故事还得从下面的图说起:
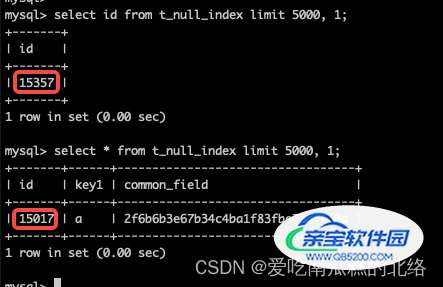
what? 两条sql执行结果的id列居然不一致。。。。。。
为了故事的顺利发展,我们得先创建一张表:
CREATE TABLE `t_null_index` ( `id` int unsigned NOT NULL AUTO_INCREMENT, `key1` char(1) DEFAULT NULL, `common_field` varchar(100) DEFAULT NULL, PRIMARY KEY (`id`), KEY `idx_key1` (`key1`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb3
表 t_null_index 包含3个列,id列是主键,key1列是二级索引列。表中包含9999条数据。
mysql> select * from t_null_index order by key1 limit 1;
+-------+------+----------------------------------+
| id | key1 | common_field |
+-------+------+----------------------------------+
| 10019 | a | a9ecd8f845cd4e6791e99af406e075c1 |
+-------+------+----------------------------------+
1 row in set (0.00 sec)
mysql> explain select * from t_null_index order by key1 limit 1;
+----+-------------+--------------+------------+-------+---------------+----------+---------+------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------+------------+-------+---------------+----------+---------+------+------+----------+-------+
| 1 | SIMPLE | t_null_index | NULL | index | NULL | idx_key1 | 4 | NULL | 1 | 100.00 | NULL |
+----+-------------+--------------+------------+-------+---------------+----------+---------+------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
当我们执行上面的这条sql,是使用了 idx_key1 二级索引,这个好理解,因为在二级索引idx_key1中,key1列是有序的。而查询是要取按照key1列排序的第1条记录,那MySQL只需要从idx_key1中获取到第一条二级索引记录,然后直接回表得到完整聚簇索引的记录返回客户端即可。
但是如果我们把上边语句的 limit 1 换成 limit 5000, 1,效果会如何?
mysql> select * from t_null_index order by key1 limit 5000, 1;
+-------+------+----------------------------------+
| id | key1 | common_field |
+-------+------+----------------------------------+
| 10125 | e | e90499ca17b44727ab44a08c1cf609e8 |
+-------+------+----------------------------------+
1 row in set (0.00 sec)
mysql> explain select * from t_null_index order by key1 limit 5000, 1;
+----+-------------+--------------+------------+------+---------------+------+---------+------+------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------+------------+------+---------------+------+---------+------+------+----------+----------------+
| 1 | SIMPLE | t_null_index | NULL | ALL | NULL | NULL | NULL | NULL | 9847 | 100.00 | Using filesort |
+----+-------------+--------------+------------+------+---------------+------+---------+------+------+----------+----------------+
1 row in set, 1 warning (0.01 sec)
当 limit 1 换成 limit 5000, 1 后,我们发现没有使用 idx_key1 二级索引,反而使用了全表扫描,并且进行 Using filesort。
开始我很不理解,limit 5000, 1 也可以使用二级索引 idx_key1啊,我们可以先扫描到第5001条二级索引记录,对5001条二级索引记录通过主键id回表取得完成聚簇索引记录不就好了吗?这样的代价也比全表扫描+filesort牛批啊。
Limit具体是怎么搞?
我们知道,MySQL 内部其实是分为 server层 和 存储引擎层,具体 server层和存储引擎层具体的交互这里就不说了。
对于limit的操作,MySQL是在server层准备向客户端发送记录的时候才会去处理limit子句中的内容。
select * from t_null_index order by key1 limit 5000, 1;
如果使用 idx_key1 索引执行上述查询,那么MySQL会这样处理:
(1)server层向InnoDB要第1条记录,InnoDB从idx_key1中获取到第1条二级索引记录,然后进行回表操作得到完整的聚簇索引记录,然后返回给server层。server层准备将其发送给客户端,此时发现还有个limit 5000, 1的要求,意味着符合条件的记录中的第5001条才可以返回给客户端,则不能将记录返回给客户端,同时会先记录下当前是第1条。
(2)server层再向InnoDB要下一条记录,InnoDB再根据二级索引记录的next_record属性找到下一条二级索引记录,再次进行回表得到完整的聚簇索引记录返回给server层。server层再将其发送给客户端的时候发现当前记录仍然不是5001条,所以就放弃了将记录发送给客户端,同时将记录数+1。
(3)。。。重复上述操作
(4)直到server层发现InnoDB返回的聚簇索引记录是5001条的时候,server层才会将InnoDB返回的完整聚簇索引记录发送给客户端。
从上述过程中我们可以看出,由于MySQL中是server层实际向客户端发送记录前才会判断limit子句是否符合要求,所以如果使用二级索引执行上述查询的话,意味着需要进行5001次回表操作。server层在执行执行计划分析的时候会觉得执行这么多次回表的成本太大了,还不如直接 全表扫描+filesort 快呢,所以就选择了 全表扫描+filesort 执行查询。
说着说着,差点忘记了故事的前奏的图了

