在爬虫的世界里,xpath是一种非常简单易用的匹配规则,方便我们在web世界里提取需要的各类信息。
本文将讲述一个xpath规则无效的问题分析过程。
Python 3.6.1 Scrapy 1.5.0
在选用xpath之时,都是基于firefox或者chrome中自带的Web开发工具来选取的。
这里一般推荐使用chrome的devtool,功能强大,简单易用,童叟无欺,居家旅游必须良品呀。
具体示意如下:
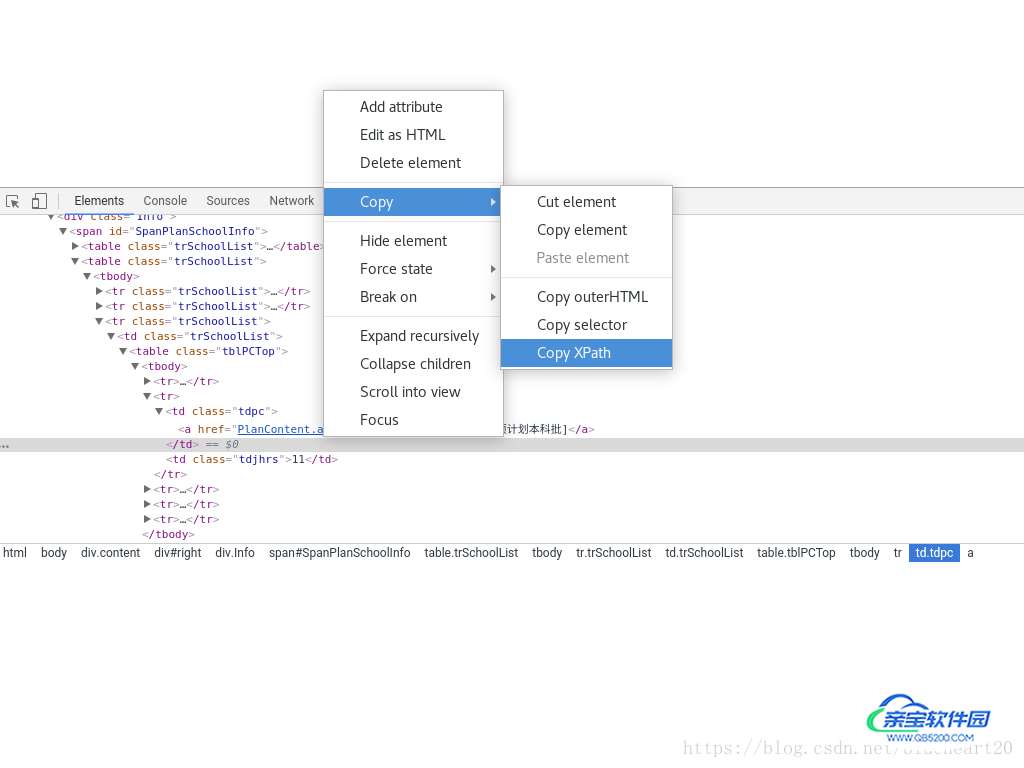
基于xpath提取的路径信息,示例如下:
//*[@id=”SpanPlanSchoolInfo”]/table[2]/tbody/tr[3]/td/table/tbody/tr[2]/td[1]/a
在Scrapy代码中使用如下:
def parse(self, response):
xpath_url = '//*[@id="SpanPlanSchoolInfo"]/table[2]/tbody/tr[3]/td/table/tbody/tr[2]/td[1]/a'
urls = response.xpath(xpath_url)
.....但是在实际执行中,却一直没有匹配到urls,根据实际上页面返回正常,同时数据也是正确可以匹配到的,那问题出现在哪里呢?
根据结果来分析,如果页面存在,但是没有正确的结果输出,则一定是xpath的问题,但是xpath问题是基于chrome自带的devtools工具copy而来的,怎么可能出错恩?真是让人想不透的问题…….
在经过一番深入的反复尝试之后,主要是基于scrapy提供的强大的scrapy shell交互工具,可以帮助开发者快速地一步一步地定位问题。
于是采取了逐步缩小xpath的方式,逐步定位问题,终于找到了问题的原因所在,那就是tbody是一个需要移除的tag标签。
将正确的xpath设置为:
//*[@id=”SpanPlanSchoolInfo”]/table[2]/tr[3]/td/table/tbody/tr[2]/td[1]/a
虽然问题解决了,但是原因是什么呢?
经过分析,主要是由于浏览器本身自动为table新增了tbody标签内容,但是在xpath中是不需要的,需要在进行xpath查询之时移除掉。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。

