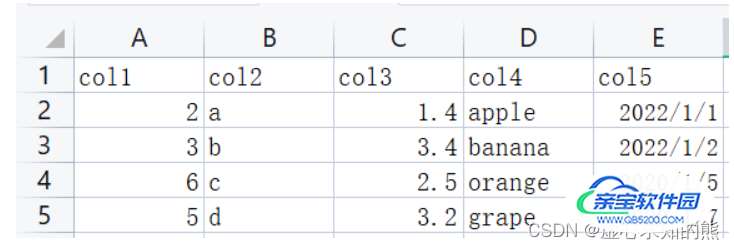
首先,我们对 CSV 文件进行读取,可以通过相对路径,也可以通过 os 动态取得绝对路径 os.getcwd() os.path.json。
import pandas as pd
df = pd.read_csv("./data/my_csv.csv")
print(df,type(df))
# col1 col2 col3 col4 col5
#0 2 a 1.4 apple 2022/1/1
#1 3 b 3.4 banana 2022/1/2
#2 6 c 2.5 orange 2022/1/5
#3 5 d 3.2 grape 2022/1/7 <class 'pandas.core.frame.DataFrame'>我们可以通过 os.getcwd() 读取文件的存储路径。
import os os.getcwd() #'C:\\Users\\CQB\\Desktop\\内蒙农业大学数据分析教案和代码\\第16天'
其语法模板如下:
read_csv(filepath_or_buffer, sep=',', header='infer', names=None, index_col=None, usecols=None, squeeze=None, prefix=None, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, skipfooter=0, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=None, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, cache_dates=True, iterator=False, chunksize=None, compression='infer', thousands=None, decimal='.', lineterminator=None, quotechar='"', quoting=0, doublequote=True, escapechar=None, comment=None, encoding=None, encoding_errors='strict', dialect=None, error_bad_lines=None, warn_bad_lines=None, on_bad_lines=None, delim_whitespace=False, low_memory=True, memory_map=False, float_precision=None, storage_options=None)
import pandas as pd pd.read_csv(r"data\students.csv") #id name address gender birthday #0 1 朱梦雪 地球村 女 2004/11/2 #1 2 许文博 月亮星 女 2003/8/7 #2 3 张兆媛 艾尔星 女 2004/11/2 #3 4 付延旭 克哈星 男 2003/10/11 #4 5 王杰 查尔星 男 2002/6/12 #5 6 董泽宇 塔桑尼斯 男 2002/2/12
pd.read_csv("http://my-teaching.top/static/data/students.csv") 里面还可以是一个 _io.TextIOWrapper,其中,pandas 默认使用 utf-8 读取文件,比如:
f = open(r"data\students.csv", encoding="utf-8") pd.read_csv(f) #id name address gender birthday #0 1 朱梦雪 地球村 女 2004/11/2 #1 2 许文博 月亮星 女 2003/8/7 #2 3 张兆媛 艾尔星 女 2004/11/2 #3 4 付延旭 克哈星 男 2003/10/11 #4 5 王杰 查尔星 男 2002/6/12 #5 6 董泽宇 塔桑尼斯 男 2002/2/12
(2) sep:读取 csv 文件时指定的分隔符,默认为逗号。注意:csv 文件的分隔符和我们读取 csv 文件时指定的分隔符一定要一致。
import pandas as pd pd.read_csv(r"data\students_step.csv") #id|name|address|gender|birthday #0 1|朱梦雪|地球村|女|2004/11/2 #1 2|许文博|月亮星|女|2003/8/7 #2 3|张兆媛|艾尔星|女|2004/11/2 #3 4|付延旭|克哈星|男|2003/10/11 #4 5|王杰|查尔星|男|2002/6/12 #5 6|董泽宇|塔桑尼斯|男|2002/2/12
由于指定的分隔符和 csv 文件采用的分隔符不一致,因此多个列之间没有分开,而是连在一起了。 所以,我们需要将分隔符设置成 \t 才可以。
