使用 Python 可以使用机器学习模型进行温度预测。常用的模型有回归分析、随机森林等。使用前需要准备足够的历史数据并进行特征工程,构建模型并进行训练,最后使用预测结果。
以下代码使用线性回归算法对温度数据进行预测:
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
# 读入温度数据
data = pd.read_csv('temperature_data.csv')
# 分离特征和标签
X = data[['day_of_year', 'year']]
y = data['temperature']
# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 训练模型
reg = LinearRegression().fit(X_train, y_train)
# 预测结果
y_pred = reg.predict(X_test)
# 评估模型
score = reg.score(X_test, y_test)
print('R2 score: ', score)
导入必要的库:
import pandas as pd:用于读取 CSV 文件并处理数据。import numpy as np:用于进行数值运算。from sklearn.linear_model import LinearRegression:从 scikit-learn 库导入线性回归模型。from sklearn.model_selection import train_test_split:从 scikit-learn 库导入数据分割函数。读取温度数据:
data = pd.read_csv('temperature_data.csv'):使用 pandas 读取 CSV 文件并保存到 data 变量中。
分离特征和标签:
X = data[['day_of_year', 'year']]:将温度数据中的 day_of_year 和 year 列作为特征,存储到 X 变量中。y = data['temperature']:将温度数据中的 temperature 列作为标签,存储到 y 变量中。分割数据集:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2):使用 train_test_split() 函数将数据分为训练集和测试集,其中测试集大小为 20%。
训练模型:
reg = LinearRegression().fit(X_train, y_train):使用训练集数据训练线性回归模型,并保存到 reg 变量中。
预测结果:
y_pred = reg.predict(X_test):使用测试集数据预测结果,并保存到 y_pred 变量中。
评估:
print('R-squared:', reg.score(X_test, y_test)):使用 R-squared 值评估模型的预测精度,其值越接近 1,表示模型预测精度越高。
temperature_data.csv 文件是一个温度数据的 CSV 文件,可能包含以下字段:
day_of_year,year,temperature 1,2021,20.5 2,2021,21.6 3,2021,22.7 365,2021,19.4 1,2022,18.5 2,2022,19.6
day_of_year 列表示一年中的第几天,year 列表示该天的年份,temperature 列表示该天的温度。
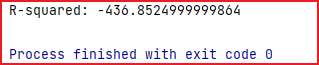
运行代码得到下述截图。

以下是随机森林回归的 Python 代码:
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
# 读取温度数据
data = pd.read_csv('temperature_data.csv')
# 分离特征和标签
X = data[['day_of_year', 'year']]
y = data['temperature']
# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 训练模型
reg = RandomForestRegressor(n_estimators=100).fit(X_train, y_train)
# 预测结果
y_pred = reg.predict(X_test)
# 评估模型
print('R-squared:', reg.score(X_test, y_test))
代码说明如下:
import pandas as pd :导入 pandas 库。from sklearn.ensemble import RandomForestRegressor :导入随机森林回归算法。from sklearn.model_selection import train_test_split :导入数据集分割工具。data = pd.read_csv('temperature_data.csv') :读取温度数据。X = data[['day_of_year', 'year']] :提取特征数据(特征:一年中的第几天和年份)。y = data['temperature'] :提取标签数据(标签:温度)。X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) :将数据集分为训练集和测试集,其中测试集的数据占 20%。reg = RandomForestRegressor(n_estimators=100).fit(X_train, y_train) :使用随机森林回归算法训练模型。y_pred = reg.predict(X_test) :使用训练好的模型对测试集数据进行预测。print('R-squared:', reg.score(X_test, y_test)):使用 R-squared 值评估模型的预测精度,其值越接近 1,表示模型预测精度越高。代码运行结果: