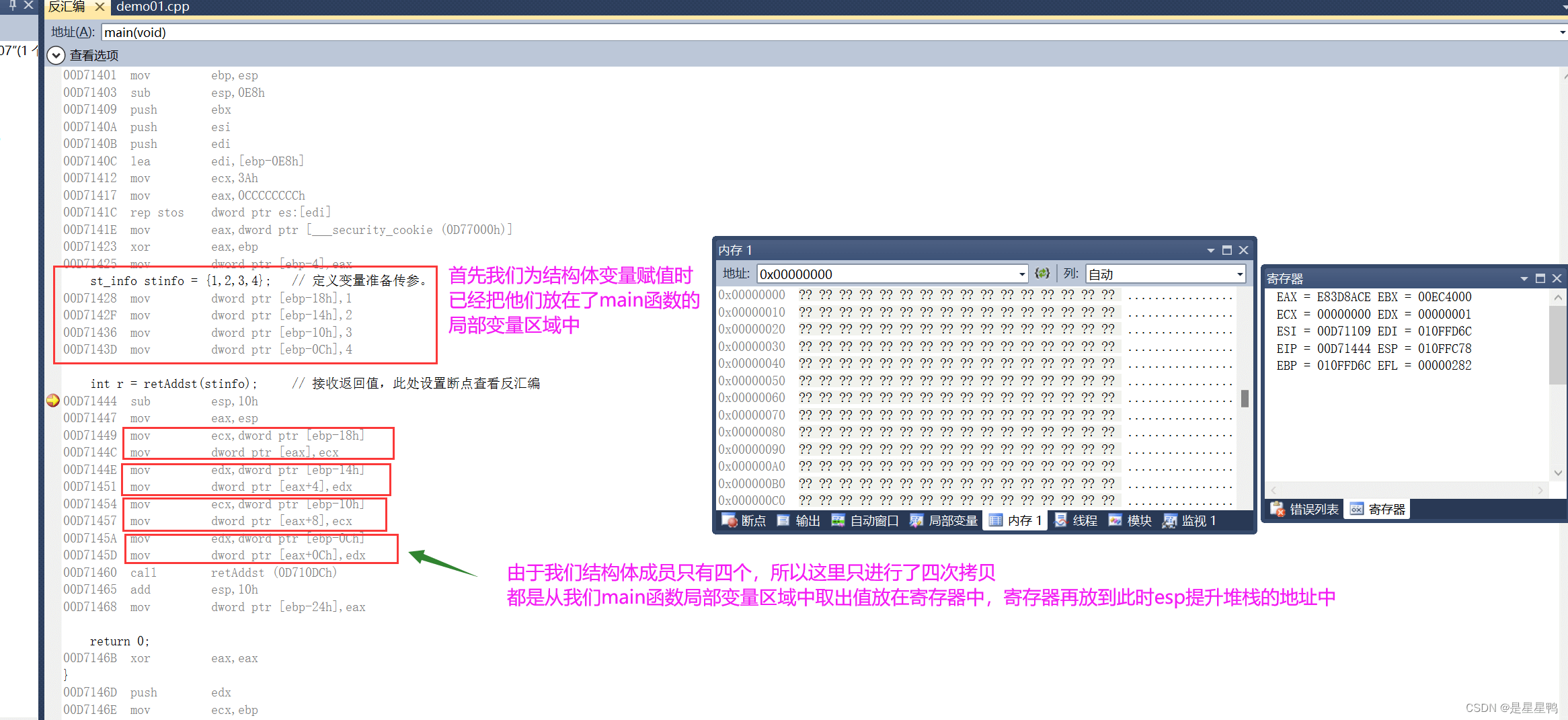
为什么这叫拷贝?
拷贝的概念就是,在不影响原值的情况下,在另外一个地址中也存放一个同样的值
我们可以发现,我们mov指令并不会删除我们之前定义在main函数局部变量区域中的1,2,3,4,并且还复制了一份到esp、esp+4...这些地址中,所以这就是拷贝。
一次拷贝需要从原地址中取一次值、然后放到寄存器、最终放到目标地址,是不是很麻烦?但是如果结构体变量中需要用到四个成员,那么就需要进行四次拷贝,如果成员越来越多,拷贝的次数也就越来越多......
结构体成员拷贝的坏处
随着拷贝次数越来越多,不但会影响性能,也会使汇编代码显得非常臃肿。
解决方法就是传指针。
按照我们对传递指针的理解,我们认为传递变量的指针就是传递他的地址,那么既然有了这个变量的地址了,是不是就不需要拷贝了?
