本文主要介绍在压测HBase的二级索引phoenix时踩的一个坑,使用时需要特别注意,而且背后的原因也很有意思,可以看出HBase和Phoenix对元数据设计上的差异。
在做phoenix压测时发现一个奇怪的现象。
压测请求分布非常均匀,但是有一台机器的流量、负载都明显高于其他机器。
如下图所示。
请求均匀
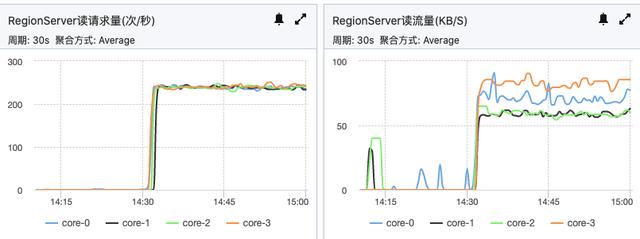
资源利用率不均匀,单个节点明显偏高。
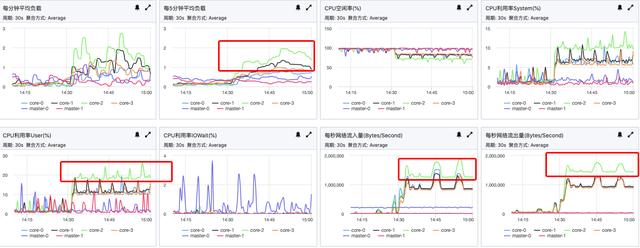
看到这个问题的第一反应,是去看下表分布是否均匀。
令人遗憾的是,确认后hbase表和索引表都是均匀分布的,各个机器上的region数量、存储用量都是一致,非常均匀。
然后在网上查相关资料,在官网上看到这样一段描述。(http://phoenix.apache.org/language/index.html)
UPDATE_CACHE_FREQUENCY option (available as of Phoenix 4.7) determines how often the server will be checked for meta data updates (for example, the addition or removal of a table column or the updates of table statistics). Possible values are ALWAYS (the default), NEVER, and a millisecond numeric value. An ALWAYS value will cause the client to check with the server each time a statement is executed that references a table (or once per commit for an UPSERT VALUES statement). A millisecond value indicates how long the client will hold on to its cached version of the metadata before checking back with the server for updates.
大致的意思是,phoenix的表设计时有一个表级别参数UPDATE_CACHE_FREQUENCY,这个参数默认是ALWAYS,表示每次sql查询都会先去请求meta数据。也可以设置为一定频率,表示多久去请求一次meta数据。
那我们大概能猜想到了,因为设计表的时候没有指定这个参数,所以为默认的always,而phoenix的meta数据正好落在了那个机器上。
我们查验了下系统表的位置,果然如此!
于是立刻做了变更
alter table xxx set UPDATE_CACHE_FREQUENCY = xxxxx。
效果显著!
不仅流量、负载均匀了,而且整体负载下降了很多!!!
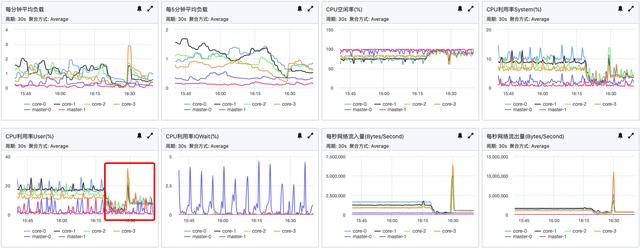
那为什么监控上请求量是均匀的呢?因为phoenix需要访问catalog表,然后这个表刚才在core-2上,访问这个表走的coprocessor,所以没统计出请求数。
到上面为止,问题的原因找到了,也解决了。
但是熟悉HBase的同学肯定会马上有个疑问,跟我一样。为什么会有这样一个参数设置,HBase本身也有meta表,而HBase的meta表在客户端缓存就可以。
下面,就让我们来思考下。
1)phoenix为什么要这么设计呢,而不是像hbase的meta表一样?
这个问题得从phoenix的架构设计说起。
phoenix一直以来,都是重客户端模式,即使是现在的轻客户端版本,本质也是如此。只不过把客户端放在了query server这个角色上,让query server跑在服务端了。
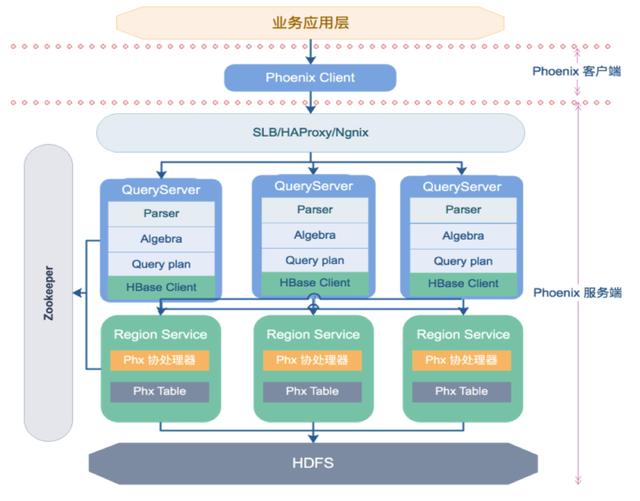
但对hbase来说,phoenix的核心逻辑都在client侧。元数据管理也是如此。phoenix和HBase不同的是,phoenix的元数据更复杂,如果元数据有变化,没有拿到最新meta的客户端不一定会抛错。
举个例子,比如一个查询命中索引后会更高效。但是,某个客户端它 不知道有这个索引表,于是就去查了主表,这个在phoenix上看也没有毛病。
所以,关键原因是phoenix无法感知元数据是否发生了变化!而HBase可以。
因此,最初为了解决元数据同步的问题,就采用了比较激进的每次刷新的方式。后来发现会影响性能,就加了一个周期性刷新的功能,来避免per request去刷meta数据。
2)那可以alter table时触发meta更新吗?
这个是不可以的。因为客户端可能比较多。而且,也不会有一个地方去记录全局有哪些client。即使有这样一个地方,那某个client挂了怎么办?没有通知成功怎么办?此时,alter操作是成功还是不成功呢?
3)结论
所以这个参数是phoenix的设计,而不是缺陷。phoenix默认情况下,每个请求都会去校验一次表的元数据信息,以避免因meta未刷新导致失败。为此,phoenix提供了一个表参数,来控制meta的刷新频率,比如1分钟刷一次,类似这种。
可以在建表的时候设定:
craete table if not exists ns.table_demo (
id varchar not null primary key,
f1.a varchar,
f1.b varchar,
f1.c varchar
)
TTL=86400,
UPDATE_CACHE_FREQUENCY=900000;也可以变更表结构设定:
alter table xxx set UPDATE_CACHE_FREQUENCY = xxxxx; 设一个你期望的刷新时间,就可以解决问题了。
当然,这样带来的副作用就是,如果未来你修改了这个表,比如add了一个新的列,或者新加了一个索引,最少要等待一个刷新周期才能生效。但是无关大局,一般表结构变更就属于低频操作,而且能够接受一定延迟。
看到这里了,原创不易,点个关注、点个赞吧,你最好看了~
知识碎片重新梳理,构建Java知识图谱:https://github.com/saigu/JavaKnowledgeGraph(历史文章查阅非常方便)

