[上节课](https://www.cnblogs.com/gongyanzh/p/12536836.html)学习了seq2seq模型如何用于语音识别,这节课我们将学习如何将语言模型加入到模型中
---
### 为什么需要语言模型
- token sequence 的概率
- token sequence: $Y=y_1,y_2,...,y_n$
- $P(y_1,y_2,...,y_n)$
token 可以是字符、词等等,可以见[深度学习与人类语言处理-语音识别(part1)](https://www.cnblogs.com/gongyanzh/p/12496037.html)
**HMM**
$$
\begin{equation}\mathrm{Y}^{*}=\arg \max _{\mathrm{Y}} P(X | \mathrm{Y}) P(\mathrm{Y})\end{equation}
$$
在使用HMM进行语音识别时,$P(Y)$就是语言模型
**LAS**
$$
\begin{equation}Y^{*}=\arg \max _{Y} P(Y | X)\end{equation}
$$
在端到端的深度学习模型中,是在给定$X$的情况下找到最大的$Y$,似乎没有语言模型存在的空间,但神奇的是,我们可以直接把Decoding的式子写为
$$
\begin{equation}Y^{*}=\arg \max _{Y} P(Y | X)P(Y)\end{equation}
$$
从概率的角度来看,我们很难解释这个式子的含义,乘个$P(Y)$干啥?但是为什么乘$P(Y)$有用呢,因为$P(Y|X)$和$P(Y)$的数据来源可以不同。具体来说$P(Y|X)$需要收集成对的数据,而$P(Y)$只需要收集大量的文本
成对数据和单独的文本数据量差了多少呢?
google的语言识别系统使用了12500小时的声音信号,包含的词数:$12500*60*130$(60分钟,每分钟平均可以说130个词),大约**1亿**个词
单纯文本数据:BERT用了**30亿**以上的词
> BERT数据是的语音数据的30倍,所以可以很容易的收集到大量文本数据,把$P(Y)$估的比较准,这就是为什么需要加入语言模型
### N-gram
- 怎么估计一个token sequence 的概率?
- 直观的想法,收集大量的数据,统计 $y_1,y_2,...,y_n$这个序列出现的次数,但人类的句子非常复杂,很可能句子没有出现在训练数据中,显然不能因为句子没有在训练数据中出现就认为它出现的概率是0
- N-gram语言模型:$$P\left(y_{1}, y_{2}, \ldots \ldots, y_{n}\right)=P\left(y_{1} | B O S\right) P\left(y_{2} | y_{1}\right) \ldots P\left(y_{n} | y_{n-1}\right)$$,就是二元语言模型,举个栗子
$P(“wreck a nice beach”) =P(wreck|START)P(a|wreck) P(nice|a)P(beach|nice)$
计算$P(beach|nice)$的概率:
$$
P(\text { beach } | \text { nice })=\frac{C(\text {nice beach})}{C(\text {nice})}
$$
#### N-gram 有什么问题?
```
训练数据:
the dog ran...
the cat jumped...
```
估计新句子的概率:
$P(\text { jumped } | \text { the }, \operatorname{dog})=0$
$$P(\text { ran } | \text { the }, \text { cat })=0$$
这显然是不合理的,只是因为出现的概率低,不能设置为0.这种情况需要进行平滑处理,例如add-1 smoothing, add-k smoothing,这个大家可以自行了解。
#### Continuous LM
除了传统的自定义平滑规则,还有一种自动化的平滑方法,continuous LM
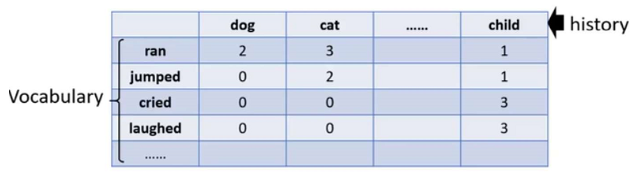
表格中数字表示词数,例如$Count(ran|dog)=3,Count(ran|cat)=3$, 值为0表示训练数据中没有出现,我们想估计它的实际值,我们来看看Continuous LM怎么做

每一个token有一个对应的向量,分别表示为$h,v$, 代表词的属性,需要根据训练集学习得到,假设表中数值用$n$表示,同时假设$n$可以由$v,h$的内积表示,例如
$$
\begin{array}{l}n_{12}=v^{1} \cdot h^{2} \\n_{21}=v^{2} \cdot h^{1} \ldots\end{array}
$$
对应的损失函数:
$$
L=\sum_{(i, j)}\left(v^{i} \cdot h^{j}-n_{i j}\right)^{2}
$$
$n_{i j}$是表中可以直接得到的, $v^{i}, h^{j}$ 可以通过梯度下降求解
将$v^{i} \cdot h^{j}$表示估计到的对应词汇被接在一起的概率
- 这样做有什么好处?