测试程序demo01,代码如下:
#include <stdio.h>
#include <Windows.h>
struct st_info // 定义结构体
{
int x;
int y;
int m;
int n;
};
int retAddst(st_info* stinfo) // 函数返回结构体变量成员相加的值
{
return stinfo->x+stinfo->y+stinfo->m+stinfo->n;
}
int main()
{
st_info stinfo = {1,2,3,4}; // 定义变量准备传参。
int r = retAddst(&stinfo); // 接收返回值,此处设置断点查看反汇编
return 0;
}重新生成、调试、反汇编:
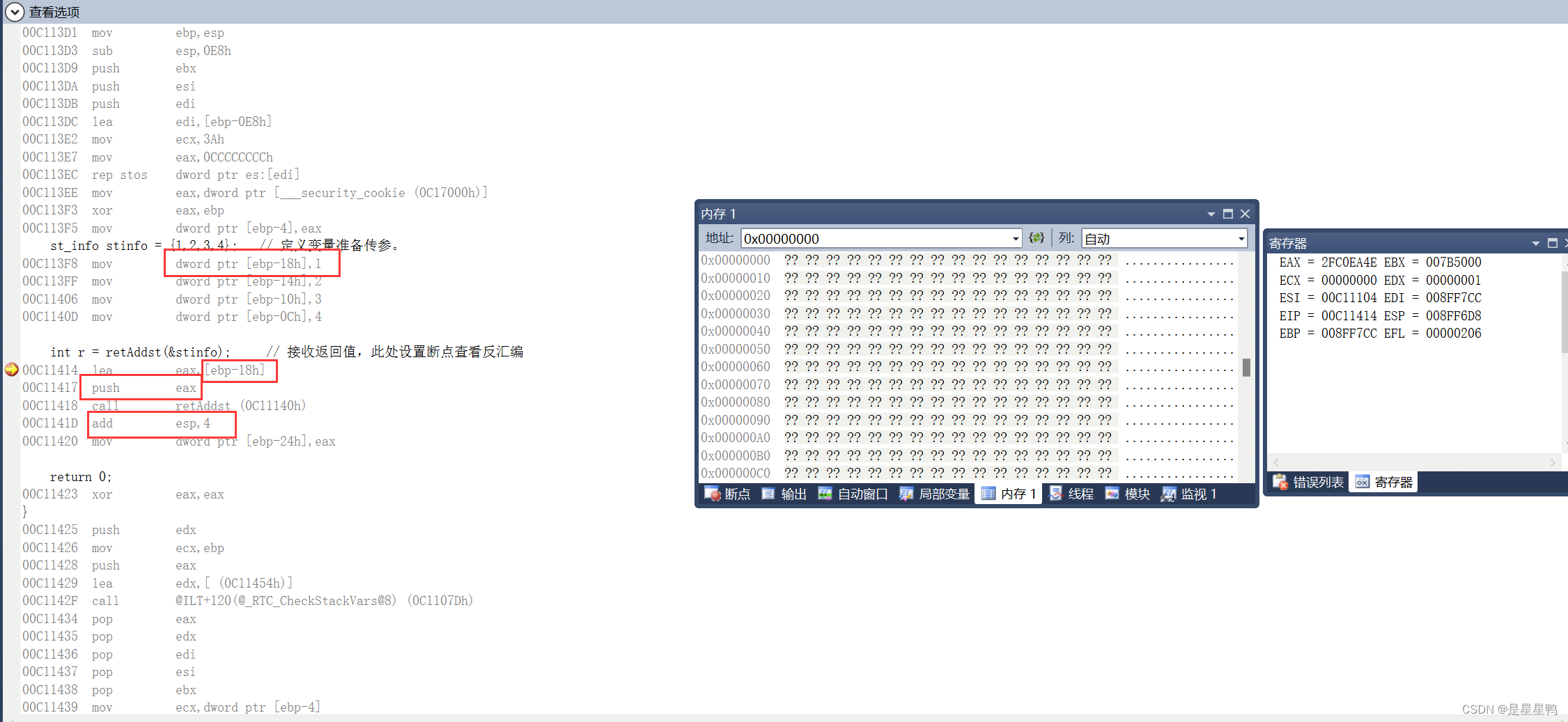
lea eax,[ebp-18h]
通过上面将1存入[ebp-18h]我们知道ebp-18h就是结构体第一个成员的地址,也就是结构体的首地址,所以这里我们仅仅是传递了结构体的首地址
(注意:lea指令是将ebp-18h这个地址赋值给eax,而不是将地址中的1赋值给eax)
与传递结构体变量的汇编对比:
1、首先我们一眼就能看出,汇编代码变得整洁了。
2、传递结构体变量的汇编中,虽然找不到push,但是我们进入函数中分析,发现它使用的依旧是堆栈、并且最后平衡堆栈的时候是add esp+10h,不算函数提升堆栈的使用,总共使用了16字节的堆栈;
然而对于传递指针,最终只是add esp,4;只使用了4个自己的堆栈。并且随着结构体的成员越来越多、差距会越来越大。
对于传递指针,函数内部是如何使用的呢?
