除了引用,Rust 还有另外一种不持有所有权的数据类型:切片(slice),切片允许我们引用集合中某一段连续的元素序列,而不是整个集合。
考虑这样一个小问题:编写一个搜索函数,它接收字符串作为参数,并将字符串中的首个单词作为结果返回。如果字符串中不存在空格,那么就意味着整个字符串是一个单词,直接返回整个字符串作为结果即可。
让我们来看一下这个函数的签名应该如何设计:
fn first_word(s: &String) -> ?
由于我们不需要获得传入值的所有权,所以这个函数采用了 &String 作为参数。但它应该返回些什么呢?我们还没有介绍获取部分字符串的方法,但是可以曲线救国,将首个单词结尾处的索引返回给调用者。
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (index, &item) in bytes.iter().enumerate() {
if item == b' ' {
// 这里要使用 return index; 不能只写 index
// 因为表达式作为返回值要出现在函数的最后面
return index
}
}
s.len()
}
fn main() {
println!(
"{}",
first_word(&String::from("hello world"))
); // 5
}这段代码首先使用 as_bytes 方法将 String 转换为字节数组(u8),因为我们的算法需要依次检查 String 中的字节是否为空格。
接着通过 iter 方法创建了一个可以遍历字节数组的迭代器,我们会在后续详细讨论迭代器,目前只需要知道 iter 方法会依次返回集合中的每一个元素即可。
而随后的 enumerate 则将 iter 的每个输出逐一封装在元组中返回,元组的第一个元素是索引,第二个元素是指向集合中字节的引用(&u8),使用 enumerate 可以较为方便地获得迭代索引。
既然 enumerate 方法返回的是一个元组,那么我们就可以使用模式匹配来解构它,就像 Rust 中其它使用元组的地方一样。在 for 循环的遍历语句中,我们指定了一个解构模式,其中 i 是元组中的索引部分,而 &item 则稍微有点难理解。
首先迭代出的元组里面的第二个元素是 &u8,如果我们使用 item 遍历,那么得到的 item 就是 &u8,在比较的时候还需要解引用,即 *item == b' '。而使用 &item 遍历,那么 &item 得到的也是 &u8,显然 item 就是 u8,我们就不需要解引用了。
在 for 循环的代码块中,使用了字面量语法来搜索数组中代表着空格的字节,这段代码会在搜索到空格时返回当前的位置索引,并在搜索失败时返回传入字符串的长度 s.len()。
现在我们初步实现了期望的功能,它能够成功地搜索并返回字符串中第一个单词结尾处的位置索引。但这里依然存在一个设计上的缺陷,我们将一个 usize 值作为索引独立地返回给调用者,而这个值在脱离了传入的 &String 的上下文之后便毫无意义。
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (index, &item) in bytes.iter().enumerate() {
if item == b' ' {
return index;
}
}
s.len()
}
fn main() {
let mut s = String::from("hello world");
