注意:cdh6.3.2的spark为2.4.0但是使用2.4.0本地pyspark有bug,下载的文件可能在第一次解压缩后,如未出现目录,则需要修改文件后缀为zip,再次解压缩
spark2.4.x不支持python3.7以上版本
conda create -n pyspark2.4 python=3.7 activate pyspark2.4 pip install py4j pip install psutil
pyspark安装方法(推荐一)
以下只是示例,根据实际情况修改,路径不要有空格,如果有使用mklink /J 软链接 目录路径
系统变量添加 HADOOP_HOME E:\bigdata\ENV\hadoop-3.0.0 SPARK_HOME E:\bigdata\ENV\spark-2.4.4-bin-without-hadoop PYSPARK_PYTHON C:\Users\zakza\anaconda3\envs\pyspark2.4\python.exe PATH添加 %HADOOP_HOME%\bin %SPARK_HOME%\bin
配置一 %SPARK_HOME%\conf目录下新建spark-env.cmd文件,内容如下
FOR /F %%i IN ('hadoop classpath') DO @set SPARK_DIST_CLASSPATH=%%i配置二 %SPARK_HOME%\conf\目录下新建log4j.properties文件,内容如下
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# Set everything to be logged to the console
log4j.rootCategory=WARN, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
# Set the default spark-shell log level to WARN. When running the spark-shell, the
# log level for this class is used to overwrite the root logger's log level, so that
# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=WARN
# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=WARN
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=INFO