df = pd.read_csv(r"data\students_step.csv", sep="|") df #id name address gender birthday #0 1 朱梦雪 地球村 女 2004/11/2 #1 2 许文博 月亮星 女 2003/8/7 #2 3 张兆媛 艾尔星 女 2004/11/2 #3 4 付延旭 克哈星 男 2003/10/11 #4 5 王杰 查尔星 男 2002/6/12 #5 6 董泽宇 塔桑尼斯 男 2002/2/12
(3) delim_whitespace:默认为 False,设置为 True 时,表示分割符为空白字符,可以是空格、\t 等等。不管分隔符是什么,只要是空白字符,那么可以通过 delim_whitespace=True 进行读取。如下,我们对 delim_whitespace 不设置,也就是默认为 False,会发现读取有点问题。
df = pd.read_csv(r"data\students_whitespace.txt", sep=" ") df #id name address gender birthday #0 1 朱梦雪 地球村 女 2004/11/2 #1 2 许文博\t月亮星 女 2003/8/7 NaN #2 3 张兆媛 艾尔星 女 2004/11/2 #3 4 付延旭 克哈星 男 2003/10/11 #4 5 王杰\t查尔星 男 2002/6/12 NaN #5 6 董泽宇\t塔桑尼斯 男 2002/2/12 NaN
对此,我们将 delim_whitespace 设置为 True,便会得到我们想要的读取结果。
df = pd.read_csv(r"data\students_whitespace.txt", delim_whitespace=True) df #id name address gender birthday #0 1 朱梦雪 地球村 女 2004/11/2 #1 2 许文博 月亮星 女 2003/8/7 #2 3 张兆媛 艾尔星 女 2004/11/2 #3 4 付延旭 克哈星 男 2003/10/11 #4 5 王杰 查尔星 男 2002/6/12 #5 6 董泽宇 塔桑尼斯 男 2002/2/12
pd.read_csv(r"data\students.csv") #id name address gender birthday #0 1 朱梦雪 地球村 女 2004/11/2 #1 2 许文博 月亮星 女 2003/8/7 #2 3 张兆媛 艾尔星 女 2004/11/2 #3 4 付延旭 克哈星 男 2003/10/11 #4 5 王杰 查尔星 男 2002/6/12 #5 6 董泽宇 塔桑尼斯 男 2002/2/12
pd.read_csv(r"data\students.csv", header=1) #1 朱梦雪 地球村 女 2004/11/2 #0 2 许文博 月亮星 女 2003/8/7 #1 3 张兆媛 艾尔星 女 2004/11/2 #2 4 付延旭 克哈星 男 2003/10/11 #3 5 王杰 查尔星 男 2002/6/12 #4 6 董泽宇 塔桑尼斯 男 2002/2/12
(c) names 被赋值,header 没有被赋值:
pd.read_csv(r"data\students.csv", names=["编号", "姓名", "地址", "性别", "出生日期"]) #编号 姓名 地址 性别 出生日期 #0 id name address gender birthday #1 1 朱梦雪 地球村 女 2004/11/2 #2 2 许文博 月亮星 女 2003/8/7 #3 3 张兆媛 艾尔星 女 2004/11/2 #4 4 付延旭 克哈星 男 2003/10/11 #5 5 王杰 查尔星 男 2002/6/12 #6 6 董泽宇 塔桑尼斯 男 2002/2/12
pd.read_csv(r"data\students.csv",
names=["编号", "姓名", "地址", "性别", "出生日期"],
header=1)
#编号 姓名 地址 性别 出生日期
#0 2 许文博 月亮星 女 2003/8/7
#1 3 张兆媛 艾尔星 女 2004/11/2
#2 4 付延旭 克哈星 男 2003/10/11
#3 5 王杰 查尔星 男 2002/6/12
#4 6 董泽宇 塔桑尼斯 男 2002/2/12df = pd.read_csv(r"data\students.csv", index_col="birthday") df # id name address gender #birthday #2004/11/2 1 朱梦雪 地球村 女 #2003/8/7 2 许文博 月亮星 女 #2004/11/2 3 张兆媛 艾尔星 女 #2003/10/11 4 付延旭 克哈星 男 #2002/6/12 5 王杰 查尔星 男 #2002/2/12 6 董泽宇 塔桑尼斯 男
也可以用来删除指定列。
df.index=df['birthday'] del df['birthday'] df # id name address gender #birthday #2004/11/2 1 朱梦雪 地球村 女 #2003/8/7 2 许文博 月亮星 女 #2004/11/2 3 张兆媛 艾尔星 女 #2003/10/11 4 付延旭 克哈星 男 #2002/6/12 5 王杰 查尔星 男 #2002/2/12 6 董泽宇 塔桑尼斯 男
