import tensorflow as tf
from tensorflow.keras import layers, optimizers, datasets, Sequential
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
tf.random.set_seed(2345)
conv_layers = [ # 5 units of conv + max pooling
# unit 1
layers.Conv2D(64, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(64, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 2
layers.Conv2D(128, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(128, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 3
layers.Conv2D(256, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(256, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 4
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 5
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same')
]
def preprocess(x, y):
# [0~1]
x = tf.cast(x, dtype=tf.float32) / 255.
y = tf.cast(y, dtype=tf.int32)
return x,y
(x,y), (x_test, y_test) = datasets.cifar100.load_data()
y = tf.squeeze(y, axis=1)
y_test = tf.squeeze(y_test, axis=1)
print(x.shape, y.shape, x_test.shape, y_test.shape)
train_db = tf.data.Dataset.from_tensor_slices((x,y))
train_db = train_db.shuffle(1000).map(preprocess).batch(128)
test_db = tf.data.Dataset.from_tensor_slices((x_test,y_test))
test_db = test_db.map(preprocess).batch(64)
sample = next(iter(train_db))
print('sample:', sample[0].shape, sample[1].shape,
tf.reduce_min(sample[0]), tf.reduce_max(sample[0]))
def main():
# [b, 32, 32, 3] => [b, 1, 1, 512]
conv_net = Sequential(conv_layers)
fc_net = Sequential([
layers.Dense(256, activation=tf.nn.relu),
layers.Dense(128, activation=tf.nn.relu),
layers.Dense(100, activation=None),
])
conv_net.build(input_shape=[None, 32, 32, 3])
fc_net.build(input_shape=[None, 512])
optimizer = optimizers.Adam(lr=1e-4)
# [1, 2] + [3, 4] => [1, 2, 3, 4]
variables = conv_net.trainable_variables + fc_net.trainable_variables
for epoch in range(50):
for step, (x,y) in enumerate(train_db):
with tf.GradientTape() as tape:
# [b, 32, 32, 3] => [b, 1, 1, 512]
out = conv_net(x)
# flatten, => [b, 512]
out = tf.reshape(out, [-1, 512])
# [b, 512] => [b, 100]
logits = fc_net(out)
# [b] => [b, 100]
y_onehot = tf.one_hot(y, depth=100)
# compute loss
loss = tf.losses.categorical_crossentropy(y_onehot, logits, from_logits=True)
loss = tf.reduce_mean(loss)
grads = tape.gradient(loss, variables)
optimizer.apply_gradients(zip(grads, variables))
if step %100 == 0:
print(epoch, step, 'loss:', float(loss))
total_num = 0
total_correct = 0
for x,y in test_db:
out = conv_net(x)
out = tf.reshape(out, [-1, 512])
logits = fc_net(out)
prob = tf.nn.softmax(logits, axis=1)
pred = tf.argmax(prob, axis=1)
pred = tf.cast(pred, dtype=tf.int32)
correct = tf.cast(tf.equal(pred, y), dtype=tf.int32)
correct = tf.reduce_sum(correct)
total_num += x.shape[0]
total_correct += int(correct)
acc = total_correct / total_num
print(epoch, 'acc:', acc)
if __name__ == '__main__':
main()
通过一个图像分类问题介绍卷积神经网络是如何工作的。下面是卷积神经网络判断一个图片是否包含“儿童”的过程,包括四个步骤:
● 图像输入(InputImage)
● 卷积(Convolution)
● 最大池化(MaxPooling)
● 全连接神经网络(Fully-ConnectedNeural Network)计算。
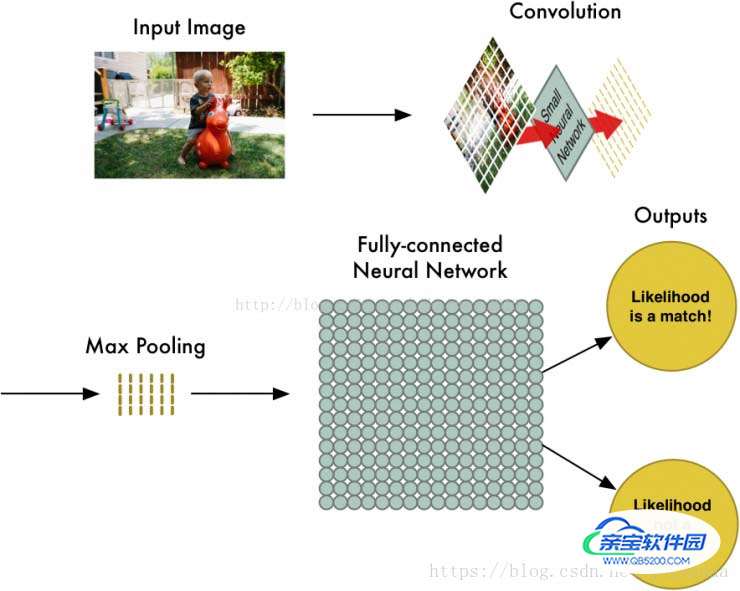
首先将图片分割成如下图的重叠的独立小块;下图中,这张照片被分割成了77张大小相同的小图片。

