数据集下载地址:
链接: http://pan.baidu.com/s/17aglKyKFvMvcug0xrOqJdQ?pwd=6i7m
Dogs vs. Cats(猫狗大战)来源Kaggle上的一个竞赛题,任务为给定一个数据集,设计一种算法中的猫狗图片进行判别。
数据集包括25000张带标签的训练集图片,猫和狗各125000张,标签都是以cat or dog命名的。图像为RGB格式jpg图片,size不一样。截图如下:

pytorch的数据预处理部分要写成一个类,这个类继承Dataset类,并必须要实现三个函数。
from torch.utils.data import DataLoader,Dataset
from torchvision import transforms as T
import matplotlib.pyplot as plt
import os
from PIL import Image
class DogCat(Dataset):
def __init__(self, root, transforms=None, train=True):
imgs = [os.path.join(root,img) for img in os.listdir(root)]
imgs_num = len(imgs)
if train:
self.imgs = imgs[:int(0.7 * imgs_num)]
else:
self.imgs = imgs[int(0.3 * imgs_num):]
if transforms is None:
normalize = T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
self.transforms = T.Compose([
T.Resize(224),
T.CenterCrop(224),
T.ToTensor(),
normalize
])
else:
self.transforms = transforms
def __getitem__(self, index):
img_path = self.imgs[index]
# dog label : 1 cat label : 0
label = 1 if "dog" in img_path.split('/')[-1] else 0
data = Image.open(img_path)
data = self.transforms(data)
return data,label
def __len__(self):
return len(self.imgs)__init__为构造函数,我这里用力定义数据路径,数据集划分,transforms。
__getitem__为迭代函数,用来return单个数据的data和label。
__len__返回数据集的长度。
在这个例子中,我们用一个简单的4层卷积,2层全连接,最后跟一个sigmoid输出二分类的概率的CNN网络。
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.nn.functional as F
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 3)
self.conv2 = nn.Conv2d(32, 64, 3)
self.conv3 = nn.Conv2d(64, 128, 3)
self.conv4 = nn.Conv2d(128, 128, 3)
self.max_pool = nn.MaxPool2d(2)
self.relu = nn.ReLU()
self.sigmoid = nn.Sigmoid()
# 12*12 for size(224,224) 7*7 for size(150,150)
self.fc1 = nn.Linear(128*12*12, 512)
self.fc2 = nn.Linear(512, 1)
def forward(self, x):
in_size = x.size(0)
x = self.conv1(x)
x = self.relu(x)
x = self.max_pool(x)
x = self.conv2(x)
x = self.relu(x)
x = self.max_pool(x)
x = self.conv3(x)
x = self.relu(x)
x = self.max_pool(x)
x = self.conv4(x)
x = self.relu(x)
x = self.max_pool(x)
# 展开
x = x.view(in_size, -1)
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
x = self.sigmoid(x)
return xpytorch定义网络时,必须实现两个函数,构造函数主要定义一些网络块,forward函数实现前向推理过程。且在后续代码中,如果定义对象model: ConvNet和数据image,可以直接通过model(image)来调用froward函数(python真的很神奇,C++出身的我理解这些骚操作好难)
数据准备好了,模型网络定义好了,下一步当然是训练权重了。
import torch
import torch.nn as nn
from torch.utils.data import DataLoader,Dataset
from dataset import DogCat
from network import ConvNet
from draw import draw_acc,draw_loss
train_data_root = "/home/elvis/workfile/dataset/dataset_kaggledogvscat/train"
batch_size = 256
# 1. prepare dataset
train_data = DogCat(train_data_root, train=True)
val_data = DogCat(train_data_root, train=False)
train_dataloader = DataLoader(train_data,batch_size=batch_size,shuffle=True)
val_dataloader = DataLoader(val_data,batch_size=batch_size,shuffle=True)
# 2. load model
model = ConvNet()
if torch.cuda.is_available():
model.cuda()
# 3. prepare super parameters
criterion = nn.BCELoss()