我们在读取的时候指定了 name 列作为索引; 此外,除了指定单个列,还可以指定多列作为索引,比如 [“id”, “name”]。同时,我们除了可以输入列名外,还可以输入列对应的索引。比如:“id”、“name”、“address”、"date"对应的索引就分别是 0、1、2、3。
df2 = pd.read_csv(r"data\students.csv", index_col=["gender","birthday"]) df2 # id name address #gender birthday #女 2004/11/2 1 朱梦雪 地球村 # 2003/8/7 2 许文博 月亮星 # 2004/11/2 3 张兆媛 艾尔星 #男 2003/10/11 4 付延旭 克哈星 # 2002/6/12 5 王杰 查尔星 # 2002/2/12 6 董泽宇 塔桑尼斯
使用 loc 删选也是同样的道理。
df2.loc["女"] # id name address #birthday #2004/11/2 1 朱梦雪 地球村 #2003/8/7 2 许文博 月亮星 #2004/11/2 3 张兆媛 艾尔星
pd.read_csv(r"data\students.csv", usecols=["name","birthday"]) # name #0 朱梦雪 #1 许文博 #2 张兆媛 #3 付延旭 #4 王杰 #5 董泽宇
(1) encoding:表示这只编码格式,utf-8,gbk。
pd.read_csv(r"data\students_gbk.csv") # UnicodeDecodeError
pd.read_csv(r"data\students_gbk.csv", encoding="gbk") #id name address gender birthday #0 1 朱梦雪 地球村 女 2004/11/2 #1 2 许文博 月亮星 女 2003/8/7 #2 3 张兆媛 艾尔星 女 2004/11/2 #3 4 付延旭 克哈星 男 2003/10/11 #4 5 王杰 查尔星 男 2002/6/12 #5 6 董泽宇 塔桑尼斯 男 2002/2/12
df = pd.read_csv(r"data\students_step_001.csv", sep="|") df #id name address gender birthday #0 1 朱梦雪 地球村 女 2004/11/2 #1 2 许文博 月亮星 女 2003/8/7 #2 3 张兆媛 艾尔星 女 2004/11/2 #3 4 付延旭 克哈星 男 2003/10/11 #4 5 王杰 查尔星 男 2002/6/12 #5 6 董泽宇 塔桑尼斯 男 2002/2/12
我们将 id 的数据类型设置为字符串,便可以显示为 001 之类的。
df = pd.read_csv(r"data\students_step_001.csv", sep="|", dtype ={"id":str})
df
#id name address gender birthday
#0 001 朱梦雪 地球村 女 2004/11/2
#1 002 许文博 月亮星 女 2003/8/7
#2 003 张兆媛 艾尔星 女 2004/11/2
#3 004 付延旭 克哈星 男 2003/10/11
#4 005 王杰 查尔星 男 2002/6/12
#5 006 董泽宇 塔桑尼斯 男 2002/2/12pd.read_csv('data\students.csv', converters={"id": lambda x: int(x) + 10})
#id name address gender birthday
#0 11 朱梦雪 地球村 女 2004/11/2
#1 12 许文博 月亮星 女 2003/8/7
#2 13 张兆媛 艾尔星 女 2004/11/2
#3 14 付延旭 克哈星 男 2003/10/11
#4 15 王杰 查尔星 男 2002/6/12
#5 16 董泽宇 塔桑尼斯 男 2002/2/12pd.read_csv('data\students.csv', true_values=['男'], false_values=['女'])
# id name address gender birthday
#0 1 朱梦雪 地球村 False 2004/11/2
#1 2 许文博 月亮星 False 2003/8/7
#2 3 张兆媛 艾尔星 False 2004/11/2
#3 4 付延旭 克哈星 True 2003/10/11
#4 5 王杰 查尔星 True 2002/6/12
#5 6 董泽宇 塔桑尼斯 True 2002/2/12pd.read_csv('data\students.csv', skiprows=[0,3])
# 1 朱梦雪 地球村 女 2004/11/2
#0 2 许文博 月亮星 女 2003/8/7
#1 4 付延旭 克哈星 男 2003/10/11
#2 5 王杰 查尔星 男 2002/6/12