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=INFO
log4j.logger.org.apache.parquet=ERROR
log4j.logger.parquet=ERROR
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR注意:配置好环境变量重启下电脑,不然可能存在pycharm无法加载系统环境变量的情况
wc.txt
hello hadoop hadoop spark python flink storm spark master slave first second thrid kafka scikit-learn flume hive spark-streaming hbase
wordcount测试代码
from pyspark import SparkContext
if __name__ == '__main__':
sc = SparkContext('local', 'WordCount')
textFile = sc.textFile("wc.txt")
wordCount = textFile.flatMap(lambda line: line.split(" ")).map(lambda word: (word, 1)).reduceByKey(
lambda a, b: a + b)
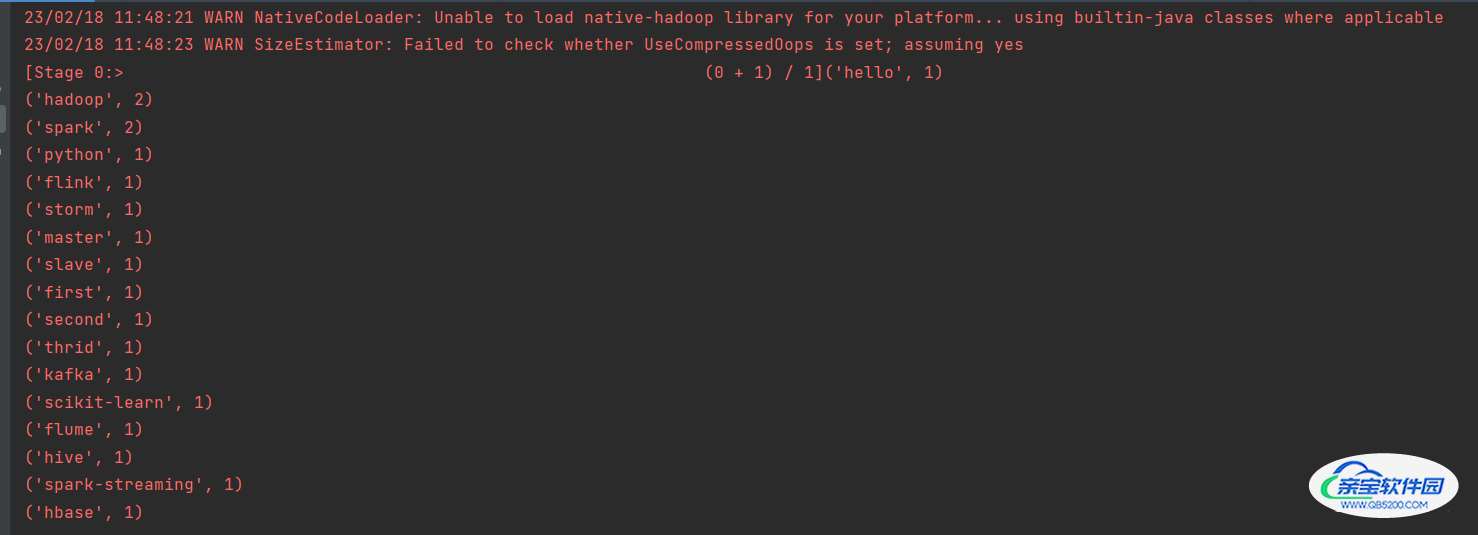
wordCount.foreach(print)正常运行结果:
spark-shell报错Caused by: java.lang.ClassNotFoundException: org.slf4j.Logger
解决方法:见上述配置一
Pyspark报错ModuleNotFoundError: No module named 'resource'
解决方法:spark2.4.0存在的bug,使用spark2.4.4
Pyspark报错org.apache.spark.sparkexception: python worker failed to connect back
解决方法:环境变量未配置正确,检查是否遗漏,并检查pycharm的configuration的环境变量里面能够看到
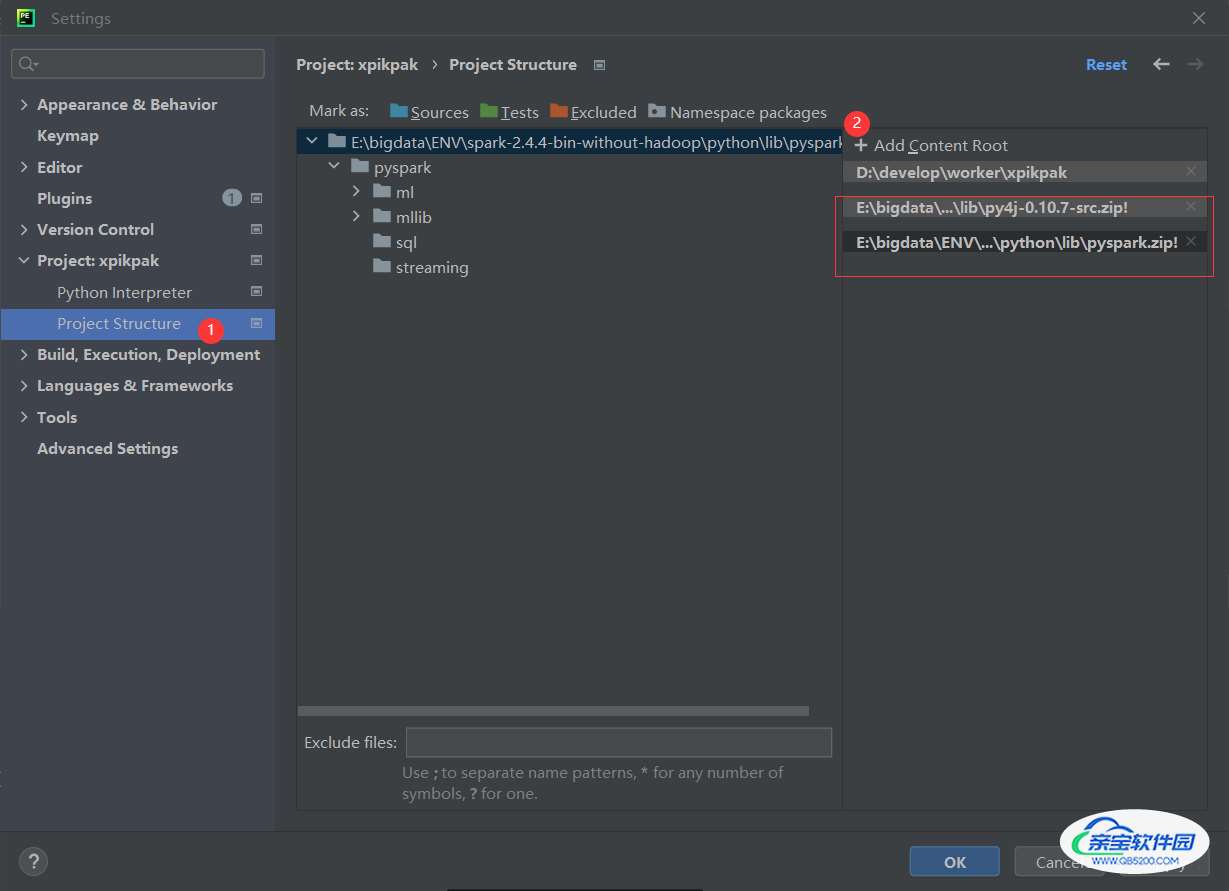
关于%SPARK_HOME%\python\lib下的py4j-0.10.7-src.zip,pyspark.zip(未配置运行正常),也可以尝试添加到项目