接下来将每一个独立小块输入小的神经网络;这个小的神经网络已经被训练用来判断一个图片是否属于“儿童”类别,它输出的是一个特征数组。

标准的数码相机有红、绿、蓝三个通道(Channels),每一种颜色的像素值在0-255之间,构成三个堆叠的二维矩阵;灰度图像则只有一个通道,可以用一个二维矩阵来表示。
将所有的独立小块输入小的神经网络后,再将每一个输出的特征数组按照第一步时77个独立小块的相对位置做排布,得到一个新数组。

第二步中,这个小的神经网络对这77张大小相同的小图片都进行同样的计算,也称权重共享(SharedWeights)。
这样做是因为,第一,对图像等数组数据来说,局部数组的值经常是高度相关的,可以形成容易被探测到的独特的局部特征;第二,图像和其它信号的局部统计特征与其位置是不太相关的,如果特征图能在图片的一个部分出现,也能出现在任何地方。
所以不同位置的单元共享同样的权重,并在数组的不同部分探测相同的模式。
数学上,这种由一个特征图执行的过滤操作是一个离散的卷积,卷积神经网络由此得名。
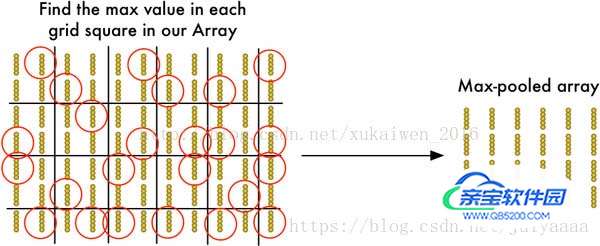
卷积步骤完成后,再使用MaxPooling算法来缩减像素采样数组,按照2×2来分割特征矩阵,分出的每一个网格中只保留最大值数组,丢弃其它数组,得到最大池化数组(Max-PooledArray)。
接下来将最大池化数组作为另一个神经网络的输入,这个全连接神经网络会最终计算出此图是否符合预期的判断。
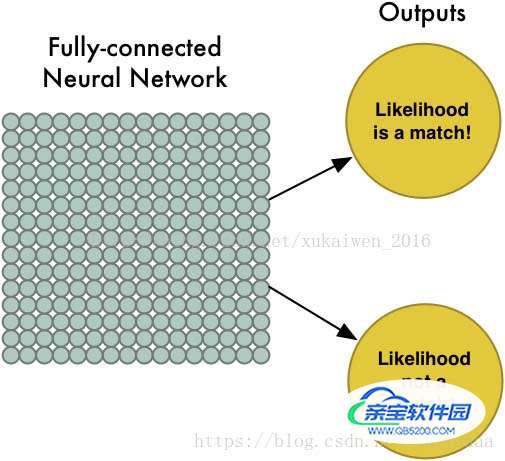
在实际应用时,卷积、最大池化和全连接神经网络计算,这几步中的每一步都可以多次重复进行,总思路是将大图片不断压缩,直到输出单一的值。使用更多卷积步骤,神经网络就可以处理和学习更多的特征。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。