#3 6 董泽宇 塔桑尼斯 男 2002/2/12这里把第一行过滤掉了,因为第一行是表头,所以在过滤掉之后第二行就变成表头了。 当然里面除了传入具体的数值,来表明要过滤掉哪些行,还可以传入一个函数。
pd.read_csv('data\students.csv', skiprows=lambda x: x > 0 and x % 2 == 0)
# id name address gender birthday
#0 1 朱梦雪 地球村 女 2004/11/2
#1 3 张兆媛 艾尔星 女 2004/11/2
#2 5 王杰 查尔星 男 2002/6/12pd.read_csv('data\students.csv', skipfooter=1)上述代码运行后会出现报错,并且表格中的数据都变成乱码,具体原因下方有解释。
pd.read_csv('data\students.csv', skipfooter=1, engine="python", encoding="utf-8")
# id name address gender birthday
#0 1 朱梦雪 地球村 女 2004/11/2
#1 2 许文博 月亮星 女 2003/8/7
#2 3 张兆媛 艾尔星 女 2004/11/2
#3 4 付延旭 克哈星 男 2003/10/11
#4 5 王杰 查尔星 男 2002/6/12pd.read_csv('data\students.csv', nrows=3)
# id name address gender birthday
#0 1 朱梦雪 地球村 女 2004/11/2
#1 2 许文博 月亮星 女 2003/8/7
#2 3 张兆媛 艾尔星 女 2004/11/2na_values:该参数可以配置哪些值需要处理成 NaN。
pd.read_csv('data\students.csv', na_values=["女", "朱梦雪"])
#id name address gender birthday
#0 1 NaN 地球村 NaN 2004/11/2
#1 2 许文博 月亮星 NaN 2003/8/7
#2 3 张兆媛 艾尔星 NaN 2004/11/2
#3 4 付延旭 克哈星 男 2003/10/11
#4 5 王杰 查尔星 男 2002/6/12
#5 6 董泽宇 塔桑尼斯 男 2002/2/12可以看到将女和朱梦雪设置成了NaN,这里的情况是不同的列中包含了不同的值。
df = pd.read_csv('data\students.csv')
df.dtypes
#id int64
#name object
#address object
#gender object
#birthday object
#dtype: object我们通过 parse_dates 将 birthday 设置为时间类型。
df = pd.read_csv('data\students.csv', parse_dates=["birthday"])
df.dtypes
#id int64
#name object
#address object
#gender object
#birthday datetime64[ns]
#dtype: objectchunk = pd.read_csv('data\students.csv', iterator=True)
chunk
#<pandas.io.parsers.TextFileReader at 0x1b27f00ef88>我们已经对文件进行了分块操作,可以先提取出前两行。
print(chunk.get_chunk(2)) # id name address gender birthday #0 1 朱梦雪 地球村 女 2004/11/2 #1 2 许文博 月亮星 女 2003/8/7
文件还剩下四行,但是我们指定读取100,那么也不会报错,不够指定的行数,那么有多少返回多少。
print(chunk.get_chunk(100)) # id name address gender birthday #2 3 张兆媛 艾尔星 女 2004/11/2 #3 4 付延旭 克哈星 男 2003/10/11 #4 5 王杰 查尔星 男 2002/6/12 #5 6 董泽宇 塔桑尼斯 男 2002/2/12
这里需要注意的是,在读取完毕之后,再读的话就会报错了。(2) chunksize:整型,默认为 None,设置文件块的大小。chunksize 还是返回一个类似于迭代器的对象,当我们调用 get_chunk,如果不指定行数,那么就是默认的 chunksize。
chunk = pd.read_csv('data\students.csv', chunksize=2)
print(chunk)
print(chunk.get_chunk())
#<pandas.io.parsers.TextFileReader object at 0x000001B27F05C5C8>
# id name address gender birthday
#0 1 朱梦雪 地球村 女 2004/11/2
#1 2 许文博 月亮星 女 2003/8/7