假设“dog”和“cat”有某些同样的属性,就会得到相似的向量$h^{dog}$和$h^{cat}$, 如果训练数据中已经知道“cat”通常会接“jumped”,也就是 $v^{jumped} \cdot h ^{cat}$ 很大,那对应的$ v^{jumped} \cdot h ^{dog}$也会很大, 可以看到这是可以通过学习得到的语言模型平滑方法
看到这里熟悉word2vec的同学会发现这有点像啊,我们来看看他们之间有什么联系?
我们具体看下continuous LM的学习过程
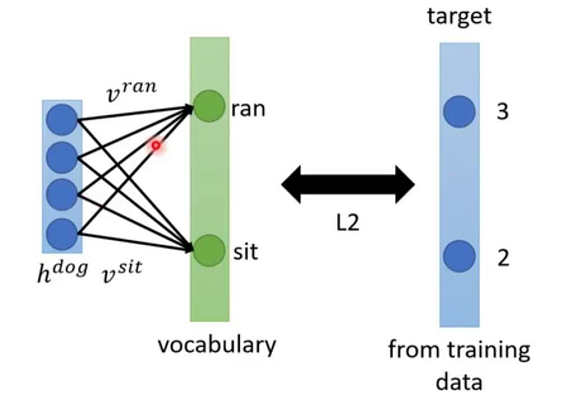
我们希望$h,v$相乘后结果和目标越接近越好
我们可以把这个看作是一个简单神经网络,只有一个隐层,没有激活函数。把h当做参数,输入是one-hot,就得到了下面的样子
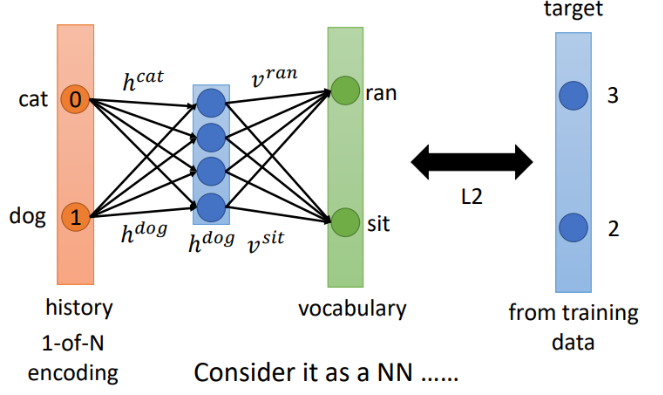
### NN-based LM
我们将上面的模型拓展更深,就是NN-based 语言模型
- training
```
data:
潮水 退了 就 知道 谁 ...
不爽 不要 买 ...
```
假设使用NN代替一个**tri-gram**语言模型,就是输入前两个单词,预测下一个
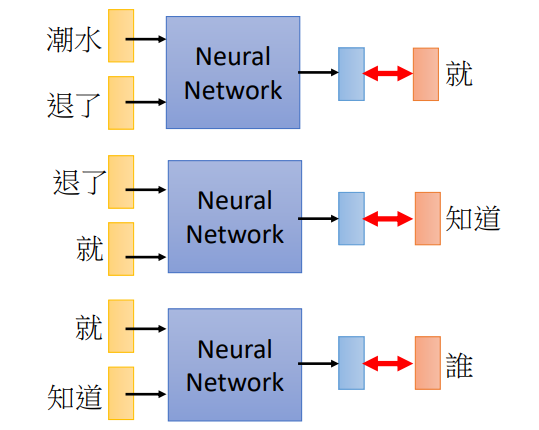
同样的,如果是一个二元语言模型,也可以用NN来代替
$P(“wreck a nice beach”) =P(wreck|START)P(a|wreck)P(nice|a)P(beach|nice)$
$P(b|a)$:NN 预测下一个词的概率
训练如下

实际上NNLM(2003)比continuous LM(2010)出现的还早,只是在语音领域没有引起重视,后来才被挖出来