learning_rate = 1e-3
# optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, momentum=0.9)
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# 4. train
train_loss_epoch = []
train_acc_epoch = []
val_loss_epoch = []
val_acc_epoch = []
for epoch in range(1, 10):
model.train()
train_loss = 0;
train_acc = 0;
for batch_idx, (data, target) in enumerate(train_dataloader):
if torch.cuda.is_available():
data, target = data.cuda(), target.cuda().float().unsqueeze(-1)
else:
data, target = data, target.float().unsqueeze(-1)
optimizer.zero_grad()
output = model(data)
# print(output)
loss = criterion(output, target)
train_loss += loss.item();
pred = torch.tensor([[1] if num[0] >= 0.5 else [0] for num in output]).cuda();
train_acc += pred.eq(target.long()).sum().item();
loss.backward()
optimizer.step()
if(batch_idx+1)%10 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, (batch_idx+1) * len(data), len(train_dataloader.dataset),
100. * (batch_idx+1) / len(train_dataloader), loss.item()))
train_loss_epoch.append(train_loss / len(train_dataloader));
train_acc_epoch.append(train_acc / len(train_dataloader.dataset));
print('\nTrain set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)'.format(train_loss / len(train_dataloader), train_acc, len(train_dataloader.dataset),
100. * train_acc / len(train_dataloader.dataset)));
# val
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for batch_idx, (data, target) in enumerate(val_dataloader):
if torch.cuda.is_available():
data, target = data.cuda(), target.cuda().float().unsqueeze(-1)
else:
data, target = data, target.float().unsqueeze(-1)
output = model(data)
# print(output)
test_loss += criterion(output, target).item(); #每个批次平均,一个epoch里所有批次求和
pred = torch.tensor([[1] if num[0] >= 0.5 else [0] for num in output]).cuda()
correct += pred.eq(target.long()).sum().item()
print('Valid set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(test_loss/len(val_dataloader), correct, len(val_dataloader.dataset),
100. * correct / len(val_dataloader.dataset)));
val_loss_epoch.append(test_loss / len(val_dataloader));
val_acc_epoch.append(correct / len(val_dataloader.dataset));
# Save model
val_acc_rate = correct / len(val_dataloader.dataset);
save = True
best = "best.pt"
last = "last.pt"
if save:
# Save last, best and delete
torch.save(model.state_dict(), last)
if val_acc_rate == max(val_acc_epoch):
torch.save(model.state_dict(), best)
print("save epoch {} model".format(epoch))
# 5. drawing
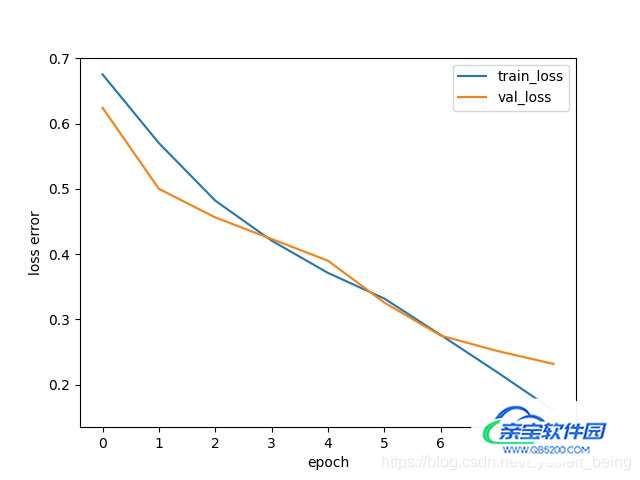
draw_loss(train_loss_epoch, val_loss_epoch)
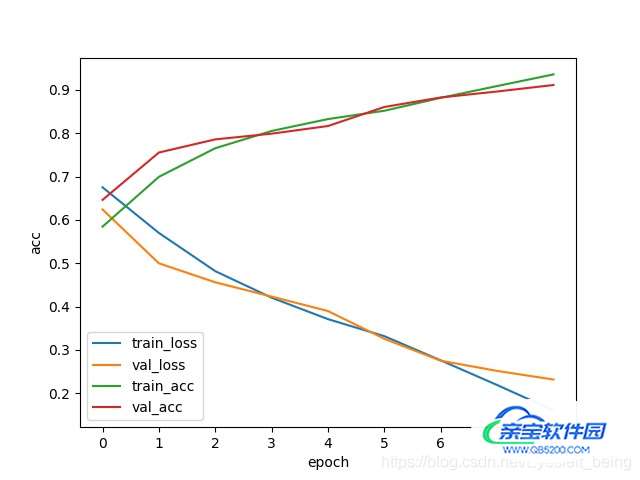
draw_acc(train_acc_epoch,val_acc_epoch)第一步,准备数据。先用我们之前定义的DogCat类来加载数据,但这个类继承自dataset,是加载一条数据的。如果要批量加载数据,还要用pytorch内部的另一个类DataLoader,然后在构造函数里传入batchsize就可以批量加载数据了。注意这里的类对象实际是一个生成器,后续通过循环就可以一直批量的去取数据了。
第二步,定义模型对象,有用显卡就把模型放在显卡上,没有的话就用cpu跑。
第三步,定义一些超参数。因为是二分类,网络最后一层为sigmoid输出类别的概率值,所以选用二分类交叉熵损失函数。再设置一下学习率和优化器。
第四步,训练n个epoch。在每一个epoch里计算训练集准去率,验证集准确率,并保存模型。
最后结果像这样
有条件的可以多训练几个epoch试试。