let index = first_word(&s);
println!("{}", index); // 5
// s.clear() 之后会清空字符串,将 s 变成 ""
s.clear();
println!("s = {}", s); // s =
// s 被清空了,index 还是 5,但显然此时 index 已经没有意义了
}上面的程序在编译器看来没有任何问题,即便我们在调用 s.clear() 之后使用 index 变量也是没有问题的。同时由于 index 变量本身与 s 没有任何关联,所以 index 的值始终都是5。但当我们再次使用 5 去从变量 s 中提取单词时,一个 bug 就出现了:此时 s 中的内容在我们将 5 存入 index 之后发生了改变。
这种 API 的设计方式使我们需要随时关注 word 的有效性,确保它与 s 中的数据是一致的,类似的工作往往相当烦琐且易于出错。这种情况对于另一个函数 second_word 而言更加明显,这个函数被设计来搜索字符串中的第二个单词,它的签名也许会被设计为下面这样:
fn second_word(s: &String) -> (usize, usize)
现在我们需要同时维护起始和结束两个位置的索引,这两个值基于数据的某个特定状态计算而来,但却没有跟数据产生任何程度上的联系。于是我们有了 3 个彼此不相关的变量需要被同步,这可不妙。但幸运的是,Rust 为这个问题提供了解决方案:字符串切片。
字符串切片是指 String 对象中某个连续部分的引用,它的使用方式如下所示:
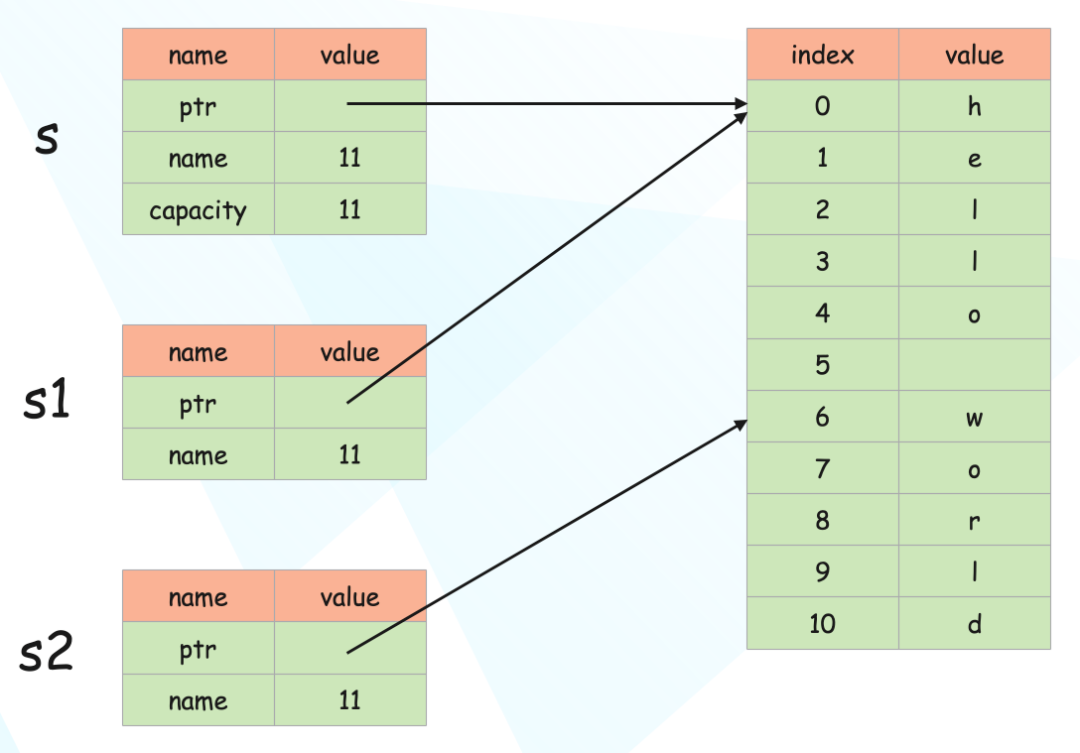
fn main() {
let s = String::from("hello world");
let s1 = &s[0..5];
let s2 = &s[6..11];
println!("s1 = {}, s2 = {}", s1, s2);
// s1 = hello, s2 = world
}这里的语法与创建指向整个 String 对象的引用有些相似,但不同的是,新语法在结尾的地方多出了一段 [0..5]。这段额外的声明告诉编译器我们正在创建一个 String 的切片引用,而不是对整个字符串本身的引用。
切片数据结构在内部存储了指向起始位置的引用和一个描述切片长度的字段,所以在上面的示例中,s2 是一个指向变量 s 第 7 个字节并且长度为 5 的切片。
Rust的范围语法 .. 有一个小小的语法糖:当你希望范围从第一个元素(也就是索引值为 0 的元素)开始时,则可以省略两个点号之前的值;同样地,假如你的切片想要包含 String 中的最后一个字节,你也可以省略双点号之后的值;你甚至可以同时省略首尾的两个值,来创建一个指向整个字符串所有字节的切片。
字符串切片的边界必须位于有效的 UTF-8 字符边界内,尝试从一个多字节字符的中间位置创建字符串切片会导致运行时错误。但为了将问题简化,我们这里只使用 ASCII 字符集,至于 Unicode 后续讨论。
基于所学到的这些知识,让我们开始重构 first_word 函数吧!该函数可以返回一个切片作为结果。另外,字符串切片的类型写作 &str。
fn first_word(s: &String) -> &str {
let bytes = s.as_bytes();
for (index, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[.. index];
}
}
&s[..]