如下:
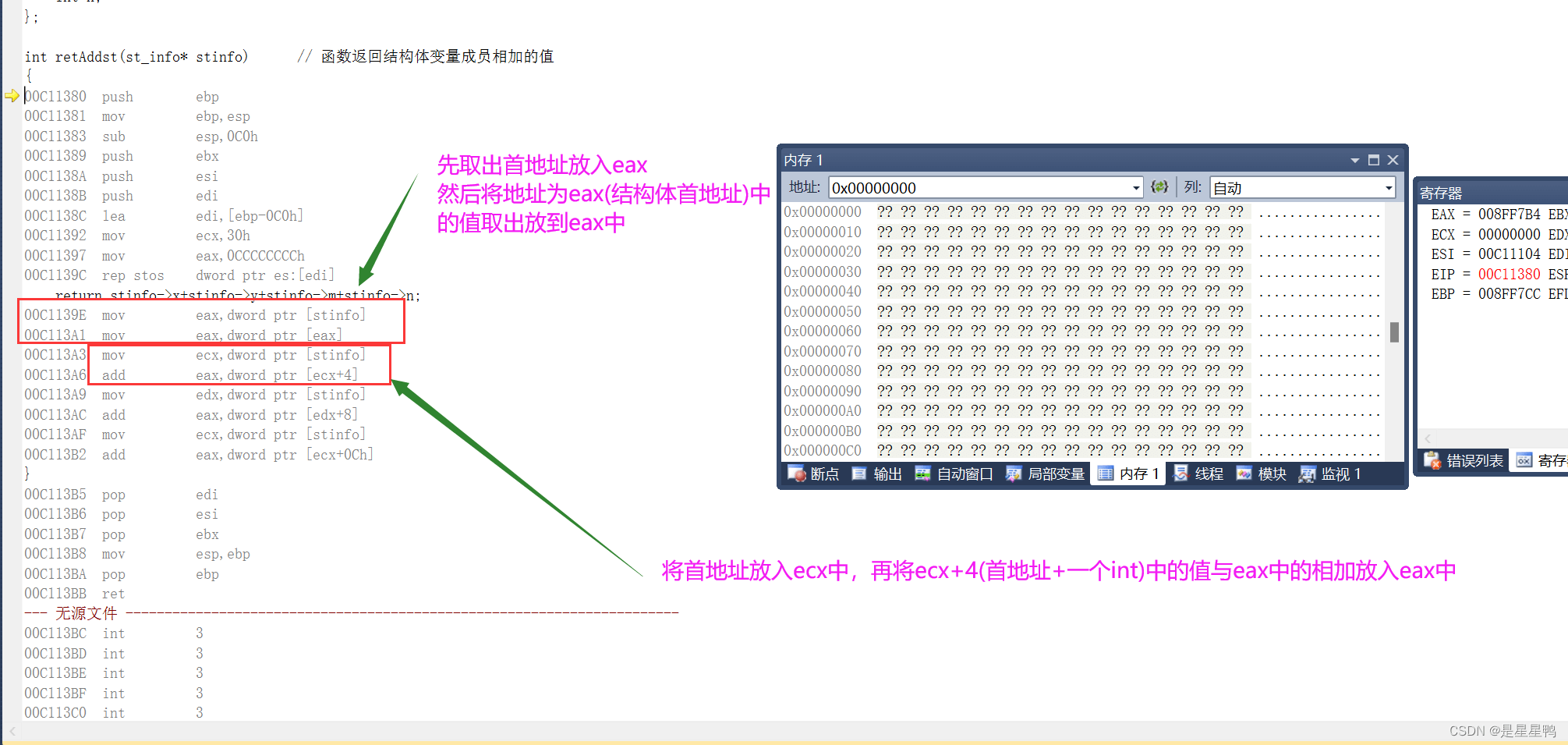
可能看到这里,会有人问:这不是和传递结构体变量传参的代码差不多吗?因为单从汇编代码上来观察,貌似都长得很像,但是还是有区别的。
传递变量时,我们是将原堆栈中的值取出放到寄存器、然后寄存器放到新的堆栈中
传递地址时,我们是将首地址放到寄存器中,然后取出该地址中的值又放到寄存器中
区别呢?
三种方法看出传递变量与传递指针的差距
<1>
传递变量:堆栈->寄存器->新堆栈
传递指针:堆栈->寄存器->寄存器
我们之前说过,使用内存(堆栈)是绝对没有使用cpu(寄存器)的效率高的,所以这也能看出传递地址是比传递变量效率高的。
<2>
传递变量:add esp,10h
传递指针:add esp,04h
当我们传递变量时,我们可以发现,底层汇编是不断的将源地址中的值取出放到堆栈中的,一个使用了16个字节;但是传递地址只用到了四个字节的堆栈,就是用来存放结构体的首地址。这样一来,传递变量内存使用比传递指针要多。当然,我们结构体成员越多,传递变量使用到的堆栈就越多,而传递指针还是只是用4个字节堆栈存放结构体首地址,二者的差距会越来越大。
<3>
传递变量与传递地址的时候,我们都是先将结构体成员存放到main函数的局部变量区域中,也就是下面这一块:

但是传递变量的时候,它是将这四个值1,2,3,4拿出来又放进去的,操作是很频繁的。相反传递地址的时候只是把【ebp-18h】这个地址放进去。一个操作四次、一个操作一次,差距一眼就能看出来。
通过上面的对比,我们可以看出传递指针的效率是比传递变量效率高的。这个差距会随着结构体成员个数的提升而提升。所以,建议传递结构体指针。

