import pandas as pd
import numpy as np
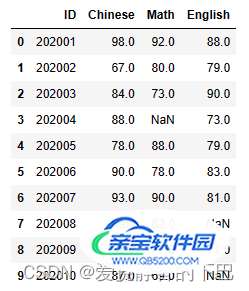
data = {"ID":[202001, 202002, 202003, 202004, 202005, 202006, 202007, 202008, 202009, 202010],
"Chinese":[98, 67, 84, 88, 78, 90, 93, np.nan, 82, 87],
"Math":[92, 80, 73, np.nan, 88, 78, 90, 82, 77, 69],
"English":[88, 79, 90, 73, 79, 83, 81, np.nan, 71, np.nan]
}
df = pd.DataFrame(data)
df
df.isnull().values.any()
True
df.isnull().sum().any()
True
df.isnull().sum()

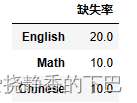
all_data_na = (df.isnull().sum()/len(df))*100
all_data_na = all_data_na.drop(all_data_na[all_data_na == 0].index).sort_values(ascending=False)
missing_data = pd.DataFrame({'缺失率' : all_data_na})
missing_data
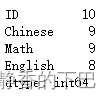
df.info()

df.shape[0] - df.isnull().sum()
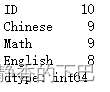
df.notnull().sum()
# 用上下平均值填充English df['English'] = df['English'].fillna(df['English'].interpolate()) df.head(10)
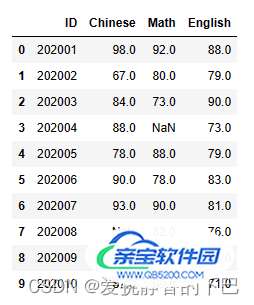
# 用中位数填充value列: df['Math'] = df['Math'].fillna(df['Math'].median()) df.head(10)
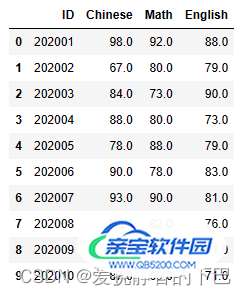
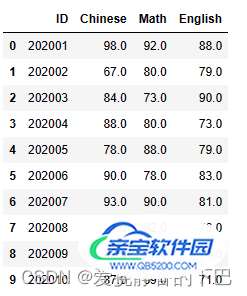
# 用-1填充Chinese列: df['Chinese'] = df['Chinese'].fillna(-1) df.head(10)
到此这篇关于pandas检查和填充缺失值的N种方法总结的文章就介绍到这了,更多相关pandas检查和填充缺失值内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!