}
fn main() {
let s = String::from("hello world");
println!("{}", first_word(&s)); // hello
}调用新的 first_word 函数会返回一个与底层数据紧密联系的切片作为结果,它由指向起始位置的引用和描述元素长度的字段组成。当然,我们也可以用同样的方式重构 second_word 函数。
由于编译器会确保指向 String 的引用持续有效,所以我们新设计的接口变得更加健壮且直观了。还记得之前故意构造出的错误吗?那段代码在搜索完成并保存索引后清空了字符串的内容,这使得我们存储的索引不再有效。因此它在逻辑上明显是有问题的,却不会触发任何编译错误,这个问题只会在使用第一个单词的索引去读取空字符串时暴露出来,而切片的引入使我们可以在开发早期快速地发现此类错误。
fn first_word(s: &String) -> &str {
let bytes = s.as_bytes();
for (index, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[.. index];
}
}
&s[..]
}
fn main() {
let mut s = String::from("hello world");
let word = first_word(&s);
s.clear();
println!("{}", word);
}上述代码执行会报错:

错误很明显,s 已经作为不可变引用被借用了,因此不能再作为可变引用被借用。
那么问题来了,s 作为不可变引用借给谁了呢?显然是 word,因为它是字符串切片,是指向字符串的不可变引用;然后又是谁想要借 s 的可变引用呢?显然是 s.clear(),由于 clear 需要截断当前的 String 实例,所以调用 clear 需要传入一个可变引用。
因此最终编译失败,所以 Rust 不仅使我们的 API 更加易用,它还在编译过程中帮助我们避免了此类错误。
字符串字面量就是切片
还记得我们讲的字符串字面量吗?它是直接存储在了二进制程序中。在学习了切片之后,我们现在可以更恰当地理解字符串字面量了。
let s = "hello world";
在这里,变量 s 的类型其实就是 &str:它是一个指向二进制程序特定位置的切片。正是由于&str是一个不可变的引用,所以字符串字面量是不可变的。
字符串切片作为参数
既然我们可以分别创建字符串字面量和 String 的切片,那么就能够进一步优化 first_word 函数的接口,下面是它目前的签名:
fn first_word(s: &String) -> &str
比较有经验的 Rust 开发者往往会采用下面的写法,这种改进后的签名使得函数可以同时处理 &String 与 &str:
fn first_word(s: &str) -> &str
总结:当函数参数类型为 &String,那么只能传 String 的引用,不可以传切片;如果参数类型为 &str,那么既可以传 String 的引用,也可以传切片。说白了,在 String 类型的值前面加上一个 & 就表示 String 的引用(&String),而在引用的基础之上,在后面再加上 [..],那么就表示字符串切片(&str)。
let s1 = String::from("hello world");
// 合法,&str 支持字符串引用
let s2: &str = &s1;
// 合法,&str 支持字符串切片,因为本身就是字符串切片类型
let s2: &str = &s1[..];
// 合法,字符串字面量本身就是一个不可变的字符串切片
let s2: &str = "hello world";
// 以上三者等价,因为 &str 既可以接收 &String,也可以接收 &str
let s3: &String = &s1; // 合法
let s3: &String = &s1[..]; // 不合法
let s3: &String = "hello world"; // 不合法
// 因为 &String 只能接收 &String,不能接收 &str
// 最后,字符串切片虽然能接收 String 的引用,但 String 是无法接收的
// 不合法,&str 只能接收 &str、&String,无法接收 String
let s2: &str = s1; 因此我们在设计函数时,使用字符串切片来代替字符串引用会使我们的 API 更加通用,且不会损失任何功能。
从名字上就可以看出来,字符串切片是专门用于字符串的。但实际上,Rust 还有其他更加通用的切片类型,以下面的数组为例:
let a = [1, 2, 3, 4, 5];
就像我们想要引用字符串的某个部分一样,你也可能会希望引用数组的某个部分。这时,我们可以这样做:
let a = [1, 2, 3, 4, 5]; let slice = &a[1..3];
这里的切片类型是 &[i32],它在内部存储了一个指向起始元素的引用及长度,这与字符串切片的工作机制完全一样。并且我们将在各种各样的集合中接触到此类切片,而在后续讨论动态数组时再来介绍那些常用的集合。