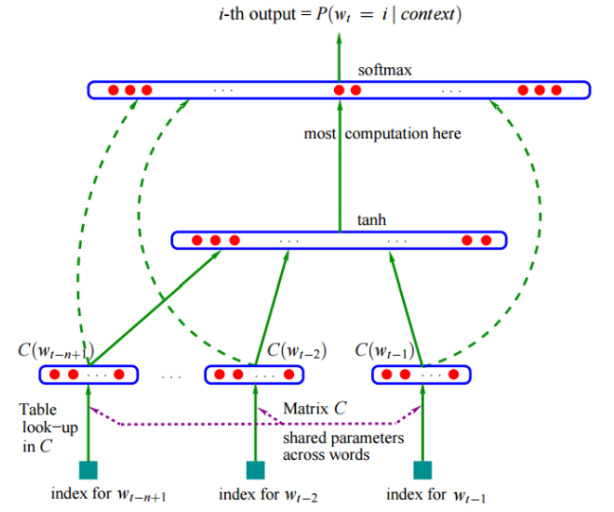
### RNN-based LM
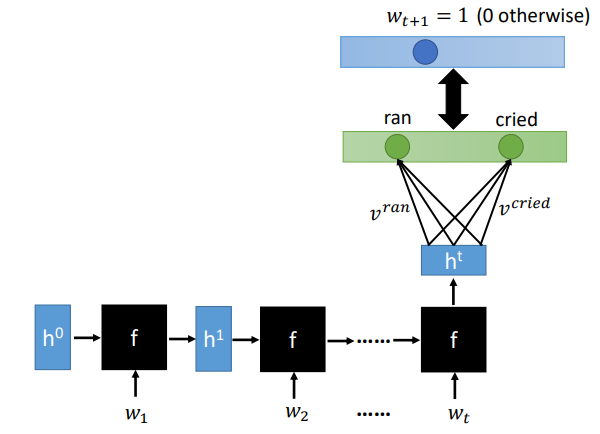
看很长的history决定下一个词,如果用NN的话,输入会非常长,需要非常多的参数,所以引入一个RNN,将历史词输入到RNN,用Ht表示,在乘以每个词对应的v输出下一个词对应的概率
### How to use LM to improve LAS
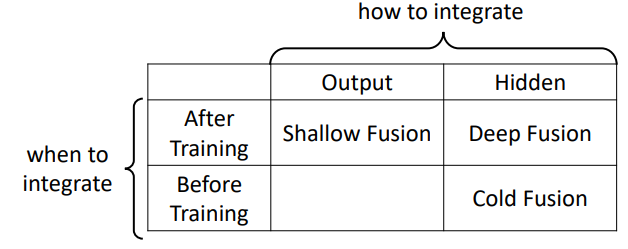
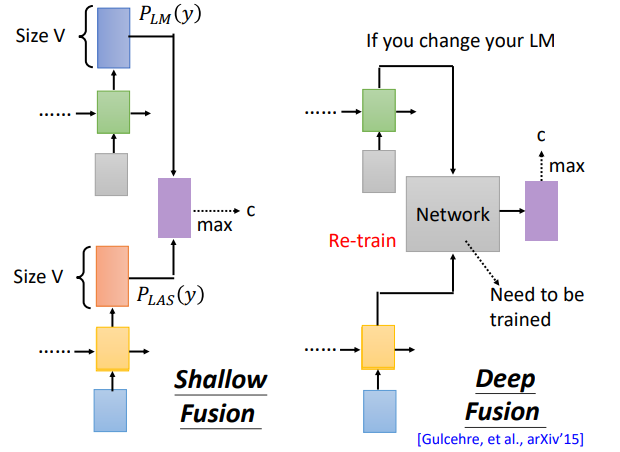
先说几个整合方法怎么做:
- shallow fusion
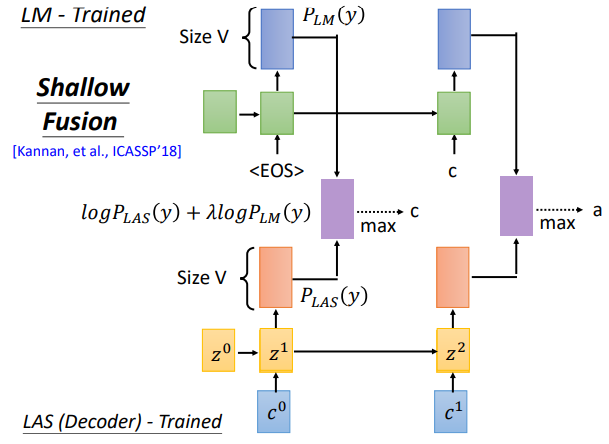
分别训练LM和LAS,训练好后将各自的**输出**接到一起,整合
- deep fusion
分别训练LM和LAS,训练好后将各自的**隐层**接到一起,整合
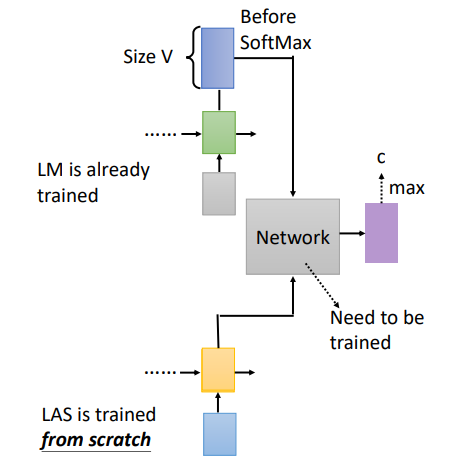
- cold fusion
先训练LM,再将LM的隐层接到LAS进行训练
#### Shallow Fusion
### Deep Fusion
隐层被接到一起,在训练一个Network进行输出
将隐层接到一起的缺点在于:如果LM改变了,network需要重新训练
### Cold Fusion
由于LM已经被训练号,LM的收敛会比较快
缺点在于:如果LM改变了,network需要重新训练
这节课就到这里了,下节课我们将学习语音合成。
references:
http://speech.ee.ntu.edu.tw/~tlkagk/courses_DLHLP20.html

